
Werbung
Dame, Schach und andere "einfache" Brettspiele sind für einen Computer längst keine Herausforderungen mehr. Die letzte Bastion war das chinesische Go, ein strategisches Brettspiel für zwei Spieler. In Duellen zwischen Menschen und künstlichen Intelligenzen wurden die menschlichen Spieler mit einem Handicap versehen, damit es überhaupt zu einem gleichwertigen Kampf werden konnte. Doch nun scheint auch diese letzte Bastion gefallen zu sein.
Bereits im Oktober 2015 schlug die künstliche Intelligenz von Google namens AlphaGo den Profi-Spieler Fan Hui – nicht nur einmal, sondern gleich in fünf aufeinanderfolgenden Matches. Warum es trotz immer schnellerer Rechner jedoch relativ lange gedauert hat, bis ein Computer den Menschen besiegen konnte, erklärt die Komplexität des Spiels. Während zum Beispiel Schach pro Position, Zug und Spielfigur 20 Möglichkeiten bietet, sind es bei Go 200 mögliche Züge. Die Anzahl der möglichen Konfigurationen eines Go-Boards übersteigt sogar die Anzahl der Atome im Universum. Genauer gesagt handelt es sich um 2,08 × 10170 mögliche Positionen – eine schier unglaublich große Zahl.
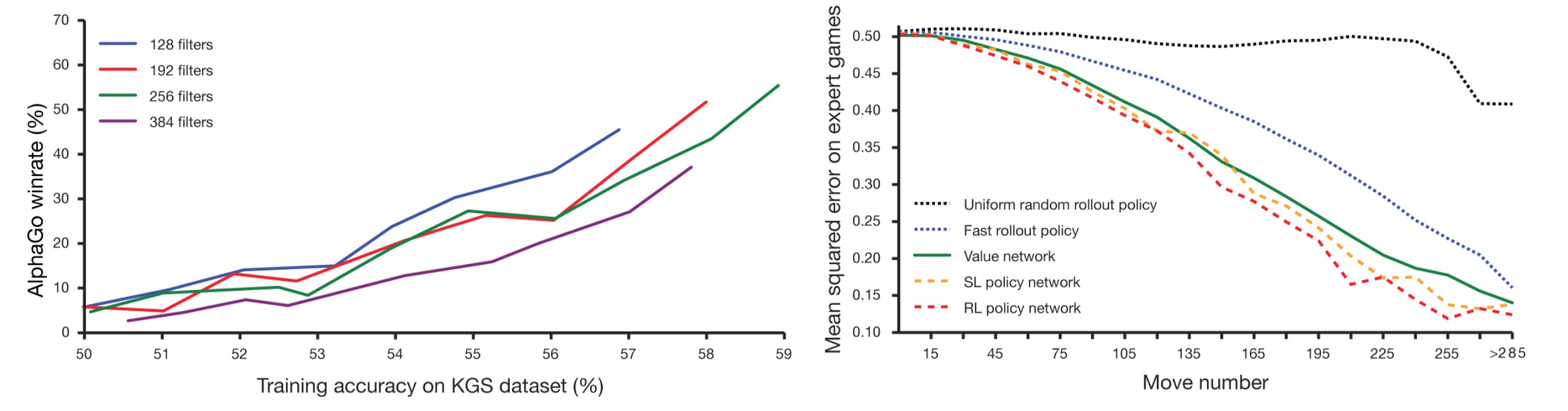
Nun könnte man anhand der aktuellen Rechenleistung vermuten, dass zumindest Supercomputer in der Lage sein sollten, eine derart komplexe Aufgabe zu bewältigen. Doch nicht nur die schiere Anzahl an Möglichkeiten und Kombinationen sind eine Herausforderung, sondern diese müssen auch bewertet werden, um den möglichst besten Zug machen zu können. Ein Durchbruch ist dabei die Monte-Carlo Tree Search (MCTS). Dabei werden möglichst viele Züge aus der aktuellen Stellung heraus simuliert und per Zufallszüge zu Ende gespielt. Im Falle von Go wird in der Folge bewertet, welche Farbe (weiß oder schwarz) häufiger gewinnt und diese hat dann offenbar die bessere Stellung. Eben dieses Wissen um die eigene Stellung ist ein wichtiger Punkt, um weitere Züge planen zu können. Hier kommen dann auch vordefinierte Züge zum Einsatz, die aus früheren Spielen, Eröffnungsbibliotheken und Musterdatenbanken gewonnen werden.

Google hat das Unternehmen DeepMind vor zwei Jahren übernommen. Das dort entwickelte Programm AlphaGo verwendet zwei neuronale Netzwerke, um seine Züge zu planen. Das Policy Network sortiert aus den 200 Möglichkeiten aus einer Stellung die sinnvollsten Züge heraus, so dass nicht mehr nur 200, sondern deutlich weniger Züge bewertet werden müssen. Das Value Network bewertet daraufhin aus der Auswahl die besten Gewinnmöglichkeiten. All das wird in einer MCTS kombiniert und wählt den letztendlichen Zug aus. Nach einem Training mit über 30 Millionen Zügen durch menschliche Spieler wurde ein Deep-Learning-Netzwerk aufgebaut, dass gegen sich selbst spielte und so dazulernte. Dieses Deep-Learning-Netzwerk trainierte sich auf 50 GPUs selbst, die eine Woche daran arbeiteten.
Ob nun Mensch oder Computer der bessere Go-Spieler ist, soll in naher Zukunft abschließend festgestellt werden. Der wohl weltstärkste Go-Spieler Lee Sedol will im März im koreanischen Seoul gegen AlphaGo antreten.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
