Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
So,
ich habe mal eine kniffelige Frage an die Experten:
Ich habe mich vor einigen Tagen (da mir napp-it nicht so gut gefallen hat) für ein debian basiertes ZFS-System mit zfs-fuse(0.7.0-10) entschieden.
Da die Daten auch verschlüsselt werden sollen, habe ich es wie folgt aufgebaut:
- 4 HDDs, jede ist einzelnt durch dmcrypt/LUKS verschlüsselt.
- Die Disks werden dann wie gewohnt nach /dev/mapper/xxx nach dem unlocken gemappt
- Auf die mapper-HDDs habe ich dann ein ZFS raidz1 angelegt.
Nach einigen Tests sagte mir die Performance nicht so zu (62Mb seq. write per bonnie++).
Habe das ashift kontrolliert und gesehen das auf dem Pool leider ashift=9 ist.
Habe den Pool destroyed und wollte ihn mit ashift=12 neu anlegen.
Leider gibt es unter der Version oder unter zfs-fuse die Option "ashift" nicht:
Meine fixe Idee war eine OI Live-CD zu booten um den zpool dort mit ashift=12 zu erstellen und exportieren, sowie dann anschließend unter Debian wieder zu importieren.
Leider geht das aber technisch nicht, da ich dort ja kein dmcrypt/LUKS zum entschlüsseln der Platten zur Verfügung habe!
Hat jemand ne Idee wie ich den Pool mit ashift=12 erstellt bekomme?
Wozu machst du ein eigenes zfs-fuse Paket wenn ZFSonLinux das Setzen von ashift nativ unterstützt?
zfs-fuse ist veraltet, relativ langsam da im Userspace ausgeführt und wird nicht mehr weiter entwickelt, die Entwickler sind bereits 2011 auf ZoL umgestiegen. Das letzte Update kam im Frühling 2011, das sind fast zwei Jahre! Ich kann daher von der Verwendung von zfs-fuse nur abraten.
Ich weiß folgendes ist eine banale frage, aber ich such mir hier nen Wolf und finde nix ...
Wo kann ich bei napp it die Einstellungen für den SMTP Server ändern? - Ich habe beim Einrichten das Passwort für den Account falsch eingegeben und würde das gerne anpassen, damit mich der Server bei Fehlern benachrichtigen kann.
Ich weiß folgendes ist eine banale frage, aber ich such mir hier nen Wolf und finde nix ...
Wo kann ich bei napp it die Einstellungen für den SMTP Server ändern? - Ich habe beim Einrichten das Passwort für den Account falsch eingegeben und würde das gerne anpassen, damit mich der Server bei Fehlern benachrichtigen kann.
Jetzt ist zwar der Stromverbrauch, im Gesamten, gesunken, aber jetzt switcht er immer zwischen 80 und 120 Watt hin und her.
Bei OI_148 musste ich bis zu 60 Sekunden warten, bis die HDs wieder angelaufen waren, um wieder vollen Zugriff auf die Daten zu bekommen. Jetzt, OI_151a7 ist der Zugriff sofort vorhanden. Also nehme ich an, dass die HDs sich nicht richtig schlafen legen, obwohl der Stromverbrauch um ca. 40 Watt zurück ging.
Ich hab jetzt 2 Dinge im Verdacht, dass der Stromverbrauch so unkonstant ist.
1. system-threshold always-on
oder
2. device-thresholds /scsi_vhci/disk@g5000cca22bc5b3ac 10m
Die Device-Bezeichnung habe ich aus format so übernommen. Ist es richtig anstatt
/scsi_vhci/disk@g5000cca22bc5b3ac
/dev/dsk/c9t5000CCA22BC5B3ACd0 zu nehmen?
Hat mir jemand die Lösung?
---------- Post added at 12:36 ---------- Previous post was at 12:02 ----------
das sehe ich etwas anders, die Profis hier werden bestimmt auch noch das eine oder andere Wort verlieren.
