Dafür gibt es die APIs mit denen man die Thread Affinity verändern kann, so dass die Threads nur auf bestimmten Cores laufen.
Und das sind für den Anwendungszweck leider die komplett falschen APIs weil die es erfordern würden das man erst die Topologie des Prozessor abfragt, und dann die Aufgabe des Schedulers übernimmt, und dann auf einem Prozessor der bereits ausgelastet ist die falsche Entscheidung getroffen hat.
Klassische Affinitäten machst du nur wenn du PCIe oder Cache-Zugriffe optimieren musst, alles andere macht der Scheduler in sämtlichen Randfällen besser.
Aber danke für die Bestätigung dass hier Wissenslücken sind
")
Unter Windows, direkt gegen die Windows-API wäre z.B. das hier die richtige Antwort gewesen:
https://learn.microsoft.com/en-us/w...ocessthreadsapi-thread_power_throttling_state Das deaktiviert auf einem nicht vollständig ausgelastetem Kern Turbo-Boosts, und setzt das Scheduling auf E-Cores als "akzeptabel". Bzw. umgekehrt fordert es die Performance-Kerne und Boosts soweit wie möglich.
Während unter Linux stattdessen die Priority-Class maßgeblich ist, und die Trennung zwischen den Kern-Typen eher "fließend" ist, mit einer Präferenz für Auslastung der P-Cores mit hoch-prioren Tasks bevor E-Cores als Ausweichoption aktiv werden. Einen "ich bevorzuge E-Cores"-Hinweis gibt es da so weit ich weiß zur Zeit gar keins.
Was Linux und Windows gemeinsam haben: Der Scheduler optimiert für "Instruktionen pro Watt" - was häufig vom Last-Profil über die Zeit abhängt, und gar nicht so sehr vom "gewünschten" Kern-Typ. Tasks die sagen "ich brauche keine Echtzeit" noch nebenher auf dem P-Core laufen zu lassen, weil der ansonsten in den Sleep-State müsste lohnt sich dann häufig doch...
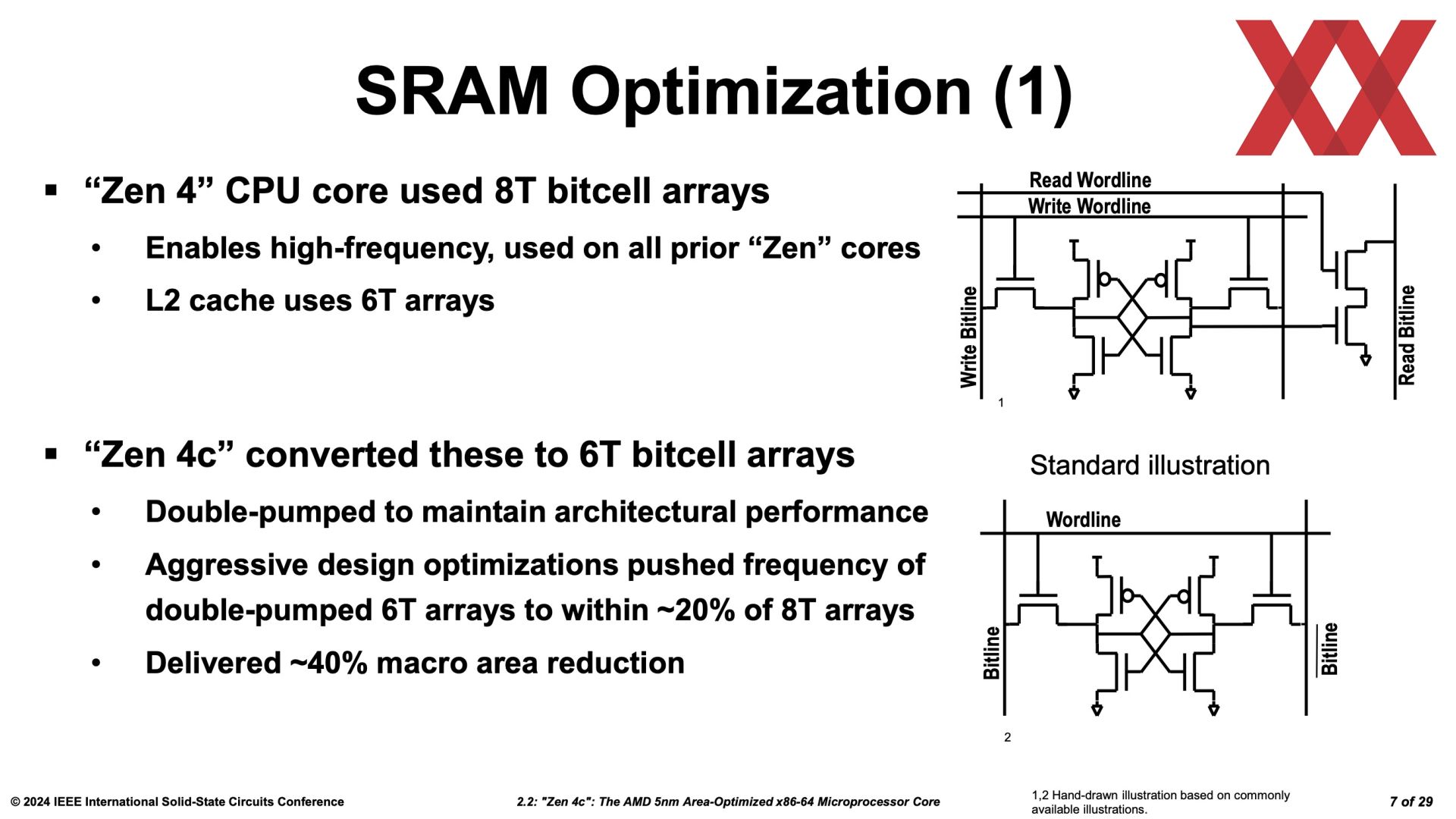
Zen4c ist keine Hybrid Architektur, sondern verfügt nur über andere Kerne als Zen4
Es kommen aber Mobil-CPUs mit Zen4 / Zen4c Mix. Beziehungsweise es ist davon auszugehen dass AMD spätestens ab der nächsten Serie auch hybride Epics mit anbietet - es gibt schließlich auch im Serverbereich immer einzelne Services die besonders sensibel auf Single-Score-Performance reagieren. Und für letztere ist es - falls die Performance-Kerne bereits ausgelastet sind - trotzdem noch die bessere Entscheidung auf dem "falschen" Kern zu laufen als noch länger zu warten...


{kind=link}
{kind=link}