HWL News Bot
News
Thread Starter
- Mitglied seit
- 06.03.2017
- Beiträge
- 114.871
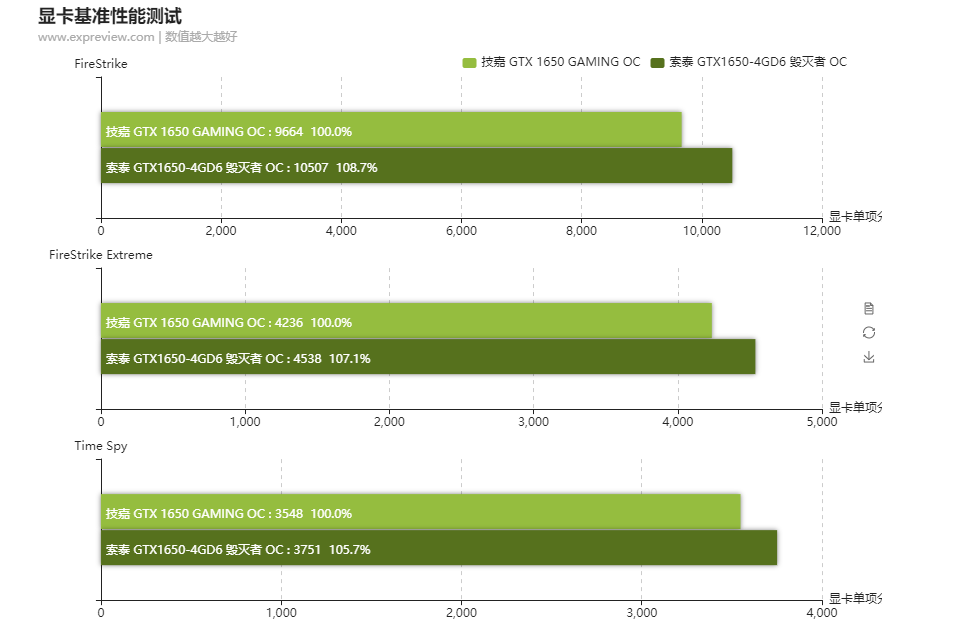
Neben der GPU selbst bestimmt einerseits der Standard des GPU-Speichers, die Menge und zusätzlich auch deren Anbindung die Performance einer Grafikkarte. In den technischen Eigenschaften zu den verschiedenen Grafikkarten-Modellen liest man, dass der VRAM entweder mit 128, 192, 256 oder gar 384 Bit angebunden ist und gleichzeitig eine entsprechende Speicherbandbreite bereitstellen kann, die eine wichtige Rolle bei grafikintensiven Anwendungen und gerade in höheren Auflösungen spielt. Doch was bedeutet das im Detail und wie wird der Speicher auf dem Grafikkarten-PCB angebunden? Wie wird die Speicherbandbreite berechnet? Diese durchaus berechtigten Fragen wollen wir gerne für unsere Leser einmal im Detail erklären.
... weiterlesen
... weiterlesen


")

")
 .
.")