Bei einem RaidZ2 z.B. können 2 beliebige Platten ausfallen, egal welche und der Pool ist noch OK.
Bei einem Pool aus mehreren Mirror müssen dir nur die zwei falschen Platten ausfallen, nämlich die eines vdevs, und alle Deine Daten sind weg.
Ich hatte mich aufgrund des Blog von Constantin Gonzales auch für Mirrors entschieden, da mir seine Argumentation einleuchtete. Ferner hat ein Mirror-Pool den Vorteil, dass sich der Pool mit hinzufügen von weiteren vdevs (2 HDs) günstig erweitern lässt. Bei RaidZ2 braucht man gleich ein komplettes RaidZ2 zur Erweiterung des Pools.
Deinem Argument, welches gegen Mirrors spricht, muss ich aber so zustimmen und es ist eine Gefahr, welche nicht außer Acht gelassen werden darf.
Um dem entgegen zu wirken, muss also zwingend eine Spare-Platte im Server stecken, um einen Totalausfall zu vermeiden.
Klar ist, dass wenn die 2. HD eines vdevs über den Jordan geht, bevor das resilvering, mit der Spare-HD, abgeschlossen ist, dann ist alles futsch.
Ich habe auch deshalb die HDs bei zwei verschiedenen Händlern gekauft und vorher abgefragt, dass Diese auch, ganz sicher, aus zwei verschiedenen Chargen stammen, um so Murphys Law zu entgehen.
da ZFS für mich ein Muss ist, poste ich es hier rein...
Ich nutze jetzt schon seit einiger Zeit napp-it mit Solaris11(-Express) unter ESXi.
Aktuell bin ich dabei meinen Server zu "überholen" (neues Intertech 4324L, ....) und
die nächste Komponente, eine CPU mit AES native Support, steht bald an.
...meine TOP-Level Anforderung für mein NAS ist Verschlüsselung...und zwar Full-Disk.
Deshalb nutze ich auch Solaris11 und kein OI.
...ich würde aber gerne ESXi loswerden und gegen ProxmoxVE tauschen, aber Solaris
läuft da leider so garnicht stabil drunter. Also ein Linux based NAS muss her.
...der Komfort für ein NAS out-of-the-Box mit Solaris/OI und napp-it ist schon was Feines.
Ich weiss wie ich LUKS und ZOL ans laufen kriege ...aber eine Web basierte Admin-Oberfläche
wäre wirklich nicht zu verachten.
Daher mal meine aktuellsten Fragen an Euch Experten:
- welche Distri bzw. welche Kernel Version empfiehlt ihr für ZOL?
- was gibts bei LUKS (und AES native CPU) zu beachten?
- wie bekomme ich CIFS und NFS shares am besten (schnell installiert & konfiguriert und gute Performance) hin? ... gibts ein HowTo?
- gibt es unter Linux Alternativen zu napp-it? (Linux!!..bitte kein FreeNAS )
Darf man fragen, wieso kein ESXi mehr? Wenn du dafür den kompletten Storage umkrempelst und den Pool plattmachst, muss das ja schon gravierende Mängel haben.
Wie man Samba und NFS einrichtet erfährst du in über 9000 Anleitungen auf Google, das ist nicht ZFS spezifisch.
Nein, es gibt keine Webinterfaces für ZFS oder ähnliches unter Linux. Musst du wohl wie ein echter Mann die Kommandozeile bedienen.
Alles wichtige zu Verschlüsselung von ZFS unter Linux habe ich bereits öfter gepostet und wurde auch schön öfter besprochen, neuer Kernel ab 3.2, am einfachsten wäre Ubuntu Server oder Debian 6 mit Backports-Kernel da es dafür bereits fertige Pakete in der ZoL-PPA gibt. http://www.hardwareluxx.de/communit...id=32019&contenttype=vBForum_Post&showposts=1
Durchsuche meine Posts in den letzten drei Monaten, da ging es mehrfach darum.
