
Werbung
Auf der GTC 2012 präsentierte NVIDIA den GK110, die zweite Iteration von "Kepler", die gegen Ende 2012 als Tesla K20 zunächst im professionellen Bereich zum Einsatz kommen soll. Mit den SMX-Clustern hat NVIDIA das Verhältnis von Cores zur Control-Logic deutlich zugunsten der Recheneinheiten gewendet. Zudem setzt man auf eine neue Gewichtung was das Verhältnis der Cores zum Takt und der Control-Logic betrifft - die sogenannten "Hotclocks" sind schlichtweg nicht mehr nötig, um eine hohe Rechenleistung zu erlangen. Neben den Optimierungen im SMX-Cluster hat NVIDIA aber auch zwei neue Technologien genannt, die GK110 vorbehalten sind und bei GK104 nicht zum Einsatz kommen. Doch worum handelt es sich bei Hyper-Q und Dynamic Parallelism genau?
Hyper-Q:
Während die "Fermi"-GPUs nur über eine Work Qeue mit neuen Befehlen und Daten versorgt werden konnten, soll dies mit "Kepler" nun anders sein.

32 physikalische CPU-Kerne können nun gleichzeitig eine "Kepler"-GPU ansteuern. Natürlich ist diese Limitierung auf Softwareebene in Schnittstellen wie DirectX 11 nicht vorhanden und hier können auch mehrere Threads gleichzeitig ausgeführt werden, die Übergabe der Daten und Befehle aber erfolgte weiterhin seriell. Parallele Daten sollen nun zukünftig aber auch parallel übergeben werden können.
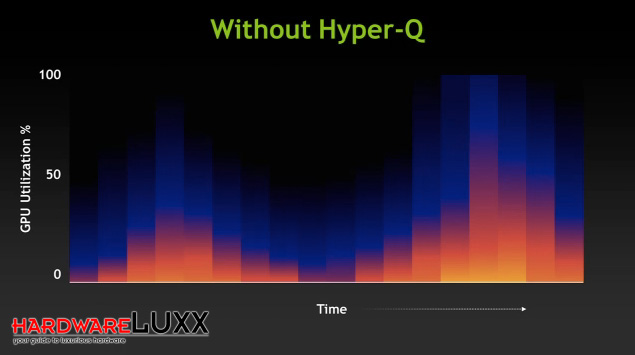
Ohne Hyper-Q werden die Daten und Befehle seriell übertragen, was dazu führen kann, dass die Auslastung der GPU nicht optimal ist.

Mit Hyper-Q können die Daten und Befehle von 32 physikalischen Kernen gleichzeitig übertragen werden. Somit ist die Auslastung der GPU nicht nur besser, sondern die anfallenden Berechnungen können auch schneller abgearbeitet werden.
Natürlich ist es nun auch möglich, dass mehrere GPUs direkt miteinander kommunizieren. "GPU Direct" verbindet die "Kepler"-GPUs über das Netzwerk miteinander - der Umweg über die CPU und deren Arbeitsspeicher ist nicht mehr notwendig.
Dynamic Parallelism:
Befehle und Daten, die an die GPU geliefert werden, können verschachtelt aufgebaut sein (beispielsweise wenn Berechnungen von den Ergebnissen anderer Berechnungen abhängig sind) und somit die verschiedenen Threads der GPU über eine bestimmte Laufzeit blockieren. NVIDIA versuchte dem über Optimierungen in der CUDA-Schnittstelle entgegen zu wirken.
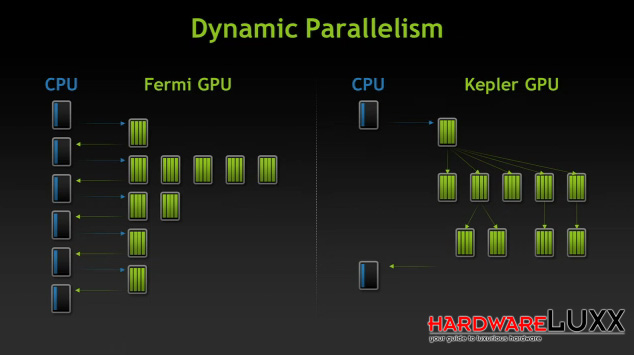
Mit dem Dynamic Parallelism kann die GPU selbst diese Verschachtelungen auflösen. Dies sorgt allerdings auch für etwas mehr Programmieraufwand, denn der Programmierer muss nun beachten, dass die GPU sich nicht selbst den Speicher volllaufen lässt. Sollte es dazu kommen, dass die selbst angelegten Threads den freien Speicher der GPU überschreiten, werden die Daten über die PCI-Express-Schnittstelle ausgelagert, was den gesamten Prozess wiederum verlangsamt.

Die GPU bestimmt dabei selbst, in wie weit sie die Verschachtelung zulässt. NVIDIA will und kann keine Raster vorgeben, da man damit auch die Leistung in ungünstigen Szenarien einschränkt.
Die genannten Punkte für Hyper-Q und Dynamic Parallelism sind natürlich nur für das GPU-Computung interessant. Spieler werden von diesen Technologien auch bei der GeForce-Version des GK110 nichts spüren. Dennoch ist es einmal mehr interessant zu sehen in welchen Bereichen NVIDIA für das Computing denkt und seine Produkte auch expliziet dahingehend auslegt.
