Ich weis nicht genau, was dieser scale Faktor da bei BF4 schlussendlich macht... Auch hab ich kein BF4 um mir das selbst anzuschauen
")
Heist dort 200%, dass die doppelte Pixelanzahl pro Achse berechnet wird? Oder einfach nur die doppelte gesamt Anzahl? Denn doppelte Pixel pro Achse wären vierfache gesamt Pixel -> ergo FHD zu UHD bspw.
Allerdings sprechen die Zahlen nicht gerade von extrem viel mehr VRAM zuwachs. Das sind eben diese besagten 10-30% mehr, die man da im Schnitt so sieht bei 4x mehr Bildpunkten. Aber eben alles andere als 1:1 mit der Auflösung, wie man es gern hinstellt.
Wie gesagt, bei BF3 -> ich spiele da hin und wieder mal die SP Kampagne, schaut das völlig anders aus. Ich komme auf unter 2GB in FHD, schon mit 2880er Auflösung deckelt das bei mir bei 3GB an. UHD geht gar nicht...
Aber ja, es kann natürlich auch von der GPU selbst kommen.
Der Leistungsbedarf bei FHD auf UHD liegt in vielen Reviews und auch bei meinen eigenen Tests bei ca. 50-70% FPS Verlust. Heist andersum, man benötigt ca. 2-3x so viel Rohpower um die FPS gleich zu halten.
Wenn die VRAM Belegung soweit überbucht wird, dass permanent Daten umgeschaufelt werden, dann brechen auch gern mal die FPS deutlich ein... Nur ist man dann idR auch mit dem Überbuchen schon weit über das "normale Nachladeruckler-Verhalten" drüber hinaus...
Wie gesagt, es ist halt schwierig zu messen, da es keine geeignete Messmethode gibt. Man sucht sich aktuell irgendwelche Messplätze und beobachtet den VRAM Bedarf und die FPS.
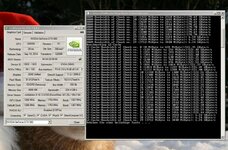
Warum die Karte womöglich anfängt bei um die 3,5GB ein/umzulagern, ist eigentlich die entscheidende Frage... Das bekommt man damit aber faktisch nicht raus!
PS: was das Tool da angeht, die Werte werden schon stimmen... Es macht im Grunde nix weiteres, als Blöcke von 128MB pro Durchlauf im Speicher zu belegen und diese zu "nullen". Dabei wird unmittelbar vor dem Belegen des jeweiligen Blöcks und unmittelbar danach die benötigte Zeit dafür ermitteln. Anhand der Zeit und dem Wissen, das es 128MB pro Block sind, lässt sich effektiv die Speicherbandbreite errechnen, die die Karte schreibend in den VRAM schafft. -> also das was das Tool dort an Zahlen ausspuckt, entspricht zu 99% auch wirklich der Realität.
Bestenfalls könnte man hier ansetzen und versuchen zu erkunden, ob der Cuda Code mit Games vergleichbar ist. Aber ich gehe davon aus, dass dies der Fall ist...
Leider kommt erschwerend hinzu, dass die Karte bei simpler Belegung des VRAMs scheinbar nicht in der Lage ist, den Speicherbereich, der belegt ist durch Windows, auszulagern... Sprich ab einem gewissen Punkt wird automatisch über den PCIe Slot in den RAM geschrieben, da kein Platz mehr im lokalen VRAM frei ist.
Hier stellt sich mir als erstes primär die Frage, ist dies in Games auch so? Bis jetzt gibts ja keine "Vollbild Direct3D" Version des Benches... Müsste sich sich mal jemand dransetzen ob das dort ähnlich ist.
Warum das bei der 970er schon bei um die 3,5GB anfängt einzuknicken, ist allerdings mit dem Bench auch nicht auslesbar... Denn offenbar bekommt die Anwendung keinen exklusiven Zugriff auf die volle Speichermenge... Und Cuda schreibt dann einfach über den PCIe Slot im RAM weiter. Um Knallharte Speicherüberläufe zu verhindern, die die Programme dann abstürzen lassen würden, ist dies auch ganz gut so, wie es ist. Warum man dort allerdings nur 3,5GB sieht? Das weis wohl nur NV selbst
 - - - Updated - - -
- - - Updated - - -
Du vergisst hier aber den Vergleich zur GTX980, wo das eben nicht der Fall ist. Erklärung?
Ich meinte damit eher, dass es bei so ziemlich allen Karten hinten einbricht, weil eben Windows da zwischen funkt... Mit einem Test auf ner zweit GPU, die nicht Windows reserviert ist, kann das aber immernoch alles und nix sein... Meine Vermutung, Treiber stetzt ein Limit! Ob gewollt oder ungewollt? Keine Ahnung...