...kein ESXi mehr, weil "No Windoze in da House! "
ich bin mal vor ewigen Zeiten von Proxmox weg und bei ESXi gelandet, weil nur da pci-passthrough wirklich stabil funzte.
Mit vt-d und Proxmox-VE 2.2 ist das Geschichte.
Der Web basierte Admin-Zugang ist was mir gefällt...alle meine VMs haben sowas...Win ist ein Krampf und nur für ESXi noch eine VM verschwenden sehe ich nicht ein.
Hat hier jemand Erfahrung mit IOmeter Dynamo unter Illumos oder nexentastor 3.1.3.5 ? Ich habe 4 Versionen getestet und bei jeder Version einen anderen Fehler bemerkt.
Entweder kann Dynamo keine Verbindung zu IOmeter herstellen, oder IOmeter stürzt ab, oder Dynamo kompiliert nicht ohne Fehler.
Der Fragestellung würde ich mich gerne anschließen. Habe praktisch die selben Settings, erreiche aber keinen SpinDown der Platten, mein System zieht immer zwischen 170W und 205W und das ist ein wenig viel für meinen Geschmack.
wobei man vieleicht sehen kann, das meine VMs einen eigenen Pool benutzen. Ansonsten fahren die Platten des großen Storagepools nie runter. Logisch!
Stromaufnahme meines Systems mit Singeplatte für DC und OI, Mirror für die VMs und 15 2 TB-Platten im Sleepmodus: ca. 65W
wobei man vieleicht sehen kann, das meine VMs einen eigenen Pool benutzen. Ansonsten fahren die Platten des großen Storagepools nie runter. Logisch!
Stromaufnahme meines Systems mit Singeplatte für DC und OI, Mirror für die VMs und 15 2 TB-Platten im Sleepmodus: ca. 65W
Ist bei mir nicht anders. Ich habe zwei VMs - omni-zfs nutzt das raidz3 und die zweite VM das raidXY. Habe jetzt mal meine power.conf an deine angeglichen, wobei die änderungen nur die cpu betreffen?! (cpudeepidle, cpu-threshold, autoS3 und system-threshold) und kann keine Verbesserung feststellen
Wie sieht das bei dir mit den Diensten aus? (fmd, ...)
LG
P.S. was sind das für Pfeile bei dir zwischen z.B. 'device-thresholds' und '/scsi_vhci/...'?
Für Edith: Hab jetzt mal den 'Auto-Service' disabled und jetzt funktionierts -.-
Einzigen 'crons' die laufen sind Snapshots alle 12 Stunden und Scrub alle 2 Wochen, woran liegts?
Bin jetzt etwas verwundert. Ich hab so gut wie die gleiche Hardware wie @Milleniumpilot, sogar einen Xeon L3426 und zwei HDs weniger und trotzdem ist mein Stromverbrauch ca. 50% höher.
Offensichtlich fahren meine HDs nicht runter.
Auch sind Datenbanken, VMs und Bewegungsdaten auf getrenntem san-Pool ausgelagert.
Was ich auch noch gemacht habe, außer die power.conf geändert ist:
der Datei /usr/lib/fm/fmd/plugins/disk-transport.conf "setprop interval 24h" hinzugefügt.
@banane22
Meinst du den Auto-Service in napp-it/Jobs?
Ist bei mir bisher auch noch disabled, aber nur weil ich noch keine Jobs angelegt habe.
Wenn Auto-Service disabled ist, dann gehen deine crons auch nicht von napp-it aus.
@banane22
Meinst du den Auto-Service in napp-it/Jobs?
Ist bei mir bisher auch noch disabled, aber nur weil ich noch keine Jobs angelegt habe.
Wenn Auto-Service disabled ist, dann gehen deine crons auch nicht von napp-it aus.
