

Werbung
In einem Webcast hat Intel soeben Informationen zu der nächsten Generation der Atom-Mikroarchitektur (Codename Silvermont) bekannt gegeben. Intel hat die Prozessoren, die unter den Codenamen Bay Trail und Merrifield entwickelt werden, im Vergleich zu den alten Modellen kräftig aufgebohrt. Die größte Veränderung ist eine Out-of-Order-Architektur, die zusammen mit anderen Verbesserungen eine bis zu dreifache Performance mit demselben Stromverbrauch oder eine fünffach längere Laufzeit bei gleicher Performance ermöglicht.
Neben Bay Trail, der hauptsächlich für den Einsatz in Tablets, Notebooks und kleinen Desktop-Systemen gedacht ist und der gegen Jahresende erscheinen wird, soll sich Merrifield hauptsächlich in Smartphones wiederfinden. Auch hier ist ein Start Ende 2013 geplant, wobei die ersten Geräte mit Merrifield wohl erst Anfang 2014 erscheinen werden - das passt zeitlich perfekt zum MWC. In Servern plant Intel den Einsatz von größeren Atom-Modulen mit bis zu acht Prozessoren, die mittlerweile bereits gesampled werden. Die Codenamen für den Server- und Netzwerk-Sektor sind Avoton und Rangelery.
Neben der neuen Architektur nutzt Intel nun auch die angepasste 22-nm-Technik für den Low-Voltage-Bereich (P1271). Dieser Prozess unterscheidet sich etwas von der Desktop-Variante, kann aber auch mit Tri-Gate-Transistoren und anderen Rafinessen überzeugen. Da im nächsten Jahr ein Refresh bei der Prozessor-Fertigung ansteht, stehen die "Airmont"-Versionen der Atom-Mirkoarchitektur mit 14-nm-Fertigung für Ende 2014/Anfang 2015 auf dem Plan.

Die Architektur von Silvermont
Die Architektur von Silvermont musste Intel an mehreren Stellen aufbohren, um mit den aktuellen ARM-Modellen und auch der AMD-Konkurrenz (Brazos/Jaguar) auf Dauer mithalten zu können. Anstatt die In-Order-Architektur weiter zu verwenden, setzt Intel nun auf eine kompliziertere Out-of-Order-Pipeline. Dies ist sowohl aus Performancegründen wie auch aus Stromspargründen interessant: Wenn bei einer In-Order-Pipeline eine Branch-Prediction falsch ist, wird die komplette Pipeline geleert. Das Ergebnis muss von Beginn an neu berechnet werden. Das kostet Zeit - und Rechenleistung und damit natürlich auch Energie. Zusätzlich zur Out-of-Order-Execution Pipeline hat Intel natürlich auch die Branch Prediction selber verbessert. Macro-Ops, ein größerer L1-Cache und eine breitere Anbindung sind weitere Verbesserungen des Kerns:

Interessant ist auch, dass Intel verschiedene Silvermont-Module anbieten kann, die eine unterschiedliche Anzahl von Kernen mitbringen können. Pro "Core-Modul" sind zwei Kerne und 1 MB L2-Cache zu kombinieren. So ist theoretisch ein einzelner Kern mit 1 MB L2-Cache (und einem zweiten abgeschalteten Kern) möglich, aber auch größere Module mit acht Kernen und 4 MB L2-Cache durch die Kombination von vier Silvermont-Modulen. Ergänzt wird der Kern um einen System Agent und den Memory-Controller. Das Speicherinterface wird weiterhin ein 64-Bit-Dual-Channel-Interface mit DDR3-SDRAM sein.
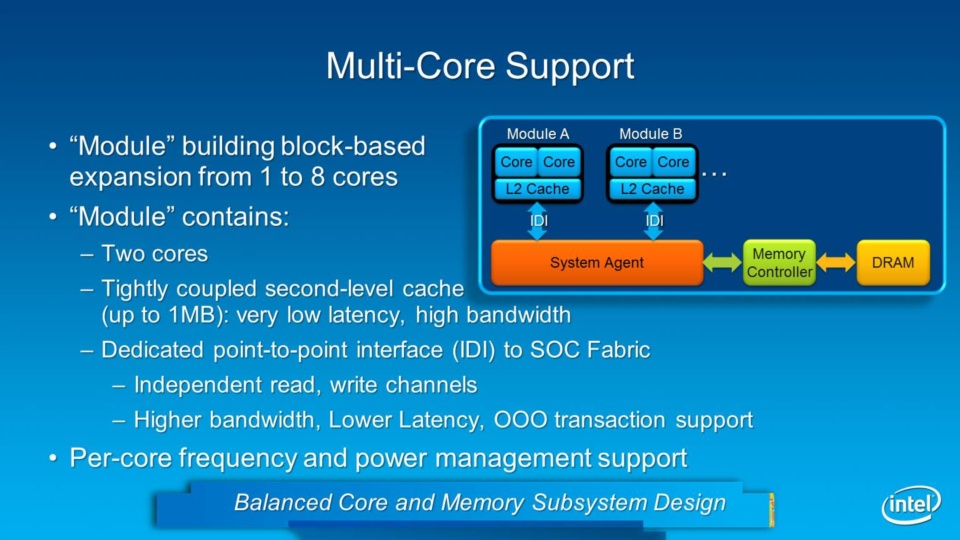
Zu den Verbesserungen kommen weitere Punkte: Die SSE4.1/4.2-Unterstützung ist hier zu nennen, Virtualisierungstechniken, AES-NI, Intel Secure-Key und weitere Instruktionen aus der IA-Welt werden unterstützt.

Zudem hat Intel einen Burst Mode implementiert, der eine ferne Verwandtschaft mit dem Turbo Mode bei Core-Prozessoren hat. Auch hier wird ein Power-Envelope zwischen einzelnen Kernen und der Grafikeinheit verwendet, die Performance kann je nach Bedarf zwischen den Prozessoren und der Grafikeinheit aufgeteilt werden:


Auch bei den Power-States hat Intel einiges verbessert:
Wie immer zeigte Intel auch diverse Benchmarks. Die von Intel zur Verfügung gestellten Benchmarks haben wir in der folgenden Kategorie zusammengefasst. Es zeigt sich die von Intel versprochene 2-3-fache Performanceverbesserung und deutliche Einsparungen beim Stromverbrauch:
{jphoto image=36712}
