
Werbung
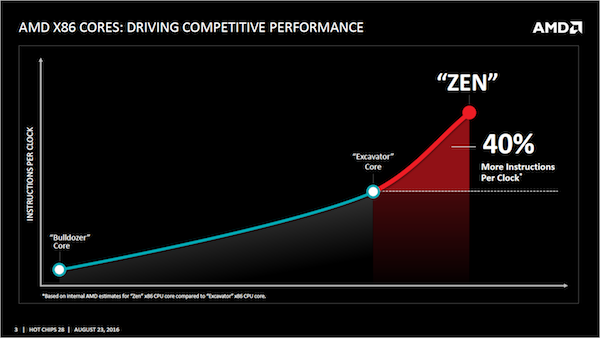
Auf der Hot Chips 28 hat AMD weitere Informationen zur Zen-Architektur veröffentlicht und geht dabei auf Bereiche ein, die bisher noch nicht in dieser Form beschrieben wurden.
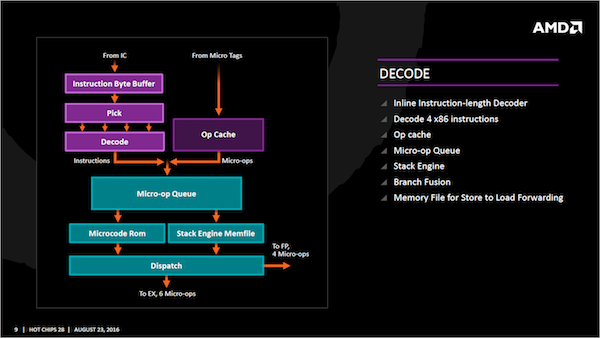
Zunächst einmal zum Micro-Op-Cache, der in der Zen-Architektur eine der wichtigsten Neuerungen darstellt. Bereits dekodierte Code kann hier abgelegt werden und wird in der Folge in die Micro-Op-Queue überführt. Leider gibt AMD nicht an, wie groß der Micro-Op-Cache und die Queue sind. Um die Queue zu entlassen wird eine Erkennung von Schleifen versucht. Wird oder werden eine Schleife erkannt, wird diese ausgekoppelt und direkt an das Frontend gehängt.

Präsentation zur Zen-Architektur auf der Hot Chips 28
Nach diesen Teil unterscheidet sich die Pipeline nun wieder etwas deutlicher von der von Intel. Während Intel einen gemeinsamen Reorder Buffer für Integer- und Gleitkommaoperationen verwendet, trennt AMD diese nach dem Dispatcher auf. Aufgrund der unterschiedlichen Gewichtung können sechs Integer-Instruktionen am Dispatcher verarbeitet werden und vier Gleitkomma-Instruktionen. In den dazugehörigen Registern ist mit 168 Integer- und 160 Gleitkommarestigerplätzen ausreichend Platz vorhanden.
Die Gleitkommaberechnungen werden auf zwei 128 Bit FP-MUL- und zwei FP-ADD-Einheiten durchgeführt. Bei Bedarf können diese zu einem 256 Bit AVX2 zusammenschaltet werden. Derzeit ist noch unklar, ob AMD Fused Multiply Add (FMA) pro Takt ausgeführt werden kann. Intel verwendet bei Haswell sogar zwei dieser Einheiten. Sollte dies bei AMD nicht der Fall sein, dürfte Zen bei entsprechenden Anforderungen eher auf Sandy-Bridge-Niveau liegen anstatt so schnell wie Haswell zu sein.


Präsentation zur Zen-Architektur auf der Hot Chips 28
Die Details zu den Caches hatte AMD schon teilweise verraten, führt diese nun aber noch einmal etwas genauer aus. Der L1-Cache ist insgesamt 96 kB groß, teilt sich aber zu 64 kB in Instruktionen und 32 kB in Daten auf. Damit ist zumindest der Instruktionen-Anteil doppelt so groß wie bei Skylake, während der Daten-Anteil die identische Größe hat. Wieder doppelt so groß ist der L2-Cache mit 512 kB. Wichtig ist aber nicht nur die Größe, sondern auch die Geschwindigkeit der Caches. L1- und L2-Cache sollen etwa doppelt so schnell sein, während der L3-Cache sogar um den Faktor fünf zulegen soll.

Präsentation zur Zen-Architektur auf der Hot Chips 28
Um den Aufbau und dessen Beschreibung zu vereinfachen führt AMD eine neue Einheit ein: Den CPU Complex. Ein CPU Complex besteht dabei aus vier Kernen mit den L1- und L2-Caches sowie zwei Cache-Segmente zu jeweils 1 MB pro Kern – also insgesamt 8 MB im CPU Complex. Eine CPU aus einem CPU Complex wird mit dem Codenamen Zeppelin bezeichnet und besitzt neben dem CPU-Anteil auch noch zwei DDR4-Speicherkanäle und 32 PCI-Express-Lanes. Allerdings stammen diese Informationen aus unbestätigten Quellen und Leaks. AMD hat sich bisher noch nicht zum Uncore-Part der Zen-Architektur geäußert.


Präsentation zur Zen-Architektur auf der Hot Chips 28
Die Naples-CPU, ebenfalls auf dem Event parallel zum IDF gezeigt, kommt mit 32 Kernen auf vier Zeppelin-Dies, die zusammengepackt und via weiterentwickeltem HyperTransport miteinander verknüpft sind. Entsprechend dürften hier 128 PCI-Express-Lanes und acht DDR4-Speicherkanäle zur Verfügung stehen. Über mehr als 5.000 Pins wird der Prozessor mit dem Sockel verbunden.
Derartige Details sind aber noch nicht offiziell von AMD bestätigt worden. Zu einem späteren Zeitpunkt will man sich zu einzelnen Modellen, deren Takt und Anzahl der Kerne äußern.