Ja, den meine ich. Ich bin mir mittlerweile aber nicht mehr sicher
Es könnte bei mir auch an einem im Windows verbundenen Netzlaufwerk gelegen haben!? - Werde nachher nochmal berichten ...
Also ich habe mich jetzt nochmal vor den Server gesetzt und beobachtet. Der Auto-Service von napp-it startet bei mir alle 15 Minuten die Festplatten bzw. greift einmal darauf zu, warum auch immer ...
Genauer ist es die Email benachrichtigung, die bei mir alle 15 Minuten anläuft:
2013.01.15.22.45.00: job 1358019889: start auto email
Es muss sich dabei um den 'alert' handeln, da dies der einzige Job ist, der bei mir überall auf 'every' steht. Mal davon ab, dass dies der vorgegebene Standard war, verstehe ich die Einstellungen wohl nicht korrekt. Ich bin davon ausgegangen, dass der 'alert' nur dann aktiv wird, wenn es etwas zu 'alerten' gibt ...
Code:
email alert to smtp.timotoups.de Disk,Low,Job mail@host.xy smtp port 25 every every every every 1358019889 active 15.jan 22:31 - run now delete
email status to smtp.timotoups.de Info mail@host.xy smtp port 25 every every-7 12 0 1358020343 active 14.jan 12:00 - run now delete
Ich lösche jetzt mal den 'email alert to' job und schaue was passiert ...
Für Edith: Jupps, der Email Alert haut die Platten bei mir immer aus dem Schlaf! Werde erstmal den Alert parallel zu den Snapshots laufen lassen, weil das macht ja keinen Sinn für eine Eventualität die Platten aus dem Schlaf zu holen und mit dem Spin-Up die Platten unnötig zu stressen.
@layerbreak:
bei mir hat es geholfen den Power-Service neu zu starten:
svcadm restart power
hab ne frage Hab in einer VM mein System "nachgebildet" und versucht meinen Pool durch das ersetzen mit größeren Platten zu vergrößern. Das hat auch wunderbar geklappt, nur leider erkennt der Pool die neue Größe nicht - sprich er hat immer noch die Ausgagnsgröße. Muss ich da noch irgendwas machen ? Hab mal gehört der Pool wächst dann von alleine an ...
Gestern abend dachte ich mir, dass ein Neustart von OI auch nicht schaden kann. Und siehe da, eine 1/2 Stunde später waren die HDs von bigpool runtergefahren.
Heute morgen, bevor jemand im Netz aktiv war, ist der Stromverbrauch aber wieder konstant auf über 150 Watt, alle HDs laufen. In vSphere zeigt er mir unter Leistung immer alle 15 Minuten einen Leistungspeak an.
Bei napp-it sind bei mir momentan keine Jobs angelegt und auto-service disabled.
@milleniumpilot, @banane22 hab ihr die Datei /usr/lib/fm/fmd/plugins/disk-transport.conf "setprop interval 24h" aber auch so verändert oder andere Werte genommen bzw. "setpr..." nicht hinzugefügt.
Habt ihr über Systemverwaltung den Time-Slider aktiviert, damit das System auto-snaps anlegt?
Bei ESXi welche Netzwerkkarte habt ihr OI zugewiesen? VMXNET3 oder E1000?
Wir reden hier von ESXi 5.1 Build 914609 und OI_151a7?
Gibts eine Möglichkeit zu überprüfen, was das System und die HDs wach hält?
---------- Post added at 11:23 ---------- Previous post was at 10:34 ----------
Ich hab in /var/adm/messages noch folgendes gefunden:
Jan 16 11:09:42 ripley smbsrv: [ID 138215 kern.notice] NOTICE: smbd[RIPLEY\user5]: bilder share not found
smbsrv spammt mir die Log im 30 sek. Rhythmus voll.
Das Dateisystem "bilder" gibts aber nicht mehr, da ich doch Probleme mit der Rechtezuweisung hatte. Aus diesem Grunde hatte ich "bilder" gelöscht und ein Neues "pics" angelegt.
