
Werbung
Das Department of Energy (DoE) hat in den USA die Aufträge für zwei neue Supercomputer vergeben. Den Zuschlag bekommen haben IBM und NVIDIA und damit könnte NVLink auch erstmals in den Praxiseinsatz gelangen, denn beiden Unternehmen sind die wichtigsten Unterstützer einer neuen Interconnect-Technik für GPUs und CPUs. Zur Verfügung gestellt werden soll der Supercomputer namens Summit dem Oak Ridge National Laboratory und der zweite namans Sierra dem Lawrence Livermore National Laboratory. Erstmals vorgestellt wurde NVLink auf der GTC 2014 in diesem Jahr. Im Oktober gab IBM bekannt, dass NVLink ab 2016 in den ersten Servern zu finden sein wird.
An der Spitze der schnellsten Supercomputer hält sich seit einiger Zeit der Tianhe-2, der im National Super Computer Center in Guangzhou, China, steht. Auf dem 2. Platz der Top-500-Liste hat das DoE bereits einen Server des Oak Ridge National Laboratory stehen, will mit Summit aber wieder an die Spitze dieser Liste. Mit dem Aufbau begonnen werden soll 2016, fertiggestellt werden sollen Summit und Sierra aber erst 2017, womit auch die letztendlichen technischen Spezifikationen noch unklar sind. Einzig der Einsatz der dann aktuellen Tesla-Grafikkarten sowie der dazugehörigen IBM-Prozessoren ist sicher. Zwischen 150 und 300 petaFLOPS soll Summit erreichen, während für Sierra als Ersatz des IBM Blue Gene/Q im Lawrence Livermore National Laboratory (LLNL) 100 petaFLOPS anvisiert sind. Zum Vergleich: Der bereits angesprochene Tianhe-2, die aktuelle Nummer Eins bei den Supercomputern, kommt auf 33,8 petaFLOPS.
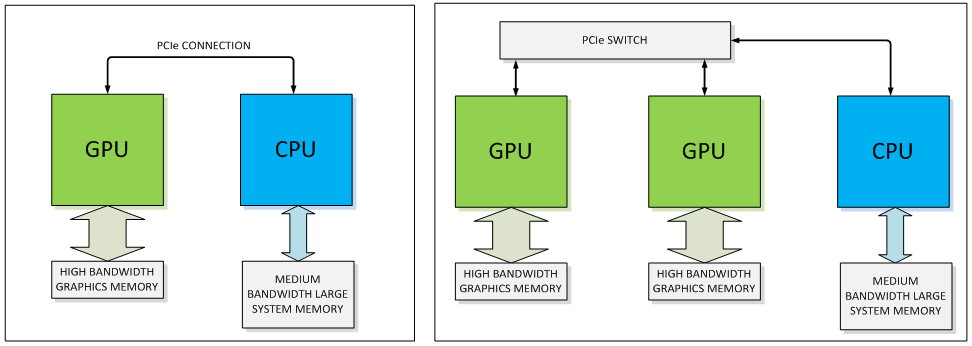
Warum Technologien wie NVLink immer wichtiger werden, macht die schiere Anzahl an Prozessoren und weiteren Beschleunigern deutlich. So sind in Tianhe-2 32.000 Intel Xeon E5-2692 12C mit 2,2 GHz verbaut. Hinzu kommen 48.000 Xeon-Phi-31S1P-Beschleunigerkarten. All diese Bauteile in kleinen und dann immer größeren Knoten miteinander zu verbinden, ist zu einer echten Herausforderung für die Entwickler eines solchen Supercomputers geworden. Für Systeme wie Summit und Sierra sowie weitere zukünftige Supercomputer dürften noch mehr Prozessoren und Beschleuniger zum Einsatz kommen, so dass die Kommunikation/Interconnects noch wichtiger werden.
Interconnects auf Basis von PCI-Express sind zum Flaschenhals geworden. Hier beträgt die Bandbreite in etwa 16 GB pro Sekunde. Zwischen dem Arbeitsspeicher und dem Prozessor sind es 60 GB pro Sekunde und moderne GPUs kommen über ein 512 Bit breites Speicherinterface auf über 300 GB pro Sekunde. Zwischen den Racks in solchen Supercomputern kommen häufig 40Gb-Ethernet-Adapter zum Einsatz, die bidirektional 40 GBit pro Sekunde erreichen sollen, in der Praxis aber für beide Kanäle auf 50 GBit pro Sekunde limitiert sind. Es wird als deutlich, wo die Engstelle in einem Knoten aus mehreren Prozessoren und Beschleunigern zu suchen ist.

NVLink ist eine direkte Punkt-zu-Punkt-Verbindung ein. Diese besteht wiederum aus jeweils acht Lanes pro NVLink-Verbindung. Pascal wird zunächst einmal vier NVLinks anbieten können. Laut NVIDIA lässt sich deren Anzahl aber auch abhängig vom gewünschten Zielmarkt anpassen. Die NVLink-Verbindungen können flexibel zusammengefasst, um auch hier wieder dem jeweiligen Anwendungsfall gerecht zu werden. Denkbar ist beispielsweise eine einfache GPU-CPU-Verbindung, aber auch ein Netzwerk aus GPU-CPU- und GPU-GPU-Verbindungen.
Nicht nur die Prozessoren und Beschleuniger eines Knotens und mehreren Knoten direkt untereinander profitieren durch eine direkte Verbindung, auch spielt der Unified Memory eine immer wichtigere Rolle und profitiert von einem schnellen Interconnect.
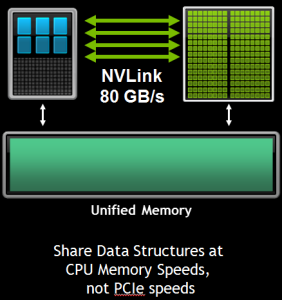
Mit den beiden neuen Supercomputern und der Zusammenarbeit mit IBM könnte sich eine Technologie etablieren, die früher oder später auch auf dem Desktop eine Rolle spielt. Die kommende GPU-Generation Pascal kann bereits über NVLink und PCI-Express kommunizieren, allerdings wird NVLink zunächst einmal den Servern vorbehalten bleiben. Ohnehin wird es noch etwas dauern, bis wir Produkte und Technologien wie Pascal, NVLink sowie Summit und Sierra in Aktion sehen werden.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
