
Werbung
Deep-Learning-Netzwerke definieren bereits viele Bereiche unserer Aktivitäten im Netz. Unter Deep Learning werden aber auch viele Funktionen zusammengefasst, die mit künstlicher Intelligenz in einen Zusammenhang gebracht werden, der mit dem eigentlichen Begriff und der Funktion von AI wenig zu tun haben. Dennoch werden Deep-Learning-Netzwerke in Zukunft weite Bereiche der Nutzung von Daten aus dem Internet definieren und auf diesen Umstand haben sich auch einige Hardwarefirmen bereits eingestellt.
Intel will mit den Xeon-Phi-GPU-Beschleunigern in diesem Segment ebenso eine Rolle spielen wie Google, die dazu sogar eine eigene TPU, also einen eigenen Chip entwickelt haben. Als einer der Vorreiter sieht sich dabei aber NVIDIA. Die Rechenleistung moderner GPUs lässt sich nicht nur nutzen um Dreiecke zu zeichnen und diese mit Texturen zu belegen, sondern auch dazu viele wenig komplexe Rechenaufgaben parallel zu verarbeiten – eben diese Anforderungen stellen Deep-Learning-Netzwerke an die Hardware.
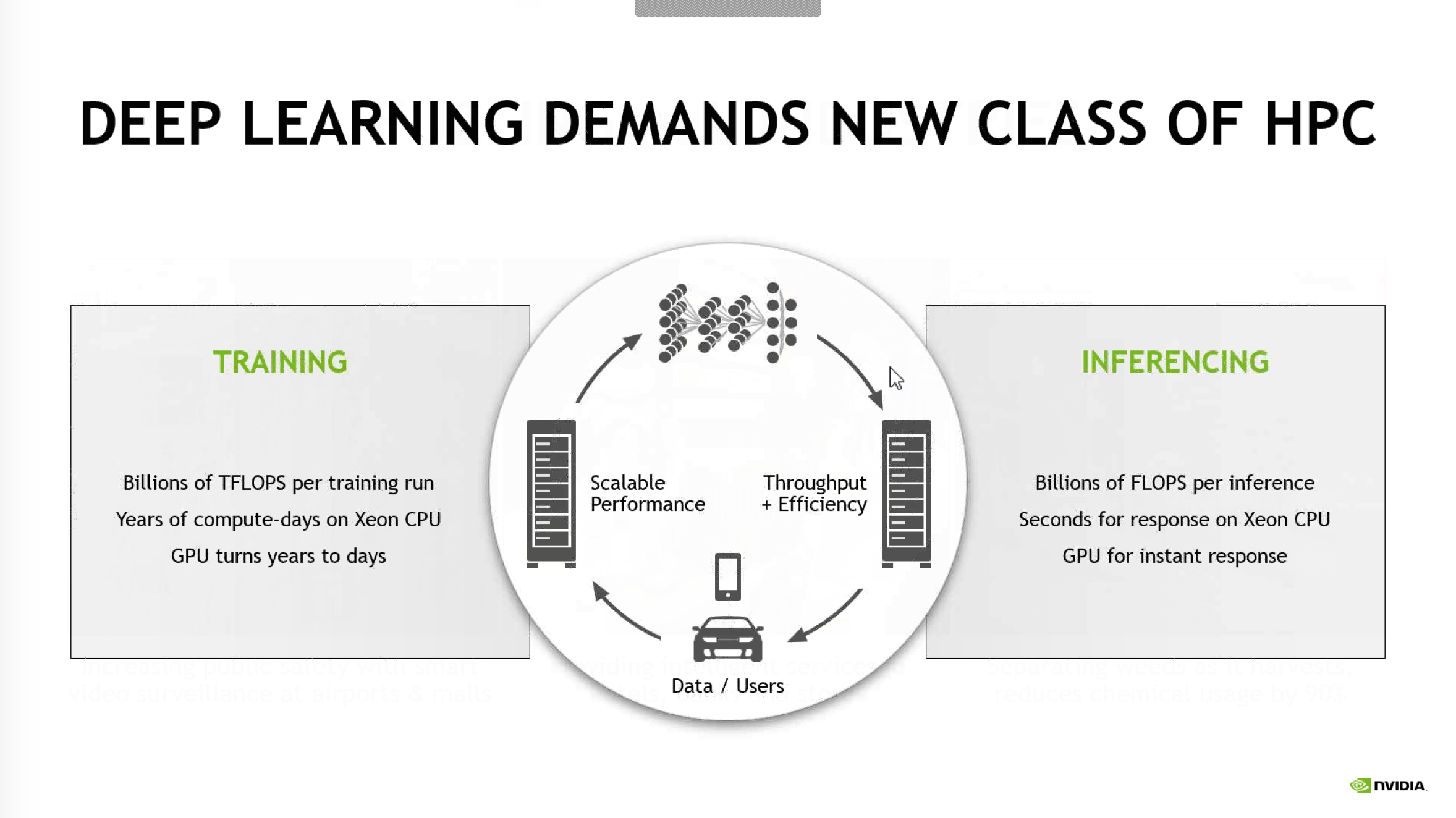
Dabei stellen Deep-Learning-Netzwerke in zwei Bereichen solche Anforderungen an die Hardware. Erst einmal muss ein solches Netzwerk angelernt werden. Dies wird notwendig um beispielsweise Milliarden an Fotos bestimmten Kategorien zuzuordnen. Was ist darauf zu sehen? In welcher Beziehung steht ein Vogel auf dem Bild zum restlichen Tierreich bzw. welcher Gattung gehört er an. Eine solche Bilddatenbank wird schnell extrem komplex und beinhaltet mehrere Milliarden Knoten, die miteinander verknüpft sind. Diese Verbindungen werden im Anlernprozess für ein Deep-Learning-Netzwerk erstellt und dazu ist eine enorme Rechenleistung notwendig, damit ein Anlernen nicht mehrere Monate oder Tage dauert, sondern eventuell nur noch wenige Stunden. Zu diesem Zweck hat NVIDIA den DGX-1 entwickelt. Dabei handelt es sich um ein Rack, in dem acht Tesla P100 auf Basis der Pascal-Architektur arbeiten. Mit jeweils 3.584 Shadereinheiten, einem 16 GB großen HBM2 und einer Speicherbandbreite von 720 GB/s sind die P100-GPUs prädestiniert um solche Rechenaufgaben zu erledigen.