"bilder" bzw. jetzt "pics" lag auf bigpool. Offensichtlich sucht der smb Dienst die ganze Zeit diesen share.
Unter /var/smb kann ich aber nichts finden um das Problem zu lösen. Andere Lösungsmöglichkeit?
@layerbreak:
nein, die disk-transport.conf habe ich nicht angefasst. Würde aber behaupten, dass es nicht wirklich was ausmacht. Die disk-transport.conf gehört doch zum fmd?! Falls ja, ist dieser bei mir aktiv und holt die Pools nicht aus dem SpinDown.
Zu den Leistungspeaks hab ich jetzt keine Idee, außer Logs gucken! Merk dir die Augenblicke des Aufweckens und schau in den Logs nach, was derzeit in OI vor sich geht.
Ich benutze OmniOS und nicht Indiana, desshalb kann ich bezüglich "Time-Slider" etc. recht wenig sagen. Ich habe die Snaps bei mir via napp-it konfiguriert. Diese machen bei mir 2 x Täglich einen Snapshot und wecken im Zweifel den entsprechenden Pool auf. Netzwerkkarte habe ich die VM Karte (VMXNet3) konfiguriert.
Ich habe gerade kurz in die Logs meines Verbrauchmessers geschaut und bin glücklich! 30 Minuten nachdem ich vom Sofa aufgestanden und ins Bett gegangen bin, ist der Server auf einen Verbrauch von 80 - 95W gesunken. (Bei mir sind allerdings noch TV Tuner verbaut die während der Nacht teilweise auch Aufnahmen gemacht haben)
vielleicht hat jemand einen Tipp für mein akutes Problem:
napp-it 0.8h @ oi 151a5
raidz1 aus 5x WDC WD15EVDS-73V mit 512b Sektoren
zum austauschen habe ich ein 2 TB mit 4k Sektoren, beim replace kommt:
Code:
Could not proceed due to an error. Please try again later or ask your sysadmin.
Maybee a reboot after power-off may help.
cannot replace c2t50014EE0AD348C04d0 with c2t5000C50044153CA3d0: devices have different sector alignment
Was ist die Lösung damit ich die neu 2TB HDD nehmen kann?
(ich bin schon etwas nervös, weil das momentan eine leicht spannende Situation ist)
habe alleine nur die power.conf angefasst, Timeslider verwende ich nicht, Snaps via Nappit. ESX ist bei mir die 5.0 update1, über die 5.1 habe ich viel schlechtes lesen müssen, ich muss nicht immer das Neueste haben.
OI läuft mit beiden Karten bei mir, das sollte nicht der Grund sein.
Für diese Meldung hab ich jetzt mal ein weiteres FS "bilder" wieder angelegt und schon war Ruhe mit dieser Meldung.
Weiter spammt halt vmxnet3 die Log voll.
Aber weiterhin zeigte mir vSphere, dass OI die Host-CPU mit Vollgas lief und nicht mehr runter kam.
Also mal ein Neustart und schon war Ruhe bei der CPU.
Jetzt hab ich im log folgendes, nach dem Neustart stehen:
Jan 16 16:01:19 ripley fmd: [ID 377184 daemon.error] SUNW-MSG-ID: SUNOS-8000-KL, TYPE: Defect, VER: 1, SEVERITY: Major
Jan 16 16:01:19 ripley EVENT-TIME: Wed Jan 16 16:01:19 CET 2013
Jan 16 16:01:19 ripley PLATFORM: VMware-Virtual-Platform, CSN: VMware-56-4d-72-01-ab-91-7d-3e-21-1c-2b-ba-9a-11-cf-42, HOSTNAME: ripley
Jan 16 16:01:19 ripley SOURCE: software-diagnosis, REV: 0.1
Jan 16 16:01:19 ripley EVENT-ID: 2e53a992-e6b4-695e-abe3-e68270a3f2b7
Jan 16 16:01:19 ripley DESC: The system has rebooted after a kernel panic. Refer to SUNOS-8000-KL for more information.
