
Werbung
Es wird noch einige Monate dauern, bis uns der GK110 in Form der Tesla K20 erwarten wird, doch die GTC 2012 hat Erwartungen erweckt, die NVIDIA vielleicht gar nicht erfüllen kann. Wie stellt sich GK110 eigentlich im Vergleich zu GK104 der GeForce GTX 680 dar? Wo hat NVIDIA welche Änderungen vorgenommen? Neben der Tatsache, dass "Big Kepler" in der maximalen Ausbaustufe 2880 CUDA-Kerne und 7,1 Milliarden Transistoren besitzt, fehlt den meisten noch der Hintergrund zur Änderung innerhalb der Architektur. Eben diese wollen wir nun beleuchten.

Mit GK110 setzt NVIDIA zunächst voll auf den professionellen Markt und den Einsatz im HPC (High Performance Comuting). Tesla K10 auf Basis zweier GK104-GPUs ist nur eine erste Ausbaustufe von "Kepler" und wird den Erwartungen sicherlich auch nicht in allen Belangen gerecht werden. Dies liegt nicht zuletzt daran, dass NVIDIA GK104 in vielen Bereichen im Vergleich zu GF110/GF100 beschnitten hat. So ist die Speicherbandbreit von 384 Bit auf 256 Bit reduziert worden. Gleiches gilt für den L2-Cache, der von 768 kB auf 512 kB verkleinert wurde. Letztendlich sorgt die Neustrukturierung der CUDA-Kerne im SMX-Cluster auch dafür, dass das Verhältnis Double-Precision zu Single-Precision von 1/2 auf 1/24 reduziert wurde. Zu guter Letzt ist bei GK104 auch nur der Grafikspeicher ECC geschützt, nicht aber die Caches.

Tesla K10 auf Basis zweier GK104-GPUs
All diese Maßnahmen können dazu führen, dass Compute-Anwendungen bei GK104 langsamer berechnet werden können, als dies noch mit der "Fermi"-Generation der Fall war. Auf der anderen Seite aber gibt es spezielle Anwendungen, die von den Änderungen in GK104 profitieren. So ist die Single-Precision-Performance deutlich gestiegen und auch die Speicherbandbreite hat durch den schnellen Speichertakt einen Sprung gemacht. Nutzer müssen also abwägen, ob sie weiterhin mit den "Fermi"-Karten arbeiten wollen, oder bereits auf GK104 wechseln.
Kommen wir nun aber zu GK110. Das erste Produkt auf Basis der auf Compute-Performance optimierten GPU wird Tesla K20 sein. Sie soll im Oktober oder November diesen Jahres erscheinen. Mit GK110 stopft NVIDIA die Lücken, die man mit GK104 offen gelassen hat: ECC Fehlererkennungsverfahren, höhere Double-Precision-Performance, höhere Speicherbandbreite und mehr CUDA-Kerne.

Auch bei GK110 zum Einsatz kommen die SMX-Cluster, wie wir sie schon von GK104 kennen. Doch sie unterscheiden sich teilweise deutlich vom kleineren Bruder. In der maximalen Ausbaustufe von GK110 kommen 15 SMX-Cluster zum Einsatz, die über jeweils 192 CUDA-Kerne verfügen. Insgesamt verfügt GK110 also über 2880 CUDA-Kerne. Die 15 SMX-Cluster sind allesamt an einen 1,5 MB großen L2-Cache und ein 384 Bit breites Speicherinterface angebunden. In einem Interview bei Heise.de erklärten die beiden Köpfe hinter Kepler, warum man nicht gleich auf ein 512 Bit breites Speicherinterface setzen wollte. Mit 7,1 Milliarden Transistoren und einer Chipfläche von vermutlich etwa 600 mm² ist GK110 (GK104: 294 mm²) ohnehin schon der weltweit größte Chip (was die Transistoren betrifft) und auch in 28 nm nicht leicht zu fertigen und zudem teuer. Ein 512 Bit breites Speicherinterface hätte weitere Chipfläche in Beschlag genommen - letztendlich hat sich NVIDIA also zu einem Kompromiss entschlossen.
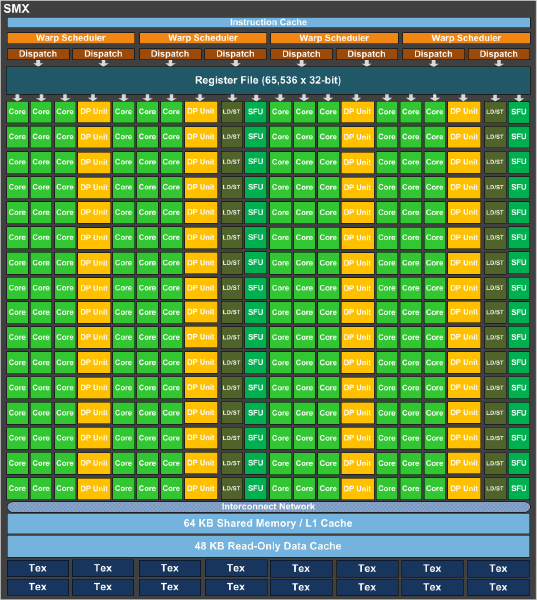
Um eine höhere Double-Precision-Performance zu erreichen hat NVIDIA pro SMX-Cluster nun 64 Floating-Point-Kerne eingebaut. Bei GK104 waren es nur acht pro Cluster. Zusammen mit der höheren Anzahl an Clustern sorgt dies für einen enormen Schub bei der Double-Precision-Performance. NVIDIA bleibt auch seiner skalaren Architektur bzw. der "Superscalar Dispatch Method" treu, die wir erstmals bei GF104 sahen und welche die Berechnungen etwas fehleranfälliger machen. Dadurch wird man etwas abhängiger von Thread Level Parallelism (TLP) und Instruction-Level Parallelism (ILP) / ganzzahlige lineare Optimierung.
Jedes SMX-Cluster verfügt außerdem über einen 64 kB großen L1-Cache und einen 48 kB Read-Only Data Cache. Im Vergleich zu GK104 hat man den L1-Cache also nicht angetastet, verpasst den Clustern in GK110 aber einen 48 kB großen Read-Only Data Cache. Pro SMX-Cluster bleibt es auch bei den 16 Textur-Einheiten, so dass GK110 derer maximal 240 besitzt.