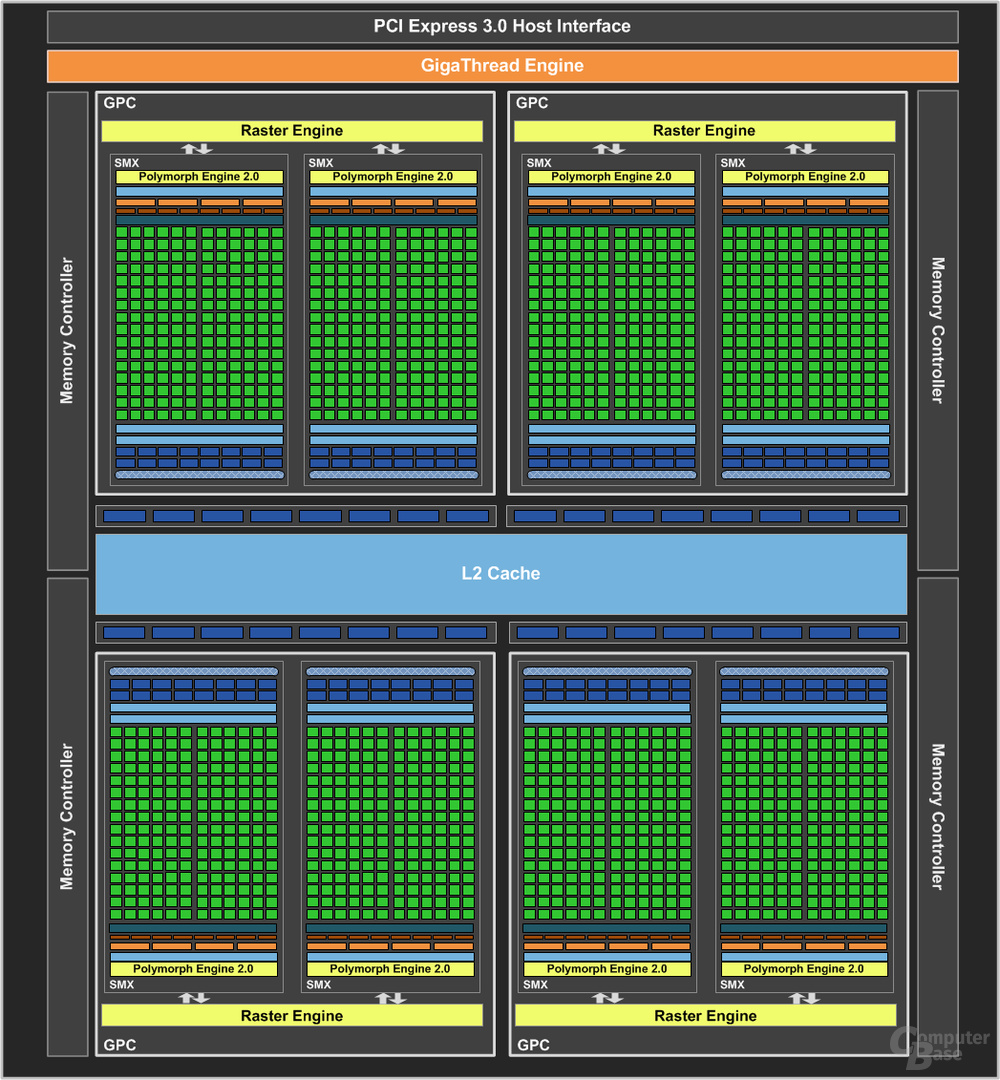
Kepler=SMX
Maxwell=SMM
Die GTX980 besitzt 16SMM-Cluster, davon werden 3 für die GTX970 abgeschnitten. Somit besitzt eine GTX970 insgesamt 13SMM-Cluster. Den VRAM zu belegen ist auch nicht das eigl. Problem, sondern diesen durchgehend mit Full-Speed, wie bei einer GTX980.

Ob un SMX oder SMM, ich denke es sollte klar sein, das diese "Shadercluster" damit gemeint waren...
4x 64bit Speichercontroller = 256bit Speicherinterface bei 16SMM-Cluster. Bei der GTX970 werden nun aber 3SMM-Cluster weggeschnitten. Daraus ergibt sich...
4096MB=256bit=16SMM
3328MB=208bit=13SMM
16SMM zu 13SMM ergeben auch etwa 17% weniger. Die Karten können natürlich alle 4096MB belegen, jedoch nur bis 3328MB mit Full-Speed. Deshalb auch mein Vergleich mit der Kepler-Architektur.
Nur wir soll das technisch gehen?
Du kannst nicht mal ebenso vom SI ein paar "Bits" anknapsen... Wenn ich das richtig sehe, geht dort nur entweder oder... Also volle Anbindung und läuft oder eben nicht.