Jan 16 16:01:19 ripley AUTO-RESPONSE: The failed system image was dumped to the dump device. If savecore is enabled (see dumpadm(1M)) a copy of the dump will be written to the savecore directory .
Jan 16 16:01:19 ripley IMPACT: There may be some performance impact while the panic is copied to the savecore directory. Disk space usage by panics can be substantial.
Jan 16 16:01:19 ripley REC-ACTION: If savecore is not enabled then please take steps to preserve the crash image.
Jan 16 16:01:19 ripley Use 'fmdump -Vp -u 2e53a992-e6b4-695e-abe3-e68270a3f2b7' to view more panic detail. Please refer to the knowledge article for additional informati
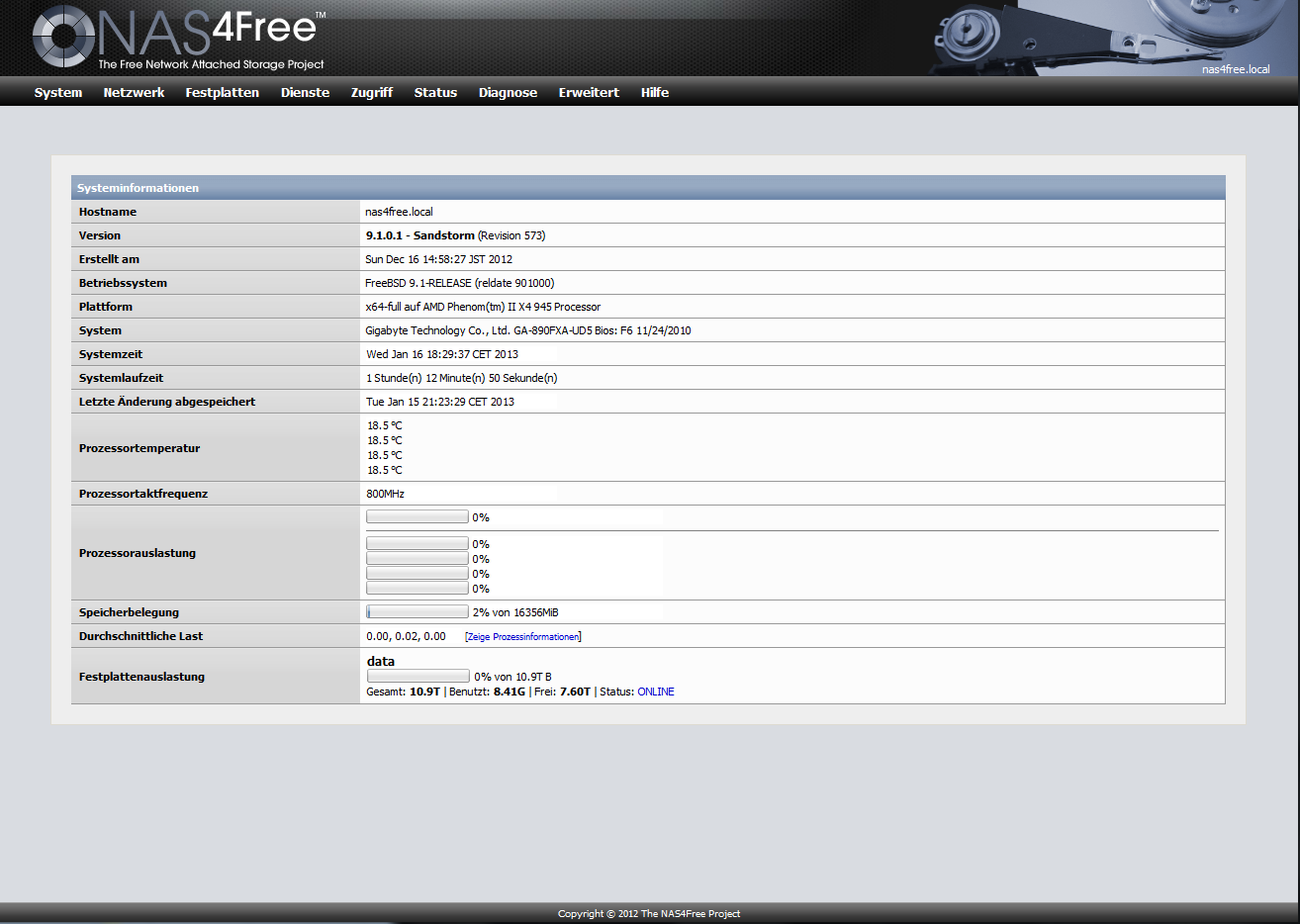
Hallo ich habe ein Performanceproblem mit Free4NAS (FreeBSD).
