
Da habe ich mal ne Frage zu diesem Setup:
zpool:
* mirror mit 2 ssds, jeweils in PCIe 3 eingesteckt, (je 1x Transcend MTE250H und MTE220S ), Kompression mit LZ4
* arc und slog auf demselben Optane (56GB oder so, komisches Modell) auch in PCIe 3 eingesteckt
* all diese Geräte per pass-through an VM weitergeleitet
* diese Speicher VM hat nur ca. 4GB RAM, NICs sind vmxnet3
* nfs shares von dieser VM in ESXi gemountet (noch nfsv3, sollte aber v4 werden)
* separate vSwitch/Portgruppe/vmkNIC im ESXi für das interne 'Speicher'-LAN, MTU mal auf 5000
* ESXi ist noch Version 6.5
Nun läuft auf diesem Speicher eine Windows VM, und es wird ne paar GB große Datei kopiert (von/zu demselben Laufwerk):
Zurzeit scheint mir die Schreibgeschwindigkeit 'am langsamsten'/(Tiefpunkt der angezeigt wird) bei ca. 250MB/s zu landen - müsste es nicht schneller sein können?
An welchen Stellschrauben kann man die Geschwindigkeit tunen?
Ein Punkt, den ich vorhin gefunden habe, und den man wohl erst am ESXi 7 einstellen kann, ist das Deaktivieren der nfs Delayed ACK time von 100ms.
Umstellen auf nfsv4 will ich noch machen.
viele grüße
zpool:
* mirror mit 2 ssds, jeweils in PCIe 3 eingesteckt, (je 1x Transcend MTE250H und MTE220S ), Kompression mit LZ4
* arc und slog auf demselben Optane (56GB oder so, komisches Modell) auch in PCIe 3 eingesteckt
* all diese Geräte per pass-through an VM weitergeleitet
* diese Speicher VM hat nur ca. 4GB RAM, NICs sind vmxnet3
* nfs shares von dieser VM in ESXi gemountet (noch nfsv3, sollte aber v4 werden)
* separate vSwitch/Portgruppe/vmkNIC im ESXi für das interne 'Speicher'-LAN, MTU mal auf 5000
* ESXi ist noch Version 6.5
Nun läuft auf diesem Speicher eine Windows VM, und es wird ne paar GB große Datei kopiert (von/zu demselben Laufwerk):
Zurzeit scheint mir die Schreibgeschwindigkeit 'am langsamsten'/(Tiefpunkt der angezeigt wird) bei ca. 250MB/s zu landen - müsste es nicht schneller sein können?
An welchen Stellschrauben kann man die Geschwindigkeit tunen?
Ein Punkt, den ich vorhin gefunden habe, und den man wohl erst am ESXi 7 einstellen kann, ist das Deaktivieren der nfs Delayed ACK time von 100ms.
Umstellen auf nfsv4 will ich noch machen.
viele grüße
 )
)") Davon abgesehen macht es wohl doch Sinn, das Ding neu aufzusetzen - bisher war der pool1 nämlich mit HDDs, und es wäre gut, alle Parameter wie Sektorgrößen und so aufeinander abzustimmen..
Davon abgesehen macht es wohl doch Sinn, das Ding neu aufzusetzen - bisher war der pool1 nämlich mit HDDs, und es wäre gut, alle Parameter wie Sektorgrößen und so aufeinander abzustimmen..


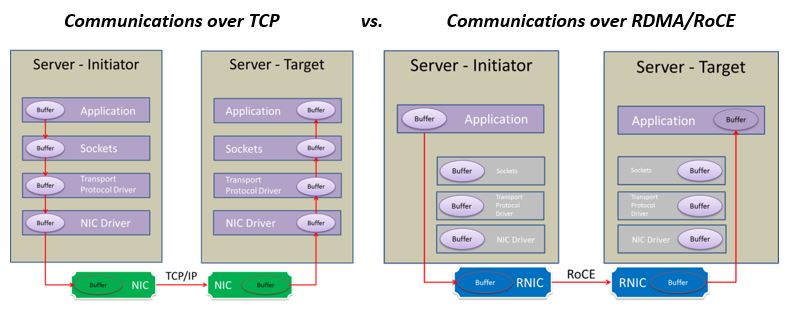



") Es ist nicht wirklich einfach abzuwägen, wo die beste Balance zwischen Datenintegrität und Geschwindigkeit ist. Mit Optane (ich habe eine P4801X 200GB im NAS) kann man sich schon sehr viel Performance bei sync=always erkaufen. Ich bin damit zufrieden und gehe das Risiko ein, dass mein Dateisystem kaputt ist, wenn Stromausfall und Versagen der Optane zeitlich zusammenfallen.
Es ist nicht wirklich einfach abzuwägen, wo die beste Balance zwischen Datenintegrität und Geschwindigkeit ist. Mit Optane (ich habe eine P4801X 200GB im NAS) kann man sich schon sehr viel Performance bei sync=always erkaufen. Ich bin damit zufrieden und gehe das Risiko ein, dass mein Dateisystem kaputt ist, wenn Stromausfall und Versagen der Optane zeitlich zusammenfallen.