Das ist bildlich wie ne Autobahn mit entsprechend vielen Spuren. Der Durchsatz kommt davon, dass entsprechend viele Autos gleichzeitig über alle Spuren mit einer bestimmten Geschwindigkeit fahren (Takt). Würde das SI nun kleiner werden, dann würde nicht auf einmal ein Teil des Durchsatzes nur für eine bestimmte Menge wegbrechen. Weil die Bandbreite sich daraus zusammen setzt, dass eben die Autos gleichzeitig über die Autobahn fahren und nicht unterschiedlich schnell.
Zumal eben die Belegung (also der Bereich größer 3,5GB) ja irgendwo her kommen muss. Die Zellen sind an den Controller angebunden. Jede wenn man es bildlich sieht, 1:1. Heist also, schreibst du nen sagen wir 256MB Block, dann wird jede Zelle die gleiche Menge Daten aufnehmen. Da alle Zellen gleichzeitig beschrieben werden, kommt die Bandbreite zustande. Es werden also Chunks gebildet. Bei acht Speicherchips heist das, pro Speicherchip ein Chunk. Also geht jeder 8. Chunk immer an den selben Speicherchip. -> somit werden die Zellen gleichmäßig gefüllt.
Mir fällt keine logische Erklärung ein, warum hintenraus die letzten 500MB nicht mit vollem Speed angesprochen werden könnten. Bspw. im Vergleich zu dieser 660TI mit 192Bit und 2GB VRAM wurde dort ja getrickst. Nämlich wurden dort zur Hälfte doppelt so große Chips verwendet. Diese doppelt so großen Chips hängen, wenn ich das richtig sehe aber eben nicht an allen Controllern, sondern nur an der Hälfte. Somit kann maximal die Menge von 1,5GB über alle "Fahrspuren" angesprochen werden, wärend der Rest nur über die halbe Bandbreite verfügt.
Beim GM204 sieht das aber nicht so aus... Denn die Chips sind alle gleich groß, es sind die gleichen und die Verbindung ist auch nicht irgendwo eingeschränkt... Im Grunde kann es also nicht am SI liegen.
Was technisch denkbar wäre, es könnte eine Ebene weiter vorn zu einem Flaschenhals kommen. Das könnte erklären, warum die 970er weniger Schreibleistung bietet als die 980er. Nämlich wie du schon sagtest, wenn pro SM
M ")
bigok
")
in die Crossbar geschrieben wird, wirds natürlich weniger Durchsatz, wenn da weniger SMMs vorhanden sind... Womöglich könnte das SI sogar mehr wegschreiben, aber es kommen gar nicht so viele Daten beim SI an.
Nur erklärt das eben genau nicht, warum der "obere" Bereich eben langsamer sein sollte... Denn das ist doch das entscheidende Problem. Diese von den diversen Usertests angesprochenen Nachladeruckler kommen doch daher, weil die Karte versucht mehr VRAM zu belegen, dies womöglich auch macht aber eben dann auf einmal Bandbreite fehlt und der Spaß über PCIe ausgelagert wird, was bedeutend langsamer ist.
Wobei ich gerade sehe, dass die PCIe Bandbreite bei 16x und 3.0 Ausführung gerade mal bei 16GB/sec liegt... Der Bench misst allerdings 20-22GB/sec... -> klingt ebenso komisch.
So 100% rund ist das nicht muss ich sagen... Denn es sollte nicht möglich sein bei gleicher Speicherchip Ausstattung eben nur einen Teil mit vollem Speed anzusprechen, wärend obenraus ein Teil nicht voll ansprechbar ist/bleibt. Dafür fällt mir wie gesagt keine technische Erklärung ein.
Selbst WENN! (mal angenommen) das SI "nur" 208Bit breit wäre, dann könnte das womöglich den geringeren Durchsatz zur 980er erklären. Aber diese 208Bit bzw. der Durchsatz müssten immernoch voll über den gesamten Bereich anliegen. Denn bei gleichmäßiger Beschreibung der VRAM Chips würden ab ~3,5GB ALLE Chips eben einen Teil dieser fehlenden 500MB aufnehmen müssen. Und da die Chips ja generell über Bandbreite verfügen, müsste also auch folgerichtig der Rest mit "voller" Bandbreite beschreibbar sein.
Die niedrige Bandbreite würde dann zustande kommen, wenn eben ein oder mehr Chips nicht voll angesprochen werden könnten. Nur zeigt eben der Bench, dass es dort unterschiedliche Messungen gibt. Von ~3200-3328MB ist da die Rede. Gabs nicht auch Werte, die höher waren? 3,5GB? Weis nicht mehr genau... Das wäre faktisch eine krumme Zahl und lässt sich somit nicht mit den Hardwaregegebenheiten unter einen Hut bringen. Es sei denn, der Speicher wird nicht über den gesamten Bereich gleich schnell angesprochen. Aber die Speicherchips sind doch mit der 980 und auch den mobile Versionen identisch??