Wie funktioniert alte Kamellen -wie Half Life 1- auf Kepler, Maxwell, GCN oder sogar den APUs? Wie kann es sein, dass alte Spiele, die noch nie etwas von der GTX 970 gehört haben keine Probleme mit den 3,5GB bekommen? Ganz einfach der Treiber, den vergisst du in deiner ganzen Herangehensweise. Es wird kein Programierer her gehen und ein Spiel für GCN entwickeln, damit es mit der nächsten Generation nicht mehr funktioniert, dieses Problem hatten wir vor DirectX schon einmal, als jeder Hersteller sein eigenes Süppchen gekocht hat.
Was du als Programmierer machst, ist das werkeln mit Schnittstellen wie DirectX, Mantle, OpenGL oder Vulkan. Diese haben aber keinen direkten Hardwarezugriff, hier werkelt immernoch der Treiber zwischen drin und der kümmert sich entsprechend auch um die Spiercherverwaltung. Mag sein, dass letzteres mit DX12 mehr in in die Verantwortung der Spieleentwickler rückt, aber dass man die volle Speicherkontrolle hat und braucht, halte ich eher für unwahrscheinlich.
Aber damit hast du doch den Finger genau auf der Wunde? Weder die alte Kamelle ala HL1 noch aktuelle Spiele sind direkt auf Hardwareebene hin programmiert. Man bedient sich Schnittstellen und Abstraktionsschichten, damit eben genau das NICHT notwendig ist. Hier ergeben sich aber eben doch genau die Herrausforderungen, wenn eine Hardware nun möglicherweise "aus der Reihe" tanzt...
Lass es mich mal vielleicht anhand eines Beispiels erklären. Nimm dir einen Hypervisor als Virtualisierungslösung. Du kannst darin Betriebssysteme von anno dazumal virtualisieren, wie auch heutige neue Versionen. Ein OS von sonstwie alt wird kein HDD Caching im RAM betreiben. Ein neues OS aber wird dies tun. Das hat den positiven Effekt, dass ungenutzte RAM Ressourcen IN der VM für das Caching Storagezugriffe verwendet werden. Hier ergibt sich allerdings eine Problemstellung, wenn du dem Hypervisor den RAM Überbuchst. Wenn du bei zwei VMs sagen wir 1GB Rohkapazität an RAM benötigst, das OS aber von den zugeteilten virtuellen 4GB zusätzlich 3GB fürs HDD Caching nutzt wäre ein Host mit 8GB RAM voll belegt. Nun die Frage: Woher weis diese zusätzliche Abstraktionsschicht in Form des Hypervisors, welche Daten potentiell ausgelagert werden können? -> es würde sich anbieten, Daten des HDD Caches dafür zu nutzen respektive den Cache absolut zu verringern. Es wäre aber Fatal für die Performance, wenn es die Rohdaten der laufenden Software wäre.
-> aktuell sind bspw. die Hypervisorlösungen dazu nur bedingt in der Lage, dies zu können. Somit ergibt sich das Problem, dass bei RAM Knappheit die Performance in den Keller geht.
Im hierigen Fall ist das doch ziemlich ähnlich, weshalb, wie ich denke, das Beispiel durchaus passend ist. Der Treiber WEIS nicht direkt, welche Daten was beinhalten. Es wäre also auch ziemlich fatal die falschen Daten aus dem Cache aka schnellen HBM Speicher zu schieben. Wie löst du nun das Problem? An was machst du fest, was für Daten wo stehen, wenn es dir (also dem Treiber) nicht explizit mitgeteilt wird? -> eine Programmierung direkt auf eine Hardware, so hast du selbst festgestellt, wird nicht stattfinden... Also wie das Thema lösen? Das ist doch genau meine Frage.
Der VRAM dient ja auch nur dazu um 3D Objekte und Texturen zu speichern

. Bei der Berechnung fallen zB. auch temporären Zwischenergebnisse, Framebuffer und der gleichen an, die vermutlich deutlich mehr Bandbreite "verbrauchen" als das laden einzelner Texturen.
