
Werbung
Gegen Ende des Jahres will Intel mit der nächsten Xeon-Phi-Generation starten. Die Knights-Landing-Generation wird im 14-nm-FinFET-Verfahren gefertigt und kommt auf 8 Milliarden Transistoren. Damit gehört dieser Chip zu den größten und komplexesten, die jemals von Intel gefertigt wurden.
Bisher ging man von einer maximalen Ausbaustufe mit 72 Kernen auf Basis der Silvermont-Architektur aus. Der Aufbau besteht dabei aus 36 Tiles oder Kacheln mit jeweils zwei Kernen. Auf der Hot-Chip-Konferenz erklärte KNL-Chefarchitekt Avinsh Sodani nun, dass die Knights-Landing-Generation alias Xeon Phi x200 noch zwei weitere Tiles besitzt. Dies resultiert in vier weiteren Kernen, so dass der Prozessor auf 76 Rechenkerne kommt. Diese seien aber in keinem bisher geplanten Produkt aktiv und werden seitens Intel als Reserve vorbehalten. Bei der Fertigung des komplexen Prozessors kommt es immer wieder zu Teildefekten, die über die vier Reservekerne kompensiert werden.
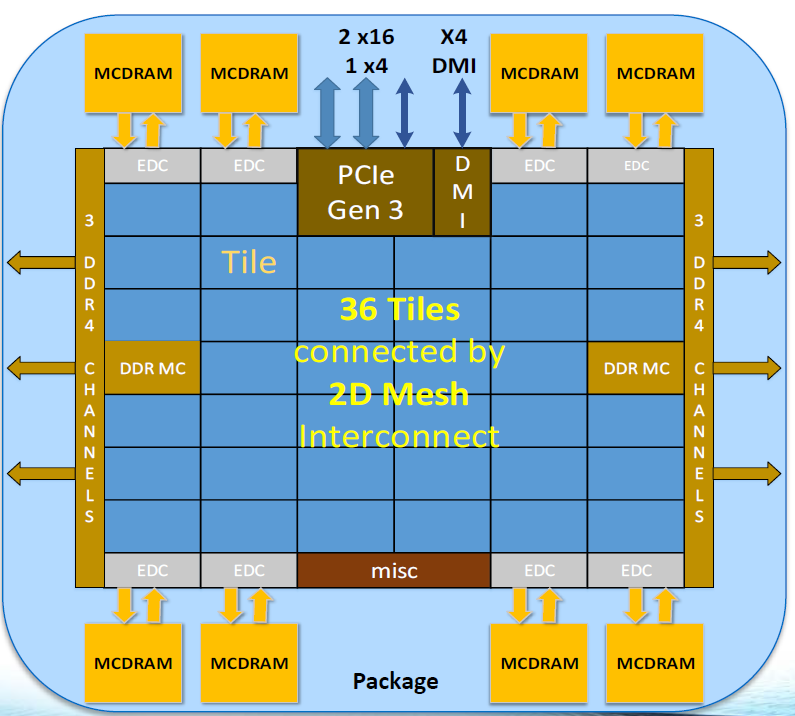
Der Aufbau sieht demnach wie folgt aus: 38 Tiles mit jeweils zwei Rechenkernen sind in einem 2D-Mesh organisiert. Eingerahmt ist dieses 2D-Mesh in sechs DDR4-Speichercontroller, dem PCI-Express-3.4-Interface und dem DMI-Controller. Hinzu kommen acht EDC-Controller für ebenso viele MCRAM-Bausteine mit jeweils 2 GB Kapazität. Aus rein technischer Sicht sei es kein Problem, alle funktionsfähigen Kerne freizuschalten, so Intel. Allerdings verzichtet man aus verschiedenen Gründen darauf. Der wohl wichtigste ist die Tatsache, dass der Chip in virtuelle Quadranten eingeteilt werden kann. Eine ungerade Anzahl an Kernen oder eine solche, die nicht durch vier teilbar ist, ist demzufolge nicht praktikabel.
Laut Intel erreicht Knights Landing eine Rechenleistung von drei TFLOPS bei doppelter Genauigkeit. Rein rechnerisch kommt der Prozessor demnach auf einen Takt von 1,3 GHz. Im Vergleich zu zwei Intel Xeon E5-2697 v3 bietet Knights Landing eine fast identische Leistung im SPECint_2006_rate und SPECfp_2006_rate. Das Paradesegment der Xeon Phis sind aber andere Rechenaufgaben, wie verschiedene Deep-Learning-Algorithmen und STREAM Triad.
Hintergrund zum Xeon Phi auf Basis von "Knights Landing"
Die Rechenkerne im neuen Xeon Phi basieren auf der klassischen x86-Architektur, genauer gesagt der Silvermont-Architektur und können pro Kern vier Threads bearbeiten. Daneben besitzen sie noch AVX512-Einheiten. Im Vergleich zum Einsatz in der BailTrail-Plattform sind aber einige Änderungen vorgenommen worden, die auf den Xeon-Phi-Karten besonders interessant sind. Dazu zählt unter anderem eine andere Cache-Hierarchie. Eine höhere Pack-Dichte im Server will Intel durch die Sockelbarkeit der neuen "Knights Landing"-Xeon-Phi erreichen.

Insgesamt sollen die neuen Xeon-Phi-Beschleuniger auf über 3 TFLOPS Double-Precision-Performance kommen. Zum Vergleich: AMDs FirePro W9100 kommt auf 2,62 TFLOPS und NVIDIAs Tesla K80 erreicht 2,91 TFLOPS. Wichtig ist aber auch der lokal verfügbare Speicher, der 16 GB groß sein soll. Beim Speicher handelt es sich um Hybrid Memory Cubes von Micron, die im gleichen Package untergebraucht sind, wie der Xeon-Phi-Chip. Damit will Intel die Zugriffszeiten auf diesen Speicher reduzieren und zudem die Bandbreite erhöhen. Letztgenannte soll bei 512 GB pro Sekunde liegen, was in etwa 1/3 schneller ist als das, was AMD und NVIDIA derzeit als Anbindung ihrem Grafikspeicher zur Verfügung stellen können.