Das System:
AMD Phenom 2 x4 3ghz
16GB DDR3 ECC Unreg 1600mhz
Gigabyte GA-890FXA-UD5
HD5450 512mb (wird gegen irgendwas PCI mäßiges getauscht oder entfernt)
300W Cougar A300
Intel® PRO/1000 PT Dual Port Server Adapter
IBM ServeRAID M1015 (LSI9211-8i) mit LSI Firmware (IT-Mode)
HP SAS Expander 32port (Dual-Link)
8x1,5Tb Samsung F2 (ZFS-RaidZ2)
System auf Mtron Mobi 32GB SLC SSD
Unter Solaris gab es mit den Onboard Realtek NIC kein Performance Problem (~110MB/s up&down), allerdings froren sie nach unbestimmter Zeit einfach ein. Nach dem zustecken der Intel NIC ließ sich Solaris weder starten noch neu installieren. Da ich mit der Bedienung unzufrieden war habe ich NAS4Free ausprobiert und würde es gerne nutzen. Allerdings sieht es beim befüllen so aus:
Diese Übertragungsraten sind für mich absolut inakzeptabel bei der Hardware. Also habe ich die Optimierungen im NAS4Free Thread befolgt und verschiedene /boot/loader.conf getestet/ die SMB settings angepasst.
Ich sehe das bei Prozessor 800Mhz steht. Der taktet unter Last aber schon wieder hoch?
Nicht das der irgendwo ein powersave-profile geladen hat und bei 800Mhz bleibt..
??? 90% Netzauslastung sind "völlig unakzeptabel"? Dir ist schon klar dass das völlig in Ordnung für eine unoptimierte Samba-Konfiguration ist? Abhängig von den Daten, der CPU-Last, den Netzwerkkarten, deren Treibern und des Betriebssystems ist das ein Wert der völlig im Normalbereich liegt. Auch eine Windows zu Windows Share mit Intel-Netzwerkkarten erreicht keine konstanten 100%.
Deine "Probleme" mit der maximalen Übertragungsrate liegen wohl eher an an Samba und nicht an den sonstigen Einstellungen. Probiere mal daran herum zustellen, nicht an den anderen Einstellungen.
Mach dir aber keine zu großen Hoffnungen, ich denke nicht dass du an die Werte vom Windows oder Solaris-SMB-Server (97-99%) dran kommst, vielleicht in Richtung 94-98%.
Vielleicht mit dem neuen Samba4 welches SMB2.0 besser/schneller unterstützt, aber damit habe ich keine Erfahrungen, ich setze noch auf Samba 3.6.
Die Zacken bzw. die fehlende Konstanz kommen eher vom Einatmen/Ausatmen-System von ZFS, dafür wären Optimieren an den ZFS-Einstellungen von FreeBSD eventuell hilfreich.
Oder du verwendest einfach Solaris oder ZFSonLinux, da muss man nicht für so etwas herum basteln.


") )
)
 "
"

")

 efault.log hab ich folgendes gefunden:
efault.log hab ich folgendes gefunden: