Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Komme mit gleichem cpu auf 9.256 im Durchschnitt ich denke dein IF geht in die Fehlercorrektur. versuch mal 2067. Sisoftsandra interthreadtest ist zum ausloten auch noch ein test um die core latency zu messen
Kann es auch sein, das PYPRime auch CPU-Takt-Abhängigkeit hat? Ich habe bei mir einen negativen Offset von 150 Mhz drin. Könnte das evtl. die Differenz erklären?
Ja habe es mit ropbench auf den effektiven Takt optimiert. Wenn ich z.b auf 2100 und mehr gehe hab ich auch 9.5 in pyprime. In microbench sehe ich auch fclk throttle im relevantem Bereich. Veii ist ja paar post voher schon drauf eingegangen. Deshalb fahr ich aktuell mit 2066 am besten. Auch wenn Veii meint dass bei non 3D cache cpu if takt viel bringt. Aber bei mir ist aktuell 2067 Ende der Fahnenstange
Ich habe jetzt mal weitere Tests gemacht, um das mit der Differenz mit unseren ähnlichen Systemen in PyPrime zu verstehen.
Du nutzt ja Windows 10 wie ich das verstanden habe. Bei mir ist es Windows 11. Bei den systemeigenen Backgroundprozessen und -diensten ist Windows 11 leider ein Rückschritt, da ein frisches Windows 11 ohne Zusatzprogramme schon deutlich über 130 Prozesse laufen hat. Hier möchte ich nur begrenzt etwas manuell beenden. Um diesen Unterschied dennoch etwas entschärfen zu können, habe ich einen Test im abgesicherten Modus (inkl. Netzwerktreiber) durchgeführt. Dabei laufen dann 62 Prozesse. Zudem habe ich für diesen Test meine CPU Einstellungen im Bios umgestellt, sodass ich keinen negativen Taktoffset mehr habe.
Dabei kam folgendes Ergebnis heraus:
Das bestätigt zumindest, dass PyPrime vom Maximaltakt (Single-thread??) beeinflusst wird. Dies ist aber für mich nicht so wichtig. Darauf komme ich gleich noch.
Die letzten etwa 50ms zu z.B. @LuxSkywalker sind dann einfach so 🤷♂️ Ich habe keine CO-Anpassung mit ROPBench o.ä. gemacht, vielleicht würde das nochmal etwas bringen Aber den Aufwand möchte ich mir eigentlich sparen.
Grund für mein CPU-Setup und dem 150 MHz negativen Taktoffset liegt einerseits darin begründet, dass ich bei der CPU-Lotterie kein so gutes Los gezogen habe. Das mache ich daran fest, weil die CPU im Ursprungszustand eine Taktdifferenz von ca. 200 Mhz zwischen den CCDs aufweist. Um dies etwas zu glätten, habe ich ne Zeit lang diverse Tests gemacht. Als bestes Ergebnis für meinen Fall hat sich herausgestellt, auf ein möglichst hohes CO Offset zu kommen. Bei mir ist das -26 und -28. Diese Werte erreicht man in der Regel nicht, da für die höchsten Taktstufen einfach viel Spannung notwendig ist. Diese hohe Spannung wiederum führt aber dazu, dass die CPU gedrosselt wird. Dies führt dann schon zum zweiten, für mich noch wesentlich wichtigeren Grund: Ich benötige Multi-Core-Leistung fürs encoden und rendern, dafür verzichte ich gerne auf Single-thread-Leistung.
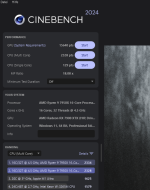
Hier im Cinebench 2024 gut zu sehen:
2311 CO -18 all core OHNE Taktoffset.
2333 CO -24 all core mit 100 MHz negativen Taktoffset
2349 CO -26/-28 pro CCD mit 150 MHz negativen Taktoffset
Meine Einstellungen sind prime erprobt. Als sehr guter Stabilitätstest hat sich Cinebench R23 erwiesen. Denn dieser reagiert sehr empfindlich, wenn er deutlich über eine Stunde läuft (ideal >2 Stunden).
Kannst du die Cinebench (R23 + 2024) mal bei dir checken als Vergleich, wie die CPU so liegt? Wäre mal gut zu wissen, denn du hast dein System auch sehr stark optimiert.
Vielleicht mache ich mich ja dann doch nochmal ans Optimieren der CPU
RAM hake ich für mich jetzt erstmal ab, da ich mit dem Ergebnis, welches ich mit der Hilfe dieses Forums erreicht habe, echt sehr zufrieden bin.
