Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
-
Wir sind dabei, den Suchindex des Forums neu aufzubauen. Bis ca. 6 Uhr morgens kann die Qualität der Suchergebnisse variieren.
-
Hardwareluxx führt derzeit die Hardware-Umfrage 2025 (mit Gewinnspiel) durch und bittet um eure Stimme.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
[Sammelthread] Grafikkarten - Technikdiskussion
- Ersteller Stegan
- Erstellt am
Christoph0815
Banned
- Mitglied seit
- 25.02.2007
- Beiträge
- 8.127
Mal eine Frage: die neuesten Grakas werden doch in 55nm oder gar in 40nm gefertigt....
Jetzt mal als noob meine Frage: 1nm ist doch etwa der siebzigtausendeste Teil der Breite eines menschlichen Haares.... also unglaublich ! Da bewegt man sich doch auf Atomebene !? Was genau ist da in 55nm gefertigt ?? Und wie zum Geier ist sowas überhaupt möglich ??
Jetzt mal als noob meine Frage: 1nm ist doch etwa der siebzigtausendeste Teil der Breite eines menschlichen Haares.... also unglaublich ! Da bewegt man sich doch auf Atomebene !? Was genau ist da in 55nm gefertigt ?? Und wie zum Geier ist sowas überhaupt möglich ??
möglich ist vieles, auch wenn es teilweise unvorstellbar scheint...
Die bisherige Technik wird wohl ca. bis 10nm funktionieren, dann gibt es physikalische Grenzen, die nicht weiter überwunden werden können. Außer mit anderen Ansätzen.
Zu dem Thema gibts aber zu hauf Lesestoff bei Onkel Google...
Und übrigens, wir bewegen uns derzeit schon in Regionen, wo es vor 20Jahren noch hieß, das ist technisch überhaupt nicht machbar.
Der Entwicklungstrend reist derzeit noch nicht ab, mal abwarten was da noch kommt...
Ich denke mal wir werden mindestens noch 10-15Jahre gut mit neuen Entwicklungen rechnen können. Und was dann ist, das weis jetzt noch keiner
Die bisherige Technik wird wohl ca. bis 10nm funktionieren, dann gibt es physikalische Grenzen, die nicht weiter überwunden werden können. Außer mit anderen Ansätzen.
Zu dem Thema gibts aber zu hauf Lesestoff bei Onkel Google...
Und übrigens, wir bewegen uns derzeit schon in Regionen, wo es vor 20Jahren noch hieß, das ist technisch überhaupt nicht machbar.
Der Entwicklungstrend reist derzeit noch nicht ab, mal abwarten was da noch kommt...
Ich denke mal wir werden mindestens noch 10-15Jahre gut mit neuen Entwicklungen rechnen können. Und was dann ist, das weis jetzt noch keiner
Man dachte früher, dass das heute überhaupt nicht mehr machbar sei, weil man damals keine vernünftigen Belichtungsverfahren kannte. Belichtung von Strukturen, deren Breite unterhalb der Wellenlänge des Lichts liegt (und das ist hier eindeutig der Fall), bekommt man nur mit "Tricks" hin. Oder mit anderen Verfahren. Zum Beispiel Elektronenstrahllitographie. Aber hier musst du wirklich selber lesen, da kann ich Romane zu schreiben.
"Was" da genau 55nm groß ist, sind die Strukturen. Strukturen sind zum Beispiel Transistoren. Je kleiner die werden, desto geringer ist die benötigte Spannung zum Schalten, desto schneller kann der Schaltvorgang gehen und desto effizienter wird folglich der Schaltkreis.
Eine Grenze erreichen wir hier vermutlich sehr bald, denn es ist nicht die Strukturbreite, die Anlass zur Sorge gibt, sondern die Dicke des Gatedielektrikums bei den verwendeten MOSFETs (Intel benutzt zum Beispiel im 45nm-Prozess Hafnium wegen seiner hohen Dielektrizitätskonstante, deswegen auch high-k, denn deren Symbol ist k - klassisch benutzt man da Siliziumdioxid). Denn das ist der "dünnste" Punkt im Transistor. Bei 32nm Strukturbreite nähern wir uns da schon Dicken von weniger als 10 Atomlagen. Abgesehen davon, dass das an sich schon wirkliche Schwierigkeiten macht - zum Beispiel tunneln Elektronen bei so dünnen Schichten gern mal, hierzu kannst du in der Quantenmechanik mehr erfahren, wenn du willst, vermutlich kennst du den Effekt als "Leckstrom" - ist das eben die Stelle, an der wir am ehesten an die Grenzen kommen. Und wie es dann weitergeht, weiß noch keiner.
"Was" da genau 55nm groß ist, sind die Strukturen. Strukturen sind zum Beispiel Transistoren. Je kleiner die werden, desto geringer ist die benötigte Spannung zum Schalten, desto schneller kann der Schaltvorgang gehen und desto effizienter wird folglich der Schaltkreis.