NVIDIA Tesla P4 und Tesla P40
[h3]Tesla P4 und P40 beschleunigen die Auswertung von Deep-Learning-Netzwerken[/h3]
Soweit die eine Seite der Anforderungen hinsichtlich der Hardware zu Verwendung eines Deep-Learning-Netzwerkes. Eine zweite wird als Inferencing bezeichnet und dabei handelt es sich um den Zugriff auf die im Deep-Learning-Netzwerk vorhandenen Informationen. Auch dabei kommt es darauf an die Daten so schnell wie möglich zu extrahieren und auch dazu sind viele parallele Rechenprozesse notwendig. Zu diesem Zweck stellt NVIDIA heute die GPU-Beschleuniger Tesla P4 und P40 vor.
Auf eine Anfrage an das Netzwerk soll nicht mehr Sekunden gewartet werden müssen, sondern nur noch wenige Bruchteile einer Sekunde – so das erklärte Ziel. Die Wartezeit zu verkürzen ist vor allem dann wichtig, wenn der Nutzer einen direkten Zugang zu den Anfragen hat bzw. diese selbst stellt. Einige Beispiele sind die Suche nach einem bestimmten Restaurant in der Nähe per Spracheingabe, wo zunächst ein Deep-Learning-Netzwerk zu Übersetzung der Sprache verwendet wird und anschließend daran auch die eigentliche Suche nach dem Restaurant in einem solchen Netzwerk stattfinden kann. Hier will der Nutzer sicherlich nicht wenige Sekunden auf eine Antwort warten, sondern diese schnellstmöglich erhalten.