Bei meinen beiden CCDs ist auch ein Taktunterschied von 150MHz vorhanden
Ich glaube das AMD da bewusst einen guten CCD mit einem weniger guten CCD zusammen setzt.
Der maximale Turbo wird ja auch nur für einen einzigen Kern garantiert und das ja auch nur solange die restlichen Vorgaben wie Temperatur etc im vorgegebenen Rahmen sind
Btw. meine RAM (Sub)Timings sind bis aufs letzte optimiert
Was ich sagen kann: AIDA Latenz und PyPrime korreliert nach meinen Beobachtungen
Wenn die Latenz in AIDA schön niedrig ist siehst du das auf meinem System sofort auch in PyPrime
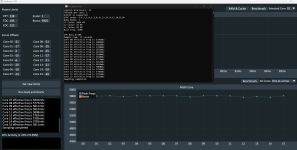
@z3r0.c0m Anbei mal ein paar Werte von mir. System läuft auf win11.
@RedF habe das Sd, dd Thema in unserer Liste überarbeite. Man kann jetzt über einen Wert 0 oder 1 dann zwischen single sided und dual sided switchen. Habe auch die zentiming Seite darauf hin angepasst.
Gibts schon was neues zum Ropbench?
Ich bin mir unsicher ob du die TWR Formel korrekt umgesetzt hast. Veii sagt ja nur das twr wie tras einen Buffer braucht. twr= 12+x+8
".....Basically tWR should never be lower than tWTR_L
And tWR should never be lower than RTP + WTRA (X).
Soo tWR should never be lower than 12+X (+BC8 aka +8). Depends when tWR is needed.
In the most simplified way possible, ignoring most "but if" variables.
= don't go under value 24. Optimally never under value 20, because that's just silly and begs for trouble.
Because things are not only working in BC8 mode,
The correct correct rule is not under 48, but 24 is somewhat an option."
@z3r0.c0m Anbei mal ein paar Werte von mir. System läuft auf win11.
@RedF habe das Sd, dd Thema in unserer Liste überarbeite. Man kann jetzt über einen Wert 0 oder 1 dann zwischen single sided und dual sided switchen. Habe auch die zentiming Seite darauf hin angepasst.
Gibts schon was neues zum Ropbench?
Ich bin mir unsicher ob wir du die TWR Formel korrekt umgesetzt hast. Veii sagt ja nur das twr wie tras einen Buffer braucht. twr= 12+x+8 wir wissen blos nicht was x ist da WTRA nicht ausgelesen werden kann.
Des weiteren hat er folgendes gesagt
".....Basically tWR should never be lower than tWTR_L
And tWR should never be lower than RTP + WTRA (X).
Soo tWR should never be lower than 12+X (+BC8 aka +8). Depends when tWR is needed.
In the most simplified way possible, ignoring most "but if" variables.
= don't go under value 24. Optimally never under value 20, because that's just silly and begs for trouble.
Because things are not only working in BC8 mode,
The correct correct rule is not under 48, but 24 is somewhat an option."
@z3r0.c0m Anbei mal ein paar Werte von mir. System läuft auf win11.
@RedF habe das Sd, dd Thema in unserer Liste überarbeite. Man kann jetzt über einen Wert 0 oder 1 dann zwischen single sided und dual sided switchen. Habe auch die zentiming Seite darauf hin angepasst.
Gibts schon was neues zum Ropbench?
Ich bin mir unsicher ob wir du die TWR Formel korrekt umgesetzt hast. Veii sagt ja nur das twr wie tras einen Buffer braucht. twr= 12+x+8 wir wissen blos nicht was x ist da WTRA nicht ausgelesen werden kann.
Des weiteren hat er folgendes gesagt
".....Basically tWR should never be lower than tWTR_L
And tWR should never be lower than RTP + WTRA (X).
Soo tWR should never be lower than 12+X (+BC8 aka +8). Depends when tWR is needed.
In the most simplified way possible, ignoring most "but if" variables.
= don't go under value 24. Optimally never under value 20, because that's just silly and begs for trouble.
Because things are not only working in BC8 mode,
The correct correct rule is not under 48, but 24 is somewhat an option."
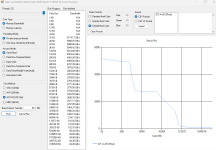
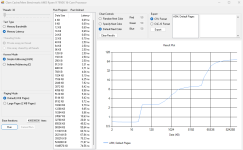
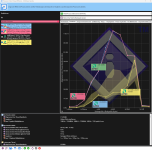
Mit Ropbench kann man mit einem startbefehl statt der peak clock die effektive clock über Zeitraum x zb. 20 sekunden messen. (Siehe readme) Habe so lange co gesenkt. Bis dort kein mhz gewinn durch weiteres senken möglich war. Veii hat in einem früheren Post empfohlen sich den oberen chart anzuschauen. Wenn da im 1 ms Bereich größere Einbrüche geschehen dann ist auch Ende der Fahnenstange. Er meinte auch evtl lässt sich auch über die varianzen im intercore chart etwas ableiten. Muss es mir mal die Tage anschauen. Muss man testen. Empfehlungen sind echt schwer weil das amd system so gut korrigiert.
Mit Ropbench kann man mit einem startbefehl statt der peak clock die effektive clock über Zeitraum x zb. 20 sekunden messen. (Siehe readme) Habe so lange co gesenkt. Bis dort kein mhz gewinn durch weiteres senken möglich war. Veii hat in einem früheren Post empfohlen sich den oberen chart anzuschauen. Wenn da im 1 ms Bereich größere Einbrüche geschehen dann ist auch Ende der Fahnenstange. Er meinte auch evtl lässt sich auch über die varianzen im intercore chart etwas ableiten. Muss es mir mal die Tage anschauen. Muss man testen. Empfehlungen sind echt schwer weil das amd system so gut korrigiert.
wenn du primär renderst, solltest du vielleicht den Renderer gleichzeitig anschmeißen und gucken, dass es unter avx last nicht zu clock stretching kommt, da Ropbench nur sehr leicht belastet.
Es gibt 4 variablen
Ich konnte "am Sontag ?" den Post nicht fertigstellen.
Ich muss es mir genauer anschauen.
Eigentlich hat die alternativ-formel
Zu stimmen, bloß sind das für nicht AP refreshes.
Und es sind für writes nop write+BC8 nop read
Unsere WR werden nach dem write ausgerechnet bevor der Read startet
nicht nach dem Read
Jedoch ist der 2. angereihte write um 8 clock verschoben
Ich werde es mir genauer anschauen müssen.
Es gibt 4 korrekte Werte, je nach syncronization.
WR never under WTRL stimmt
RAS-RCD stimmt teils
Write past RTP + WTRA or WTRL + another BC8 clock , ~ ist ebenso korrekt
Sogar genauer.
Hier ist der Unterschied zwischen CAS+WTRL+BC8
// ^ WR von dem ehmaligen read startend, und nach beendeten Read abfangendd
Ebenso richtig wie CWL + BC8 + WTRA + RTP
Wobei für diese Methode FGR benötigt wird, damit timings sich nicht überlappen und der Read (start) in dem anderen Subchannel passiert
^ Etwas das wir mir soweit bekannt immer noch nicht unterstützen. Kein FGR, kein RFCpb.
Gib mir etwas Zeit und ich finde es herraus, was für uns am besten passt.
Soweit kannst du es zu CAS+WTRL+8 ersetzen, und wir schauen dann weiter wie (half WTRS) darauf wirkt.
Der erste Write ist instant. Der nächste write ist um +8 clock verzögert. Gleichzeitig aber geschieht ein Read auf einem anderen Ort.
Somit überlappen sie sich nicht
wenn du primär renderst, solltest du vielleicht den Renderer gleichzeitig anschmeißen und gucken, dass es unter avx last nicht zu clock stretching kommt, da Ropbench nur sehr leicht belastet.
Bei einer boost Ramp-up Time von 1ms , worin die besten tools eine API mit einer updatezeit von 30ms Nutzen, auf Pooling 500ms minimum
// Hydra nutzt RSMU mit einer update-zeit von ~10ms.
Kannst du bei 1/30 , bzw 1/500 samples wenig auslesen.
Clock Stretching existiert nicht.
Es gibt clock gating und voltage gating.
Beides geschieht weitaus schneller als jegliche Tools das auslesen können.
RopBench its kein SSE load.
Es verwendet AMDs eigene HardwareInstructions um die CPU auf der Boosting-state zu halten.
Bei schwerer Last gibt es Voltage Throttling, aber kein Strap-Stretching.
Bei schwerer Last welche alle Kerne ladet, wird hinunter bis zu dem schwächsten Kern getacktet. Danach setzen Thermal und Amperage Guardbands ein.
Da die Kerne nur eine Spannungsversorgung haben. Zwar bekommt jeder Kern durch das LDO eine leicht abgeänderte Spannung als der Input
Jedoch bleibt es ein Input.
Somit haben sie auch Frequency-Delta's in CCDs und zwischen CCDs bzw (legacy) CCX einzuhalten.
Sie können keinen individuellen Clock rennen wie bei Intels Seite.
wenn du primär renderst, solltest du vielleicht den Renderer gleichzeitig anschmeißen und gucken, dass es unter avx last nicht zu clock stretching kommt, da Ropbench nur sehr leicht belastet.
Mein größtes Problem beim Ausloten der besten CPU Einstellung war nicht der Takt bei sehr hoher Belastung.
Meine Erfahrung diesbezüglich war, dass ich unter heavy load schon stabil war, aber bei mixed load, wenn der Takt höher ist als bei max. Belastung, dort war es zum Haare ausreißen. Daher war das Mittel der Wahl dann einfach den Takt zu begrenzen, denn beim Rendern erreicht dieser nie über 5,5 Ghz auf allen Kernen. Deswegen tut mir das auch nicht weh. Aber man hat halt im Hinterkopf, dass da noch ungenutztes Potenzial liegt, wenn auch nicht so viel.
Mal sehen, vielleicht mache ich mich doch mal dran und schau mir das mit ROPBench mal an.
@Wolf87 In C51 ist auch ein tCL, welches manuell eingegeben werden kann. Kann man das nicht aus B4 übernehmen? Hab jetzt etwas gesucht bis ich mein abweichendes tCWL im Zentimings Screenshot nachvollziehen konnte. Dort verwendet @RedF nämlich das tCWL aus D51.
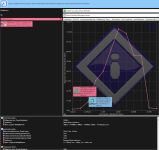
Danke für den Hinweis. Habe die Edit sachen anderster gefärbt dann ist es im Dark Modus besser lesbar. Jetzt funktioniert auch der switch für single sided und dual sided sorry hatte vergessen die Spalte freizugeben. Anbei aus Ropbench intercore chart 7950x
Danke für den Hinweis. Habe die Edit sachen anderster gefärbt dann ist es im Dark Modus besser lesbar. Jetzt funktioniert auch der switch für single sided und dual sided sorry hatte vergessen die Spalte freizugeben. Anbei aus Ropbench intercore chart 7950x
Ja da scheint irgendwas mit dem Programm zu sein. Bei Si soft Sandra ist die Range 7,8-61,4ns. @Veii zur Info aktuell lässt sich bei Asus twr nur in 6 Schritten beginnend ab 48 zu konfigurieren. Was ich so von anderen gelesen habe sieht es bei den anderen Boards ähnlich aus.
Ja da scheint irgendwas mit dem Programm zu sein. Bei Si soft Sandra ist die Range 7,8-61,4ns. @Veii zur Info aktuell lässt sich bei Asus twr nur in 6 Schritten beginnend ab 48 zu konfigurieren. Was ich so von anderen gelesen habe sieht es bei den anderen Boards ähnlich aus.
Ja da scheint irgendwas mit dem Programm zu sein. Bei Si soft Sandra ist die Range 7,8-61,4ns. @Veii zur Info aktuell lässt sich bei Asus twr nur in 6 Schritten beginnend ab 48 zu konfigurieren. Was ich so von anderen gelesen habe sieht es bei den anderen Boards ähnlich aus.
Was genau kann ich davon ableiten? Gibt es Referenzwerte, von denen man ein "gut" oder "nicht gut" ableiten kann? Ich habe jetzt auch nochmal diesen Check gemacht, nachdem ich gestern etwas mit ROPBench experimentiert habe. Die Werte sind etwas besser als vorher, aber ohne Maßstab bzw. Referenzwerte ist mir keine Einschätzung möglich.
Kann es sein, das das STRIX B650E-E besser läuft als das Hero?
Mir kommt es so vor, als ob das Gene so wie das Strix X670E-E und auch Asrock Taichi (sowohl B650e als auch X670e) die einzigen Boards sind die da so richtig mithalten können oder?
Sind das auch die im Moment Stressfreiesten Boards?
Nö, RAM ist nie das Problem, das Board auch nicht, sondern der IMC.
Du kannst dir das teuerste Board kaufen und der imc schafft nur 6200, dann haste ordentlich Geld versenkt.
Stressfrei sind die Boards alle, zumindest seit agesa 1.1.0.0.
Einzig die ganzen Failsafe Werte die beim RAM OC hinterlegt sind (und die fehlenden Optionen) müssten noch angegangen werden.

 Aber den Aufwand möchte ich mir eigentlich sparen.
Aber den Aufwand möchte ich mir eigentlich sparen.

")


")