Und bezüglich man gibt beim laden von Objekten keine Speicheradresssen an, dir ist hoffentlich klar, dass dein Objekt nur ein Label für eine Speicheradresse ist. Und du dieses sowohl als Wert als auch als Adresse übergeben kannst (pass by value/reference) und damit bestimmt wird, ob eine Arbeitskopie erstellt wird oder eben nicht. Aber das sollte dir eigentlich bewusst sein, verdienst du meines Wissens nach damit doch dein Geld
")
Zum ersten, das sagte ich oben bereits. Der Bandbreitenbedarf reiner Texturdaten ist wohl vergleichsweise "gering", wie die Relation aber genau ist, ist aktuell unbekannt... Und dazu von Spiel/Settings und Szene abhängig. Aber wie gesagt, das ist nicht primär die Herrausforderung, sondern eher, wie erkennst du bzw. an was machst du fest, was nun in welchem Speicher stehen muss und was nicht?
Und zum zweiten, natürlich ist mir das klar. Aber wo wird bitte bei "by ref/value" eine Speicheradresse mitgeben? Es geht nicht darum, mit der Speicheradresse oder einer Kopie davon zu arbeiten (sprich dass ein Zeiger unter der Haube auf die Adresse zeigt oder sich eine Kopie davon holt), sondern es geht explizit UM die Adresse. Schnapp dir ein Assembler und lade deine Objekte explizit IN eine definierte Speicheraddresse -> wie machst du das in Hochsprachen, die explizit genau solche tiefen Eingreiffe entweder gar nicht haben oder wo durch Abstraktionsschichten der Eingriff nicht soweit runter möglich ist? Wenn 1GB HBM Speicher und sagen wir xGB DDR4 bereit stehen, dann wird es entweder zwei völlig verschiedene Adresspools geben (physische Speicheradressen) oder man mappt die Speicher in einen virtuellen Pool. Wenn du aber nicht angibst, dass Objekt xyz nun in 0x irgendwas liegt, wie willst du dann steuern, in welchem physischen Speicher das Objekt liegt? Und natürlich wird hier der Treiber involviert sein. Aber genau das WIE ist die Frage, die sich mir stellt. Denn der Treiber kann prinzipbedingt nicht wissen, was ich als nächstes mache, ebenso wenig wie er prinzipbedingt nicht weis, was wirklich wichtig ist und was nicht. Wäre das der Fall, würde ein VRAM Limit auf dGPUs doch gar nicht stattfinden. Denn dann wüsste der Treiber vorher schon, was ich als nächstes mache und kann entsprechend agieren um die richtigen Daten in den VRAM zu blasen...
Meines Wissens nach ist das aktuell in Spielen/Engines eine Kombo zwischen Treiber und Spiel. Sprich wir verwenden mittlerweile Verfahren zum Streamen der oftmals dynamischen Welt. Das heist, das Spiel selbst "streamt" in gewissen Radien um Sichtbereich oder ähnlich definierten Zuständen die Datenmenge, die benötigt werden und "leert" explizit aber auch eben gewisse "Altdaten" wieder durch Flushbefehler oder ähnlichem. Der Treiber ist dahingehen dann involviert um den Spaß umzusetzen. Auffallend ist, Spiele, welche explizit NICHT ins VRAM Limit laufen, zeigen idR entweder eine stetig steigende VRAM Belastung oder ein leichtes hin und her. Näherst du dich dem Limit, dann kommt das System an seine Grenzen. Nämlich weil Daten umgeschaufelt werden müssen, die womöglich schon im nächsten Augenblick wieder notwendig sind. Das gibt Nachladeruckler aufgrund von "falschen" Daten im localen VRAM.
-> Die Herrausforderung hier ist doch nun, wenn man schnellen, dafür kleinen Speicher hat, muss man explizit die Daten richtig konsolidieren. Bei dGPUs wie aktuellen APUs gibts das doch so nicht. Da ist der gemappte Speicher einfach so wie er ist. Schnell und idR gleich über den ganzen Bereich... Eine GTX 970 oder Kepler/Fermi GPUs mit diesem komischen VRAM Anbindung zeigen in Titeln bei zu viel Datenverbrauch komische Verhaltensmuster -> weil es eben dem Treiber NICHT möglich ist, da so richtig sauber zu arbeiten.