Eine Grenze erreichen wir hier vermutlich sehr bald, denn es ist nicht die Strukturbreite, die Anlass zur Sorge gibt, sondern die Dicke des Gatedielektrikums bei den verwendeten MOSFETs (Intel benutzt zum Beispiel im 45nm-Prozess Hafnium wegen seiner hohen Dielektrizitätskonstante, deswegen auch high-k, denn deren Symbol ist k - klassisch benutzt man da Siliziumdioxid). Denn das ist der "dünnste" Punkt im Transistor. Bei 32nm Strukturbreite nähern wir uns da schon Dicken von weniger als 10 Atomlagen. Abgesehen davon, dass das an sich schon wirkliche Schwierigkeiten macht - zum Beispiel tunneln Elektronen bei so dünnen Schichten gern mal, hierzu kannst du in der Quantenmechanik mehr erfahren, wenn du willst, vermutlich kennst du den Effekt als "Leckstrom" - ist das eben die Stelle, an der wir am ehesten an die Grenzen kommen. Und wie es dann weitergeht, weiß noch keiner.
derMeister
Semiprofi
Ich glaube deswegen hat Intel schon auf die Mehrkern-Prozzessoren umgeschwenkt, da eine reine Takterhöhung in Zukunft nicht mehr machbar scheint mit bisheriger Technologie bzw genau wie Du es beschreibst, irgendwann ist Ende. Da kommt Mehrkerntechnologie gerade recht.
Ich glaube deswegen hat Intel schon auf die Mehrkern-Prozzessoren umgeschwenkt, da eine reine Takterhöhung in Zukunft nicht mehr machbar scheint mit bisheriger Technologie bzw genau wie Du es beschreibst, irgendwann ist Ende. Da kommt Mehrkerntechnologie gerade recht.
Nochmal, GPUs sind mit CPUs in dem Punkt absolut nicht vergleichbar...
Wenn man so will besteht eine 280/285GTX aus 240 (Shader)Cores usw.
Die GPU ist schon eine mehr Kern Geschichte, es macht also absolut wenig Sinn, diese nochmals komplett doppelt oder mehrfach auszulegen.
Eine CPU ist ein Kern, als Dualcore mit 2 Kernen usw.
Hier macht es wiederum Sinn, wobei eben auch nicht bis ins unendliche, weil die Softwareanpassung eben extrem schwierig ist.
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Die bisherige Technik wird wohl ca. bis 10nm funktionieren, dann gibt es physikalische Grenzen, die nicht weiter überwunden werden können. Außer mit anderen Ansätzen.
Spin, Licht, Quanten.
Oder halt andere Architektur (als x86 bei der CPU).
Bei Grafikkarten wird sich auch nochwas ändern. Ich glaube nicht das wir bei den Shadereinheiten stehen bleiben werden sondern auch die bald überholt sind...
Ich glaube deswegen hat Intel schon auf die Mehrkern-Prozzessoren umgeschwenkt, da eine reine Takterhöhung in Zukunft nicht mehr machbar scheint mit bisheriger Technologie bzw genau wie Du es beschreibst, irgendwann ist Ende. Da kommt Mehrkerntechnologie gerade recht.
Das ist nicht weit genug gedacht, weil in dem Moment, wo die von mir beschriebene Problematik bei der Chipfertigung auftritt, natürlich auch mehrere Kerne keine Lösung sind. Das Problem ist ja, dass du den Chip nicht mehr kleiner machen kannst, und natürlich könntest du dann mehrere Kerne aneinanderpappen, aber das Problem bleibt bestehen: Der Chip wächst. Und dann sind wir von wohnzimmergroßen Prozessoren nicht mehr weit entfernt.
Neurosphere schrieb:Spin, Licht, Quanten.
Oder halt andere Architektur (als x86 bei der CPU).
Bei Grafikkarten wird sich auch nochwas ändern. Ich glaube nicht das wir bei den Shadereinheiten stehen bleiben werden sondern auch die bald überholt sind...
Spin, Licht, Quanten? Weißt du, wovon du da sprichst? Tatsächlich ist die Nutzung von Elektronenspins bereits eine Möglichkeit, um Qubits zu realisieren (zumindest erfüllt die Realisierung alle Anforderungen an ein Qubit, d.h. 2-Tupel aus einem Hilbertraum über den kompl. Zahlen, dessen Skalarprodukte bestimmte Eigenschaften erfüllen müssen) und damit das, was viele unter dem Unwort Quantencomputer glauben zu verstehen. Allerdings ist da alles so radikal anders - damit jetzt schon zu argumentieren macht keinen Sinn. Für Licht gilt Ähnliches; allerdings gehts hier auch nicht unbegrenzt klein, weil auch photoaktive Transistoren eine bestimmte Größe haben.
Was du gegen die x86-Architektur hast, frage ich mich - klar, die ist alt, aber nicht grundlegend verkehrt. Dekodieren musst du sowieso und da machen die paar Befehle das Kraut auch nicht mehr Fett. Damit schiebst du das Problem vielleicht nach hinten, aber Lösen wirst du es nicht.
Und wenn du Theorien dazu hast, was sich an Shadercores ändern soll, bin ich gespannt, sie zu hören.
")
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Spin, Licht, Quanten? Weißt du, wovon du da sprichst? Tatsächlich ist die Nutzung von Elektronenspins bereits eine Möglichkeit, um Qubits zu realisieren (zumindest erfüllt die Realisierung alle Anforderungen an ein Qubit, d.h. 2-Tupel aus einem Hilbertraum über den kompl. Zahlen, dessen Skalarprodukte bestimmte Eigenschaften erfüllen müssen) und damit das, was viele unter dem Unwort Quantencomputer glauben zu verstehen. Allerdings ist da alles so radikal anders - damit jetzt schon zu argumentieren macht keinen Sinn. Für Licht gilt Ähnliches; allerdings gehts hier auch nicht unbegrenzt klein, weil auch photoaktive Transistoren eine bestimmte Größe haben.