Tesla K20 auf Basis von GK110
Die Double-Precision-Performance wird auch durch eine Änderung an den Registern erhöht. So ist die Anzahl der Register pro SMX-Cluster mit 65.536 im Vergleich zu GK104 identisch geblieben, dafür aber darf bei GK110 pro Thread auf 255 Register zugegriffen werden - bei GK104 sind es nur 63.
Bereits angesprochen haben wir das breitere Speicherinterface, dass sich aus sechs 64 Bit Blöcken zu einem insgesamt 384 Bit breiten Interface zusammensetzt. Anders als bei GK104 sind nun aber neben dem Grafikspeicher auch die L1- und L2-Caches ECC geschützt. Da eine Fehlererkennung auch immer einen gewissen Rechenaufwand bedeutet, hat NVIDIA diese Einbußen nach eigenen Angaben durch interne Optimierungen um bis zu 66 Prozent reduziert.
| GF110 | GK104 | GK110 | |
| Fertigung | 40 nm | 28 nm | 28 nm |
| Transistoren | 3 Milliarden | 3,54 Milliarden | 7,1 Milliarden |
| Die-Größe | 530 mm² | 294 mm² | etwa 600 mm² |
| TDP | 225 Watt | 225 Watt | - |
| GPU-Takt | 772 MHz | 1006 MHz | - |
| Speichertakt | 1000 MHz | 1502 MHz | - |
| Speichertyp | GDDR5 | GDDR5 | GDDR5 |
| Speichergröße | 1536 MB | 2048 MB | - |
| Speicherinterface | 384 Bit | 256 Bit | 384 Bit |
| Speicherbandbreite | 192 GB/Sek. | 192,2 GB/Sek. | - |
| Shadereinheiten | 512 (1D) | 1536 (1D) | 2880 (1D) |
| Textur Units | 64 | 128 | 240 |
| L1-Cache | 64 KB | 64 KB | 64 KB |
| L2-Cache | 768 KB | 512 KB | 1,5 MB |
| ECC | Speicher und Caches | nur Speicher | Speicher und Caches |
| FP64 | 1/2 FP32 | 1/24 FP32 | 1/3 FP32 |

GK110 Die
Hyper-Q und Dynamic Parallelism sind zwei weitere Punkte, die GK110 vorbehalten bleiben.
Hyper-Q:
Während die "Fermi"-GPUs nur über eine Work Qeue mit neuen Befehlen und Daten versorgt werden konnten, soll dies mit "Kepler" nun anders sein.

32 physikalische CPU-Kerne können nun gleichzeitig eine "Kepler"-GPU ansteuern. Natürlich ist diese Limitierung auf Softwareebene in Schnittstellen wie DirectX 11 nicht vorhanden und hier können auch mehrere Threads gleichzeitig ausgeführt werden, die Übergabe der Daten und Befehle aber erfolgte weiterhin seriell. Parallele Daten sollen nun zukünftig aber auch parallel übergeben werden können.
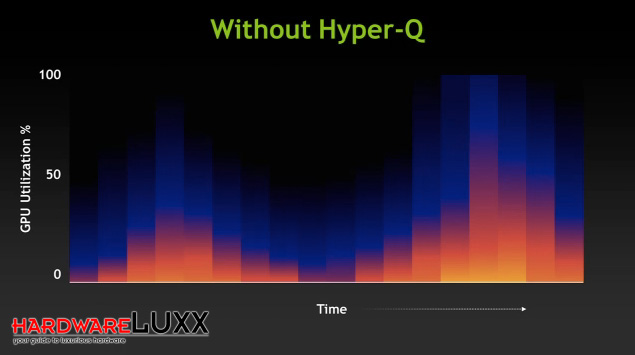
Ohne Hyper-Q werden die Daten und Befehle seriell übertragen, was dazu führen kann, dass die Auslastung der GPU nicht optimal ist.