Mit zwei unterschiedlichen VRAM Pools bei lokalem HBM wären die Vorzeichen zumindest ähnlich... Es sei denn, man löst es eben anders. Bspw. den HBM als reinen "Cache" vor den eigentlichen VRAM zu schalten und jegliche Daten durchlaufen diesen. Dann müsste aber (sofern ich in der Überlegung keinen Denkfehler habe) eben der HBM nicht an der GPU sondern irgendwo zwischen GPU und CPU (wohl an der integrierten Northbridge) hängen sowie entsprechend Bandbreite bereit stehen (Onion3)
Mir ist durchaus bewusst, dass gewisse "Teile" der GPU dediziert Adressen in Reservierung haben. -> dort kann man auch ein 1:1 mapping auf die physische Adresen vornehmen. Der Bereich variabler Größe, der von Texturen und anderem Sonderkram belegt wird, sieht da aber schon anders aus... Wie oben schon glaube ich 2x erwähnt ist aber genau das Zeug eben das, was den Platz wegfrisst. Der reine Workingbereich ohne jegliche Texturen und Co. ist im Vergleich recht gering. Er skaliert mit der Auflösung, du brauchst bisschen Platz für die Framebuffer usw. Aber "viel" ist das nicht... Mit Texturen kannst du aber spielend GB-große Speicherbereiche füllen. Und es ist einzig und allein die Frage, was davon brauchst du wirklich effektiv und was davon ist nur "Cache" für mögliche nächste Zugriffe und wie machst du das fest. -> eben eine technische Betrachtung. Die Frage mit "der Treiber" abzutun kommt dem irgendwie nicht sonderlich nahe

gehen die Argumente oder das Wissen aus, zückt man schnell die Fanboy-Karte...

Sag das bitte why_me oder John, siehe ihre Beiträge weiter oben... Offensichtlich haben diese beiden Typen ein "Problem" im Versuch einer Erörterung von der möglichen technischen Umsetzung... Ich muss mich bestimmt nicht hier von derartigen Leuten anflaumen lassen, noch dazu sind meine Argumente völlig wertungsfrei ggü. dem Hersteller zu sehen. Da ist nichtmal Kritik enthalten... Aber muss man das explizit dazuschreiben, wenn die bekannten Personen hier es sowieso nicht glauben (wollen und werden)?? Das mein ich damit. Wenn kein Interesse besteht, hier zu debattieren/zu spekulieren, dann muss ich das sicher nicht hier tun. Denn mit irgenwelchen Leuten, die meinen einen PC verstanden zu haben, weil sie offenbar schonmal ein Smartphone eingeschaltet haben über technische Umsetzungen zu debattieren, ist irgendwie sinnfrei und führt zu nix... (das ist/war jetzt nicht primär auf Dich bezogen! Also bitte nicht falsch verstehen, aber mir geht diese Fanboykacke gewaltig auf den Keks...)



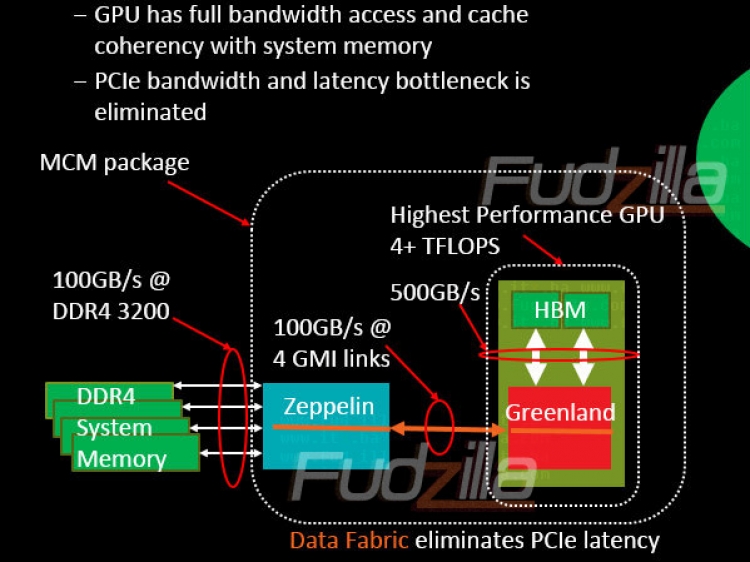
 Alles was mit AMD nur im entferntesten zu tun hat, scheint hier ein rotes Tuch zu sein. Das war früher definitiv auch mal anders...
Alles was mit AMD nur im entferntesten zu tun hat, scheint hier ein rotes Tuch zu sein. Das war früher definitiv auch mal anders... 