Ich kann dir da nur mit angelesenem Wissen dienen da ich was anderes Studiere.
Aber Spin und Quanten sind eigentlich was anderes. Zumindest so wie ich es gemeint habe.
Hier mal was zum Spin-Transistor: http://en.wikipedia.org/wiki/Spin_transistor
Eigentlich sollte es damit möglich sein schnellere Schaltungen zu realisieren ohne dabei die Grundlegende Architektur wechseln zu müssen. Sollte ich mich irren lasse ich mich da gerne belehren
")
An Schaltungen über Licht wird ja auch schon seit Längerem geforscht. Intel hat bereits einen Prozessor vorgeführt (das soll nicht heißen das die kurz vorm Kommen sind sondern nur eine Funktionsvorführung). Intel gibt aber eine steigende Leistung im Verhältniss zum klassischen Transistor mit dem Faktor 30 an.
Hier mal was dazu:
http://www.golem.de/0712/56423.html
Was du gegen die x86-Architektur hast, frage ich mich - klar, die ist alt, aber nicht grundlegend verkehrt. Dekodieren musst du sowieso und da machen die paar Befehle das Kraut auch nicht mehr Fett. Damit schiebst du das Problem vielleicht nach hinten, aber Lösen wirst du es nicht.
Es ging mir ja auch nicht um die Lösung. Nur um die Möglichkeit aus einer Transistorbasierenden CPU durch eine andere Architektur mehr Leistung zu gewinnen.
Und dann gibt es ja noch die Idee das Prozessoren Werte nicht mehr exakt berechnen sondern bewusst unwichte Stellen ungenau berechnet werden um Zeit zu sparen. Ob das in jeeer Hinsicht möglich ist sei mal dahingestellt, aber es ist zumindest ne Idee die Rechenleistung einfach zu erhöhen.
Und wenn du Theorien dazu hast, was sich an Shadercores ändern soll, bin ich gespannt, sie zu hören.
Ganz ehrlich, ich weiß es nicht. Aber warum sollte es bei Shadereinheiten enden und man versucht nurnoch die Zahl der Einheiten zu steigern? Vielleicht setzt sich ja auch ein Paralleldesign durch die aus wesentlich komplexeren Einzeleinheiten besteht wie LRB.
Ganz ehrlich, ich weiß es nicht. Aber warum sollte es bei Shadereinheiten enden und man versucht nurnoch die Zahl der Einheiten zu steigern? Vielleicht setzt sich ja auch ein Paralleldesign durch die aus wesentlich komplexeren Einzeleinheiten besteht wie LRB.
Neja, schlussendlich wird es aber auch bei Larrabee darauf hinaus laufen, dass man die Recheneinheiten erhöht um mehr Leistung zu bekommen. (oder eben Optimierungen einfließen lässt bzw. den Takt erhöht)
Des weiteren, eine Softwarelösung wird immer ineffizienter sein als eine Hardwarelösung. Bei Larrabee wird einiges/vieles über Software gelöst (was mit Sicherheit noch sehr viel Optimierungsspielraum lässt)
Es wird aber mit Sicherheit irgendwann der Punkt kommen, an dem man die Leistung der Hardware überverhälltniss mäßig stark steigern muss um ein wenig mehr Leistung am Ende rauszubekommen.
Und hier liegt für mich der Knackpunkt, die Ineffizienz nimmt stetig zu...
Ob das ganze am Ende aufgeht, oder ob ich mich da irre, bleibt abzuwarten...
Larrabee klingt zwar derzeit richtig gut, aber ich frage mich ehrlich gesagt, ob die angepeilte Leistung zum Release der ersten Endkundenlösung immernoch ausreicht um gegen die hochoptimierte Hardware Lösungen von AMD/NV anzukommen...
Des weiteren stellt sich mir die Frage, ob der Endkunde für die "x86 Fähigkeit" beim Larrabee überhaupt Verwendung hat. Ich weis nicht, aber ich stelle mir das ein wenig kontraproduktiv vor, man nimmt der CPU zwar Arbeit ab, aber wenn es möglich ist in einer "Grafikkarte" derart hohe Leistung bereit zu stellen warum sollte man den Weg dann nicht direkt für die normale CPU gehen können? Scheint man aber nicht zu machen.
Heist soviel wie, das ganze muss wohl auch einige Nachteile haben, welche bei der normalen CPU besser funktionieren.
Ich denke hierbei an den Optimierungsaufwand für die Software um alle Cores vollständig nutzen zu können usw.
Heist also, ohne die nötige Software wird wohl auch die beste x86 kompatible "Grafikkarte" dem Endanwender nix nutzen... Für einige wenige Bereiche wie Bild/Videobearbeitung oder ähnliches lässt sich da sicher was machen, aber für den großen Rest!?
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Larrabee klingt zwar derzeit richtig gut, aber ich frage mich ehrlich gesagt, ob die angepeilte Leistung zum Release der ersten Endkundenlösung immernoch ausreicht um gegen die hochoptimierte Hardware Lösungen von AMD/NV anzukommen...
Den gleichen Zweifel hege ich auch. Allerdings finde ich es ziemlich interessant was Intel da macht. Die Hardwarekrone müssen sie meiner Meinung nach garnicht ergattern.
Heist also, ohne die nötige Software wird wohl auch die beste x86 kompatible "Grafikkarte" dem Endanwender nix nutzen...
Wahrscheinlich. Immerhin gibt es aber wohl schon einige Titel die für LRB optimiert werden.