Mit Hyper-Q können die Daten und Befehle von 32 physikalischen Kernen gleichzeitig übertragen werden. Somit ist die Auslastung der GPU nicht nur besser, sondern die anfallenden Berechnungen können auch schneller abgearbeitet werden.
Natürlich ist es nun auch möglich, dass mehrere GPUs direkt miteinander kommunizieren. "GPU Direct" verbindet die "Kepler"-GPUs über das Netzwerk miteinander - der Umweg über die CPU und deren Arbeitsspeicher ist nicht mehr notwendig.
Dynamic Parallism:
Befehle und Daten, die an die GPU geliefert werden, können verschachtelt aufgebaut sein (beispielsweise wenn Berechnungen von den Ergebnissen anderer Berechnungen abhängig sind) und somit die verschiedenen Threads der GPU über eine bestimmte Laufzeit blockieren. NVIDIA versuchte dem über Optimierungen in der CUDA-Schnittstelle entgegen zu wirken.
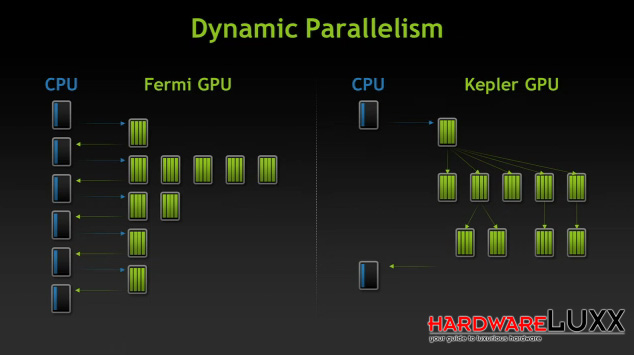
Mit dem Dynamic Parallism kann die GPU selbst diese Verschachtelungen auflösen. Dies sorgt allerdings auch für etwas mehr Programmieraufwand, denn der Programmierer muss nun beachten, dass die GPU sich nicht selbst den Speicher volllaufen lässt. Sollte es dazu kommen, dass die selbst angelegten Threads den freien Speicher der GPU überschreiten, werden die Daten über die PCI-Express-Schnittstelle ausgelagert, was den gesamten Prozess wiederum verlangsamt.

Die GPU bestimmt dabei selbst, in wie weit sie die Verschachtelung zulässt. NVIDIA will und kann keine Raster vorgeben, da man damit auch die Leistung in ungünstigen Szenarien einschränkt.
Fazit:
Nach all den Erklärungen rund um die Änderungen und Optimierungen der Architektur wollen wir auch versuchen die entscheidenden Fragen zu beantworten.
Was bringt GK110 dem Spieler an Vorteilen?
Mit GK110 konzentriert sich NVIDIA auf die Double-Precision-Performance - doch alleine schon aufgrund der enormen Anzahl an CUDA-Kernen wird sich auch die Single-Precision-Performance deutlich erhöhen. Diese spielt beim Image-Processing eine entscheidende Rolle und wird daher auch beim Rendering von Spielen zum Tragen kommen. In die gleiche Kerbe schlägt NVIDIA auch mit der höheren Anzahl an Textur-Einheiten. Auch davon wird die Gaming-Performance profitieren. Weniger interessant sind die Erhöhung der Double-Precision-Performance sowie der Support von ECC. Auch die Speicherbandbreite spielt eine weniger wichtige Rolle - wird aber natürlich im Falle von GK110 auch dankbar entgegen genommen.
Ein Vorteil des Ausbaus auf ein 384 Bit breites Speicherinterface dürfte die Tatsache sein, dass NVIDIA somit auch mindestens 3 GB Grafikspeicher einsetzen kann. Gerade bei hohen Auflösung und Super-Sampling-Settings können die aktuellen 2 GB zu einem Flaschenhals werden.
Es bleiben aber noch viele Fragen unbeantwortet. So befindet sich GK110 noch im Labor bei NVIDIA, hat sein erstes Tape-Out aber bereits hinter sich gebracht. Die finale Taktung der GPU wird man erst in den kommenden Monaten ermitteln. Zudem darf man sich die Frage stellen, zu welchen Bedingungen NVIDIA den GK110 bei TSMC wird fertigen können. Sicherlich wird man aber noch in den kommenden Monaten Fortschritte bei der Fertigung machen.