NVIDIA Tesla P4 und Tesla P40
Doch kommen wir nun zur Hardware und beginnen dabei mit der Tesla P4. Diese ist besonders kompakt und soll daher auch dort zum Einsatz kommen, wo der Fokus nicht vollends auf der Geschwindigkeit liegt, sondern auch die Effizienz ein wichtiger Faktor im Aufbau des Servers darstellt. Die Tesla P4 basiert auf der GP104 wie bei der GeForce GTX 1080, ist aber deutlich kompakter gebaut. Damit dies mit einer ebenso kompakten Kühlung funktioniert, sind die 2.560 Shadereinheiten extrem langsam getaktet. NVIDIA sieht zur Ermittlung des Taktes bzw. der Rechenleistung zwei Verfahren vor. Als P4 Base (definiert als SGEMM) erreicht die Tesla P4 einen GPU-Takt von 810 MHz was einer Rechenleistung von 16,6 TOPS (INT8) gleichkommt. Die Rechenleistung bei einfacher Genauigkeit liegt dann bei 4,15 TFLOPS. Als P4 Boost (definiert als 70 % SGEMM) erreicht die Tesla P4 einen Boost-Takt von 1.063 MHz oder 21,8 TOPS (INT8). Die Single-Precision-Rechenleistung beträgt dann 5,5 TFLOPS. Die 8 GB GDDR5-Speicher erreichen eine Speicherbandbreite von 192 GB/s. Die Leistungsaufnahme beträgt je nach Anforderungsprofil 50 oder 75 W. In Anbetracht der Verwendung der GP104-GPU klingen diese 50/75 W sehr wenig und dies unterstreicht einmal mehr die mit der neuen Fertigung und der Pascal-Architektur erreichte Effizienz bei NVIDIA.

Zweite neue Karte ist die Tesla P40. Hier kommt mit der GP102-GPU die gleiche Hardware zum Einsatz wie auf der Titan X oder der Quadro P6000. Bei der Tesla P40 ermöglicht NVIDIA mit 250 W aber eine deutlich höhere Leistungsaufnahme und daher ist diese Karte auch eher dort sinnvoll, wo nicht jedes Watt eingespart werden muss. Natürlich aber bietet auch die Tesla P40 zwei Taktstufen. Der Basis-Takt beläuft sich auf 1.303 MHz und damit werden 40 TOPS (IN8) bzw. 10 TFLOPS bei einfacher Genauigkeit. Per Boost-Takt von 1.531 MHz erreicht die Karte mit 47 TOPS (INT8) und 12 TFLOPS ihre maximale Leistung. Der Speicher ist mit 24 GB recht großzügig bemessen und mit 346 GB/s auch recht schnell angebunden.


NVIDIA Tesla P4 und Tesla P40
NVIDIA liefert auch gleich einige Leistungswerte für das Inferencing eines Deep-Learning-Netzwerkes. Während eine Intel CPU mit 14 Kernen dazu 260 ms benötigen soll, sind es bei der Tesla P4 nur noch 11 ms und bei der Tesla P40 sollen es sogar nur 6 ms. Um ein Video auf bestimmte Inhalte zu untersuchen werden ebenfalls Deep-Learning-Netzwerke eingesetzt und auch hier hat NVIDIA einige Leistungsdaten geliefert. Ein Server mit einer Tesla P4 soll beispielsweise etwas mehr als 90 Streams (720p bei 30 FPS) gleichzeitig analysieren können, während dazu 13 Server mit Intel Xeon E5-2650 notwendig wären. In wie weit solche Leistungsvergleiche auch in der Realität zu sehen sind, sei einmal dahingestellt.
NVIDIA arbeitet mit zahlreichen Serveranbietern zusammen, die entsprechende Systeme bestückt mit der Tesla P40 ab Oktober anbieten wollen, während solche mit Tesla P4 erst im November folgen werden. Angaben zum Preis macht NVIDIA zum aktuellen Zeitpunkt nicht.


NVIDIA Tesla P4 und Tesla P40
Mit der Vorstellung der Tesla P4 und P40 sieht NVIDIA den Kreis für das Anlernen und Auswerten von Deep-Learning-Netzwerken vorerst geschlossen und verweist auch auf die enormen Leistungssteigerungen in diesen Bereichen.