Den gleichen Zweifel hege ich auch. Allerdings finde ich es ziemlich interessant was Intel da macht. Die Hardwarekrone müssen sie meiner Meinung nach garnicht ergattern.
Ne das muss nicht sein, aber wenn man sieht, was aktuelle Karten im Bereich 100-150€ zu leisten im Stande sind, dann könnte ein zu "kurz geratenes" Larrabee Projekt schnell wieder unter gehen.
Denn wer brauch sonst massive 3D Leistung wenn nicht die Gamer?
Der LowEnd/Office Bereich ist für Larrabee völlig uninteressant, bleibt also noch der Mittelklasse Bereich, wenns für HighEnd nicht reicht.
Und hier habe ich eben die Befürchtung, das bei aktuellen Preisen dort Larrabee verhältnissmäßig ein zu schlechtes P/L Verhälltnis haben könnte...
Wahrscheinlich. Immerhin gibt es aber wohl schon einige Titel die für LRB optimiert werden.
Kann gut sein, ich vertrete aber nach wie vor die Auffassung, das aktuelle Dualcore CPUs für den Otto normalo User vollkommen ausreichend schnell sind. Die Software des Otto normalos brauch einfach keine Leistung. Ein Browser, ein Mediaplyer, eine Office Suite und ein Bildbetrachtungsproggi funktionieren 1A auf selbst dem schlechtesten Dualcore am Markt. Mit schnelleren CPUs wirds dort auch nicht wirklich besser.
Einzig der Gaming Sektor, Bild/Videobearbeitung und andere Spezielle Rederingsachen oder CAD Sachen profitieren sehr stark von mehr Leistung.
Nur bis auf die Games wird der Normalo User eher damit nix am Hut haben...
Klar es gibt Außnahmen, wie eben die Freaks hier im Forum, aber die Regel sagt eben meist was anderes. Daher meine bedenken, ob es sich lohnt imho x86 Kompatible Karten zu bauen!?
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Daher meine bedenken, ob es sich lohnt imho x86 Kompatible Karten zu bauen!?
Ich glaube die x86 Kompatibilität ist mehr ne Nebenerscheinung. Intel hat ganz einfach auf Technik zurückgegriffen die sie bereits hatten anstatt etwas Grundlegend neues designen zu müssen. Das spart Kosten und Entwicklungszeit.
Der Vorteil ist halt das man theoretisch sämmtliche x86 Befehle auf den LRB auslagern kann. Also nicht nur Physik (in Form von Havok) sondern zB auch KI-Berechnungen usw.
Im Prinzip sollte jede Software die sich paralellisieren lässt so einfach von LRB Profitieren können. OB das jetzt dem Anwender viel Bringt sei erstmal dahingestellt, aber allein die Möglichkeit ist interessant.
Ich glaube die x86 Kompatibilität ist mehr ne Nebenerscheinung. Intel hat ganz einfach auf Technik zurückgegriffen die sie bereits hatten anstatt etwas Grundlegend neues designen zu müssen. Das spart Kosten und Entwicklungszeit.
Der Vorteil ist halt das man theoretisch sämmtliche x86 Befehle auf den LRB auslagern kann. Also nicht nur Physik (in Form von Havok) sondern zB auch KI-Berechnungen usw.
Im Prinzip sollte jede Software die sich paralellisieren lässt so einfach von LRB Profitieren können. OB das jetzt dem Anwender viel Bringt sei erstmal dahingestellt, aber allein die Möglichkeit ist interessant.
Man kann da ja zweierlei Dinge vermuten, entweder will Intel im GPU Geschäfft unbedingt mitmischen, weis der Teufel warum und nimmt deswegen der Einfachheit halber eben vorhandene Technik in dem Sinne, oder Intel sieht einfach die Möglichkeiten derzeitiger x86 Hardware für so groß, das es eben auch im GPU Bereich Punkte bringen kann.
Aber du hast schon recht, die Möglichkeit ist interessant, zumindest auf den ersten Blick, sieht man aber ein wenig weiter, kommt eben der Nutzbarkeitsfaktor mit ins Bild. Eine hoch interessante Möglichkeit ist solange interessant, wie man davon profitieren kann. Wenn letzteres nicht eintritt wird sie untergehen.
Und wie oben schon gesagt, die Möglichkeit Sachen auf die GPU zu übertragen ist zwar gut, aber man darf es dort in jedemfall nicht übertreiben, sonst kommt es wiederum zu dem Effekt, wie es die CPU derzeit macht. Sie kann quasi alles, aber eben nur recht langsam im Vergleich zu speziellen Recheneinheiten für spezielle Dinge.
Nur mal rumgesponnen, eine Larrabee Karte als CPU Ersatz + ne billig 5€ PCI Karte für die Bildausgabe und schon stehen wir wieder an dem Punkt, das die CPU alles macht
Die Erschaffung dedizierter Grafikhardware ist ein guter Schritt damals gewesen, aber mir scheint es so, als wolle Intel mit dem Larrabee Projekt irgendwie wieder zurück...
Wenn man mal weiter denkt, wenn x86 vollständig x86 kompatible GPUs sich im HighEnd Bereich auch etablieren könnten, und diese in normaler x86 Software auch gut da stehen, warum dann diese nicht auch als CPU Ersatz einsetzen...
Du musst bedenken, dass x86-Kompatibilität noch lange keine taugliche CPU macht.
Da hast schon recht, aber es ist ein erster Anfang...
Und ich hab das ganze ja auch mit "ich spinne mal rum" und "ich spinne mal weiter" gekennzeichnet.
Aber da brauch doch nur mal jemand richtig nach schreien und schon pflanzen die da noch weitere Sachen mit ein...
Ich denke mal wir sollten sowieso erstmal abwarten, wie Larrabee überhaupt ankommt. Wenn die Leistung zum Release schon wieder zu weit zurück liegt, dann nutzt auch der beste Ansatz nix...
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Ich denke mal wir sollten sowieso erstmal abwarten, wie Larrabee überhaupt ankommt. Wenn die Leistung zum Release schon wieder zu weit zurück liegt, dann nutzt auch der beste Ansatz nix...
Das ist so ne Sache. Ich denke mal das die Cores in diesem Fall wohl ähnlich gut oder evtl sogar besser skalieren als Shadereinheiten. Intel hätte somit auch die Möglichkeit die Anzahl der Cores zu erweitern und somit passende Leistung zum Release zur Verfügung zu stellen. Ist wird wohl nen Grund habe warum die Anzahl der Cores noch nicht wirklich festgelegt ist.
Aber abwarten. So wies ausschaut wird das diese Jahr eh nix mehr.
Das schon, man kann auch mit der ineffizientesten Technik bahnbrechende Leistung erzielen, aber man muss halt Kompromisse eingehen...
Ich denke dabei an die Leistungsaufnahme und die Abwärme von so einem Teil.
So ohne weiteres einfach mal die Leistung verdoppeln wird sicher bei sowas schwer werden...
Wie gesagt, ich sehe das als Nachteil an, hier fast alles via Software zu regeln, weil einfach die Software Lösung erheblich mehr Rechenleistung brauch, als speziell auf etwas zugeschnittene Hardwarelösungen.
Leider sind aber über Stromverbrauch bzw. Abwärme und Leistung an sich noch so gar keine Fakten bekannt...
Aber du hast schon recht, dieses Jahr wird da sicher nix mehr kommen.
War Intel eigentlich auf der Cebit mit dabei? Haben die was gezeigt?
Ich denke dabei an die Leistungsaufnahme und die Abwärme von so einem Teil.
So ohne weiteres einfach mal die Leistung verdoppeln wird sicher bei sowas schwer werden...
Wie gesagt, ich sehe das als Nachteil an, hier fast alles via Software zu regeln, weil einfach die Software Lösung erheblich mehr Rechenleistung brauch, als speziell auf etwas zugeschnittene Hardwarelösungen.
Leider sind aber über Stromverbrauch bzw. Abwärme und Leistung an sich noch so gar keine Fakten bekannt...
Aber du hast schon recht, dieses Jahr wird da sicher nix mehr kommen.
War Intel eigentlich auf der Cebit mit dabei? Haben die was gezeigt?
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
War Intel eigentlich auf der Cebit mit dabei? Haben die was gezeigt?
Der 32nm Low-End war auf ner IDF oder?
Da in den letzten Tagen häufig immer wieder das Thema VRam in verschiedensten Threads aufkam, bin ich der Meinung, man sollte das ganze hier mal ein wenig zusammen fassen und vor allem, einige Erklärungen herrausfinden...
Mir gehts hier nicht um die Generelle Größe des VRams und auch nicht darum, wie viel ist wo wichtig, sondern zum Beispiel um das Thema, warum brechen NV G92 und G200 GPUs bei 8xAA überdurchschnittlich stark ein, und warum ist das bei AMD GPUs nicht der Fall.
Viel liest man, das liegt am VRam bzw. am Speichermanagement von NV, ich bin der Meinung, dem ist nicht so...
Erstens, gibts darüber soweit ich weis keine Reviews im Netz und zweitens, wäre es für mich auch äußerst unlogisch, warum das so sein sollte, vor allem, weil Karten mit 512MB Speicher idR eben fast im gleichen Maße wegbrechen wie Karten mit 1GB. Und das macht die Sache mit dem VRam schon ein wenig unlogisch...
Aus Mangel an aktueller NV Technik bin ich hierfür aber auf eure Hilfe angewiesen...
Das ganze soll folgendermaßen ablaufen, getestet werden sollen Games (logisch) aber nicht in den Benchtools sondern in realen Gamesettings.
Max. Details mit normaler Auflösung, einmal mit 4xAA und einmal mit 8xAA, nebenbei soll ein VRam Auslastungstest mitlaufen, im Rivatuner und ein Frameverlaufsdiagramm erstellt werden, mit Fraps.
Das ganze logischerweise mit Windows XP... (weil keine VRam Auslastung mit Vista machbar ist)
Also falls jemand Lust hat und auch dem Problem ein wenig auf die Schliche kommen will, der kann sich einfach mal melden...
Ich hoffe somit ein wenig Klarheit in die Materie bringen zu können...
Ich werde etwaige Tests dann mit meiner AMD Karte nachtesten, sofern das möglich ist, um den Vergleich zu AMD zu schaffen.
Die erreichten FPS spielen mir hierbei gar nicht mal so die Rolle, sondern wie gesagt eher der VRam Verbrauchswert und die FPS Einbrüche in Form von Nachladerucklern.
Mir gehts hier nicht um die Generelle Größe des VRams und auch nicht darum, wie viel ist wo wichtig, sondern zum Beispiel um das Thema, warum brechen NV G92 und G200 GPUs bei 8xAA überdurchschnittlich stark ein, und warum ist das bei AMD GPUs nicht der Fall.
Viel liest man, das liegt am VRam bzw. am Speichermanagement von NV, ich bin der Meinung, dem ist nicht so...
Erstens, gibts darüber soweit ich weis keine Reviews im Netz und zweitens, wäre es für mich auch äußerst unlogisch, warum das so sein sollte, vor allem, weil Karten mit 512MB Speicher idR eben fast im gleichen Maße wegbrechen wie Karten mit 1GB. Und das macht die Sache mit dem VRam schon ein wenig unlogisch...
Aus Mangel an aktueller NV Technik bin ich hierfür aber auf eure Hilfe angewiesen...
Das ganze soll folgendermaßen ablaufen, getestet werden sollen Games (logisch) aber nicht in den Benchtools sondern in realen Gamesettings.
Max. Details mit normaler Auflösung, einmal mit 4xAA und einmal mit 8xAA, nebenbei soll ein VRam Auslastungstest mitlaufen, im Rivatuner und ein Frameverlaufsdiagramm erstellt werden, mit Fraps.
Das ganze logischerweise mit Windows XP... (weil keine VRam Auslastung mit Vista machbar ist)
Also falls jemand Lust hat und auch dem Problem ein wenig auf die Schliche kommen will, der kann sich einfach mal melden...
Ich hoffe somit ein wenig Klarheit in die Materie bringen zu können...
Ich werde etwaige Tests dann mit meiner AMD Karte nachtesten, sofern das möglich ist, um den Vergleich zu AMD zu schaffen.
Die erreichten FPS spielen mir hierbei gar nicht mal so die Rolle, sondern wie gesagt eher der VRam Verbrauchswert und die FPS Einbrüche in Form von Nachladerucklern.
Zuletzt bearbeitet:
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Mir gehts hier nicht um die Generelle Größe des VRams und auch nicht darum, wie viel ist wo wichtig, sondern zum Beispiel um das Thema, warum brechen NV G92 und G200 GPUs bei 8xAA überdurchschnittlich stark ein, und warum ist das bei AMD GPUs nicht der Fall.
Da gabs vor Kurzem nen guten Artikel bei Hardwareinfos:
http://www.hardware-infos.com/tests.php?test=61&seite=1
Es fällt auf das der unterschied beim Fps-Einbruch nicht unbedingt groß ist, allerdings sind bei manchen Engines die einbruchraten des ATi Chips sehr gering. Entweder sind die Treiber und die Fähigkeiten der Karte unglaublich gut darin mit AA umzugehen oder es wurde gemogelt... Vor allem Lost Planet fällt hier ziemlich aus dem Rahmen.
Ja genau sowas, wobei mich wie gesagt nicht die explizite FPS Rate am Ende interessiert, sondern eher, das warum...
Sollte es doch am VRam liegen? So wie manche hier im Forum immer sagen? (denn das kann ich mir so gut wie nicht vorstellen)
Sollte es doch am VRam liegen? So wie manche hier im Forum immer sagen? (denn das kann ich mir so gut wie nicht vorstellen)
So hier noch mal was zum Thema mit der PCIe Anbindung der 4870X2,
da ja manche denken die Karte sei mit 2x x8 Lanes angebunden
Dem ist nicht so, die Karte bezieht ja die Daten über die PCIe Schnittstelle mit einer x16 Anbindung. Der Brückenchip teilt diese Daten auf beide GPUs in voller Bandbreite auf. Da die beiden GPUs nicht über die PCIe Schnittstelle miteinander kommunizieren müssen um die Daten auszutauschen bleibt auch alles auf der x16 Lanes Anbindung. Die Karte kann weiterhin mit der vollen Bandbreite arbeiten.
Hier mal eine Schemata dazu ->
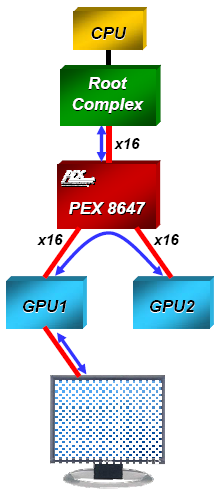
da ja manche denken die Karte sei mit 2x x8 Lanes angebunden
Dem ist nicht so, die Karte bezieht ja die Daten über die PCIe Schnittstelle mit einer x16 Anbindung. Der Brückenchip teilt diese Daten auf beide GPUs in voller Bandbreite auf. Da die beiden GPUs nicht über die PCIe Schnittstelle miteinander kommunizieren müssen um die Daten auszutauschen bleibt auch alles auf der x16 Lanes Anbindung. Die Karte kann weiterhin mit der vollen Bandbreite arbeiten.
Hier mal eine Schemata dazu ->
Die ankommenden 16 PCIe-Lanes teilt der PEX 8647 auf zwei x16-Signale auf und leitet diese zu den beiden RV770-GPUs. Somit gibt es keinen Bandbreitenverlust, obwohl das Mainboard auf einem Slot nur 16 Lanes zur Verfügung stellen kann.
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Sehr interessant Le_Frog.
Meines Wissens nach sollte sich da doch eh kein Problem ergeben da beide Chips mit den gleichen Daten versorgt werden. Soll heißen das sich keine höhere Menge an Daten ergibt die über die 16 Lanes des PCIe laufen müssen.
Wäre übrigens mal interessant zu erfahren in wie weit heutzutage durch Spiele oder Benchmarks oder gar GPGPU die Datenrate von PCIe 2.0 ausgenutzt wird.
Immerhin steht bei PCIe 2.0 mit 16 Lanes eine Datenrate von: 16 * 500 MB/s = 8 GB/s zur Verfügung.
Meines Wissens nach sollte sich da doch eh kein Problem ergeben da beide Chips mit den gleichen Daten versorgt werden. Soll heißen das sich keine höhere Menge an Daten ergibt die über die 16 Lanes des PCIe laufen müssen.
Wäre übrigens mal interessant zu erfahren in wie weit heutzutage durch Spiele oder Benchmarks oder gar GPGPU die Datenrate von PCIe 2.0 ausgenutzt wird.
Immerhin steht bei PCIe 2.0 mit 16 Lanes eine Datenrate von: 16 * 500 MB/s = 8 GB/s zur Verfügung.
Mhhh ich weis nicht so recht, aber irgendwie kann ich das gar nicht so recht glauben...
Und ne, ich denke nicht das die Karte mit 2x8x angebunden ist, sondern ihr im extremfall maximal 2x8x zur verfügung stehen...
Mal als einfaches Gedankenbeispiel, was passiert bei 4 Monitoren? Je 2 pro GPU, alle 4 stellen ein unterschiedliches Bild dar, kann mir kaum vorstellen, das die Nutzdaten vom Rest PC jeweils immer komplett zu beiden GPUs geschickt werden obwohl diese nur die hälfte der Daten brauchen sollten!?
Weis nicht, aber irgendwie ist das ein wenig unlogisch...
Da muss es doch irgendwo in den weiten des INet Infos drüber geben?
Und ne, ich denke nicht das die Karte mit 2x8x angebunden ist, sondern ihr im extremfall maximal 2x8x zur verfügung stehen...
Mal als einfaches Gedankenbeispiel, was passiert bei 4 Monitoren? Je 2 pro GPU, alle 4 stellen ein unterschiedliches Bild dar, kann mir kaum vorstellen, das die Nutzdaten vom Rest PC jeweils immer komplett zu beiden GPUs geschickt werden obwohl diese nur die hälfte der Daten brauchen sollten!?
Weis nicht, aber irgendwie ist das ein wenig unlogisch...
Da muss es doch irgendwo in den weiten des INet Infos drüber geben?
Mh ich weiß irgendwie grade nicht wo du hinwillst 
Was haben den die 4 Monitore mit dem Rest vom System zu tun? Die Grafikkarte übernimmt doch Verwaltung der Bilddarstellung, wie sie das nun aufteilt hat doch nichts mit dem restlichem Bussystem vom Rechner zu tun?!
Das Programm gibt ja vor welche Daten zur Berechnung kommen , diese werden an die Graka geschickt und die übernimmt die Verwaltung selber ( Chiplogik und Treibersteuerung) ich wüßte nicht warum da Engpässe entstehen sollen? Auch die Bandbreite welche die PCIe 2.0 Schnittstellen zur verfügung stellen, wird von der aktuellen Kartengeneration immer noch nicht ausgelastet.
Oder stehe ich grade aufn Schlauch?
Was haben den die 4 Monitore mit dem Rest vom System zu tun? Die Grafikkarte übernimmt doch Verwaltung der Bilddarstellung, wie sie das nun aufteilt hat doch nichts mit dem restlichem Bussystem vom Rechner zu tun?!
Das Programm gibt ja vor welche Daten zur Berechnung kommen , diese werden an die Graka geschickt und die übernimmt die Verwaltung selber ( Chiplogik und Treibersteuerung) ich wüßte nicht warum da Engpässe entstehen sollen? Auch die Bandbreite welche die PCIe 2.0 Schnittstellen zur verfügung stellen, wird von der aktuellen Kartengeneration immer noch nicht ausgelastet.
Oder stehe ich grade aufn Schlauch?
Zuletzt bearbeitet:
Die Daten werden an die GPU geschickt, und im Falle der X2 sind ja es 2 GPUs, sprich die Daten werden dann an die jeweilige GPU geschickt.
Was im Falle der X2, wenn jede GPU die gleichen Daten erhalten würde, dazu führen müsste, das beide GPUs mit Daten versorgt werden, die eigentlich für sie gar nicht zu gebrauchen sind...
Da das ganze ja nach wie vor auf Software aufbaut, bestimmt die Software maßgeblich, welche GPU welche Daten zum Berechnen bekommt. Und das mein ich, kann mir kaum vorstellen, das die kompletten Daten jeweils an beide GPUs geschickt werden, obwohl diese nur je einen Teil davon ausführen.
Ich meine, es bekommt nach wie vor nur die GPU die Daten, welche sie auch brauch, und das würde bedeuten, bei gleichzeitiger Übertragung der Daten an beide GPUs müssen sich beide die Bandbreite von 16x Lanes des PCIe Slot teilen, sprich 2x8x...
Des weiteren wäre mir keine Hardwarelogik Einheit bekannt, welche die Daten intelligent auf die GPUs aufteilt und somit das nur einmalige Senden von Daten möglich machen würde...
Aber mal ne andere Betrachtungsweise, wenn man mal sieht, beide GPUs tauschen intern über die PCIe Anbindung Daten aus, sprich ein Teil der Bandbreite von PCIe ist sowieso schon in beanspruchung, eventuell macht tut es der ganzen Sache gar keinen Abruch, wenn nur ein 16x Slot an der Karte hängt, weil die beiden GPUs ja schon Bandbreite für die Kommunikation untereinander beanspruchen.
Bei 2 Einzellkarten geschieht diese Kommunikation ja ebenfalls nur eben über den Umweg des PCIe Slots über den Chipsatz...
Was im Falle der X2, wenn jede GPU die gleichen Daten erhalten würde, dazu führen müsste, das beide GPUs mit Daten versorgt werden, die eigentlich für sie gar nicht zu gebrauchen sind...
Da das ganze ja nach wie vor auf Software aufbaut, bestimmt die Software maßgeblich, welche GPU welche Daten zum Berechnen bekommt. Und das mein ich, kann mir kaum vorstellen, das die kompletten Daten jeweils an beide GPUs geschickt werden, obwohl diese nur je einen Teil davon ausführen.
Ich meine, es bekommt nach wie vor nur die GPU die Daten, welche sie auch brauch, und das würde bedeuten, bei gleichzeitiger Übertragung der Daten an beide GPUs müssen sich beide die Bandbreite von 16x Lanes des PCIe Slot teilen, sprich 2x8x...
Des weiteren wäre mir keine Hardwarelogik Einheit bekannt, welche die Daten intelligent auf die GPUs aufteilt und somit das nur einmalige Senden von Daten möglich machen würde...
Aber mal ne andere Betrachtungsweise, wenn man mal sieht, beide GPUs tauschen intern über die PCIe Anbindung Daten aus, sprich ein Teil der Bandbreite von PCIe ist sowieso schon in beanspruchung, eventuell macht tut es der ganzen Sache gar keinen Abruch, wenn nur ein 16x Slot an der Karte hängt, weil die beiden GPUs ja schon Bandbreite für die Kommunikation untereinander beanspruchen.
Bei 2 Einzellkarten geschieht diese Kommunikation ja ebenfalls nur eben über den Umweg des PCIe Slots über den Chipsatz...
Zuletzt bearbeitet:
Neurosphere
Enthusiast
- Mitglied seit
- 06.11.2008
- Beiträge
- 4.324
Naja, wenn wir mal bei einem Monitor bleiben sollten die Daten dank AFR doch eigentlich bei beiden Karten die Selben sein die im VRam liegen.
Von daher berechnen beide GPUs im Prinzip das selbe, da ich ja von mind 25 FPS ausgehe brauchen beide GPUs daher auch die gleichen Daten über Geometry, Texturen etc...
Von daher berechnen beide GPUs im Prinzip das selbe, da ich ja von mind 25 FPS ausgehe brauchen beide GPUs daher auch die gleichen Daten über Geometry, Texturen etc...
Naja, wenn wir mal bei einem Monitor bleiben sollten die Daten dank AFR doch eigentlich bei beiden Karten die Selben sein die im VRam liegen.
Von daher berechnen beide GPUs im Prinzip das selbe, da ich ja von mind 25 FPS ausgehe brauchen beide GPUs daher auch die gleichen Daten über Geometry, Texturen etc...
Du hast schon recht, bei AFR schon. Man kann ja aber den CF Modus mehr oder weniger auch ausschalten
Und was passiert dann? Irgendwie müsste in dem Fall ja eine Logik Vorhanden sein, welche die Daten auf die GPUs aufteilt und das gibts meines wissens nach nicht. Es werden also weiterhin alle Daten an beide GPUs gesendet, unabhängig von die nun gebraucht werden oder nicht.
Oder aber die Daten wandern doppelt über den Slot, mit besagtem Nachteil von der Bandbreitenteilung.
Hehe Paul
Na klar haben beide CPUs die gleichen Daten Sonst hätte die Karte ja auch 2GB nutzbaren Ram aber dem ist ja nicht so, beide GPUs die gleichen Daten zur Bildberechnung dann werden die je nach Modus gesplittet und dargestellt darum ja auch die Microruckler Problematik.
Und wie kommst du darauf das die beiden GPUs über den PCIe Schnittstelle kommunizieren? Dafür haben sie doch den Brückchip und bei der 4000er hätten sie sogar theoretisch noch den Sideport wenn dieser aktiviert wäre. Was nicht nötig ist da die Bandbreite noch mehr als ausreichend ist.
Welches Render Modus benutzt wird ist ja eigentlich auch egal, es werden halt nur die Bilder zur Berechnung anders aufgeteilt, das erhöht aber nicht die Datenmenge, der Treiber gibt halt nur vor wie das Bild dann aufzuteilen ist bzw welche GPU das erste, zweite, dritte oder vierte Bild zu rendern hat.
Na klar haben beide CPUs die gleichen Daten
Sonst hätte die Karte ja auch 2GB nutzbaren Ram aber dem ist ja nicht so, beide GPUs die gleichen Daten zur Bildberechnung dann werden die je nach Modus gesplittet und dargestellt darum ja auch die Microruckler Problematik.Und wie kommst du darauf das die beiden GPUs über den PCIe Schnittstelle kommunizieren? Dafür haben sie doch den Brückchip und bei der 4000er hätten sie sogar theoretisch noch den Sideport wenn dieser aktiviert wäre. Was nicht nötig ist da die Bandbreite noch mehr als ausreichend ist.
Welches Render Modus benutzt wird ist ja eigentlich auch egal, es werden halt nur die Bilder zur Berechnung anders aufgeteilt, das erhöht aber nicht die Datenmenge, der Treiber gibt halt nur vor wie das Bild dann aufzuteilen ist bzw welche GPU das erste, zweite, dritte oder vierte Bild zu rendern hat.
Anhänge
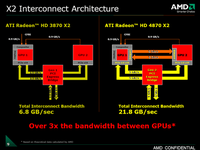
Zuletzt bearbeitet: