Hallo,
ich habe ein Problem mit meinem Software Raid 5 bestehend aus 6 HDDs. Eine davon ist eine Spare Platte (/dev/sdb).
Das ganze muss in ein kleineres NAS mit nur 4 Bays umziehen. Dementsprechend wollte ich das Raid auf 4 HDDs schrumpfen. Das hat bis zu 99,9% auch geklappt und seitdem tut sich seit Tagen nichts mehr. Laut Syslog und dmesg liegt es an defekten Sektoren einer HDD (/dev/sdh). Das Problem ist nun, dass ich die HDD nicht als faulty markieren kann.
Sobald ich das mittels "mdadm --manage --fail /dev/md127 /dev/sdh" tue, ist das die Rückmeldung:
mdadm: set device faulty failed for /dev/sdh: Device or resource busy
Wenn ich nun die defekte HDD durch die Spare HDD ersetzen will: mdadm --manage --replace /dev/md127 /dev/sdh --with /dev/sdb
ist das das Ergebnis:
mdadm: Marked /dev/sdh (device 1 in /dev/md127) for replacement
mdadm: Failed to set /dev/sdb as preferred replacement.
Ich komme hier einfach nicht weiter und drehe mich im Kreis. Hat jemand von euch eventuell eine Idee, was ich noch tun könnte?
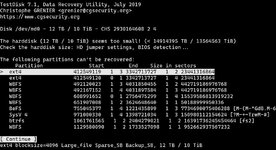
So sieht es momentan aus:
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md127 : active raid5 sdb[4](S) sdh[7] sdd[5] sda[3] sdc[2]
11720661504 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [_UUU]
[===================>.] reshape = 99.9% (3903912448/3906887168) finish=279719738.6min speed=0K/sec
unused devices: <none>
/dev/md127:
Version : 1.2
Creation Time : Fri Dec 25 09:15:04 2015
Raid Level : raid5
Array Size : 11720661504 (11177.69 GiB 12001.96 GB)
Used Dev Size : 3906887168 (3725.90 GiB 4000.65 GB)
Raid Devices : 4
Total Devices : 5
Persistence : Superblock is persistent
Update Time : Sun Oct 17 15:52:13 2021
State : clean, degraded, reshaping
Active Devices : 4
Working Devices : 5
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Reshape Status : 99% complete
Delta Devices : -1, (5->4)
Name : nas:RAID
UUID : b263b06d:11da36a5:28c4f23b:a76d50d3
Events : 13278149
Number Major Minor RaidDevice State
- 0 0 0 removed
7 8 112 1 active sync /dev/sdh
2 8 32 2 active sync /dev/sdc
3 8 0 3 active sync /dev/sda
4 8 16 - spare /dev/sdb
5 8 48 4 active sync /dev/sdd
Danke und Gruß
Kai
ich habe ein Problem mit meinem Software Raid 5 bestehend aus 6 HDDs. Eine davon ist eine Spare Platte (/dev/sdb).
Das ganze muss in ein kleineres NAS mit nur 4 Bays umziehen. Dementsprechend wollte ich das Raid auf 4 HDDs schrumpfen. Das hat bis zu 99,9% auch geklappt und seitdem tut sich seit Tagen nichts mehr. Laut Syslog und dmesg liegt es an defekten Sektoren einer HDD (/dev/sdh). Das Problem ist nun, dass ich die HDD nicht als faulty markieren kann.
Sobald ich das mittels "mdadm --manage --fail /dev/md127 /dev/sdh" tue, ist das die Rückmeldung:
mdadm: set device faulty failed for /dev/sdh: Device or resource busy
Wenn ich nun die defekte HDD durch die Spare HDD ersetzen will: mdadm --manage --replace /dev/md127 /dev/sdh --with /dev/sdb
ist das das Ergebnis:
mdadm: Marked /dev/sdh (device 1 in /dev/md127) for replacement
mdadm: Failed to set /dev/sdb as preferred replacement.
Ich komme hier einfach nicht weiter und drehe mich im Kreis. Hat jemand von euch eventuell eine Idee, was ich noch tun könnte?
So sieht es momentan aus:
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md127 : active raid5 sdb[4](S) sdh[7] sdd[5] sda[3] sdc[2]
11720661504 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [_UUU]
[===================>.] reshape = 99.9% (3903912448/3906887168) finish=279719738.6min speed=0K/sec
unused devices: <none>
/dev/md127:
Version : 1.2
Creation Time : Fri Dec 25 09:15:04 2015
Raid Level : raid5
Array Size : 11720661504 (11177.69 GiB 12001.96 GB)
Used Dev Size : 3906887168 (3725.90 GiB 4000.65 GB)
Raid Devices : 4
Total Devices : 5
Persistence : Superblock is persistent
Update Time : Sun Oct 17 15:52:13 2021
State : clean, degraded, reshaping
Active Devices : 4
Working Devices : 5
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Reshape Status : 99% complete
Delta Devices : -1, (5->4)
Name : nas:RAID
UUID : b263b06d:11da36a5:28c4f23b:a76d50d3
Events : 13278149
Number Major Minor RaidDevice State
- 0 0 0 removed
7 8 112 1 active sync /dev/sdh
2 8 32 2 active sync /dev/sdc
3 8 0 3 active sync /dev/sda
4 8 16 - spare /dev/sdb
5 8 48 4 active sync /dev/sdd
Danke und Gruß
Kai
Zuletzt bearbeitet:
 ) und beim Start des Raids folgende Rückmeldung bekommen:
) und beim Start des Raids folgende Rückmeldung bekommen: stack: 0 pid: 1916 ppid: 2 flags:0x00004000
stack: 0 pid: 1916 ppid: 2 flags:0x00004000