
Werbung
Im Zusammenhang mit der Implementation von Asynchronous Compute im Time-Spy-Benchmark hat Futuremark nach Bekanntwerden der Art und Weise wie dort auf bestimmte Prozesse zurückgegriffen wird, bereits mit einem Statement reagiert. Konkret geht es um den Vorwurf, Asynchronous-Compute-Prozesse seien nicht korrekt umgesetzt und bevorteilen damit den einen oder anderen Hersteller.
Genauer gesagt geht es darum, dass bei Verwendung einer Grafikkarte mit Maxwell-GPU von NVIDIA kein Asynchronous Compute angewendet wird, selbst wenn dies aktiviert und laut Hersteller auch möglich sein soll. Stattdessen sorgt der Treiber dafür, dass ein alternativer Renderpfad angewendet wird, was die Ergebnisse in gewisser Weise verfälscht. Unsere Ergebnisse zeigen dies auch in gewisser Form bzw. ein zu erwartendes Verhalten, denn für Asynchronous Compute gingen wir nicht mehr davon aus, dass NVIDIA diese mit der Maxwell-Architektur korrekt wird ausführen können.
Auch sollen die Aussagen von Futuremark für Verwirrung gesorgt haben, denn laut der Entwickler ist Time Spy der erste echte DirectX-12-Benchmark, der von Beginn an dahingehend optimiert wurde. Allerdings verwendet Time Spy nur das DirectX-Feature-Level 11_0 und bedient sich nur in Teilen im Feature-Level 12_0. Dies ist für das besagte Async Compute aber auch Explicit Multi Adapter der Fall.
Nun aber zur Veröffentlichung von Futuremark, die in allen Details auf die Implementation und Ausführung von Direct und Compute Queues eingehen soll. Dabei werden in Schaubildern bzw. Auswertungen der Queues auch die Unterschiede zwischen der GeForce GTX 1080, GeForce GTX 970 und Radeon RX 480 herausgestellt.
Laut Futuremark ist Asynchronous Compute der wichtigste Bestandteil von DirectX 12 und entsprechend groß ist der Einfluss dieser Funktionen im Time-Spy-Benchmark. Bei der Implementation habe man mit allen beteiligten Unternehmen zusammengearbeitet – AMD, Intel, Microsoft, NVIDIA und einige mehr.
Die Umsetzung sei in allen Fällen gleich und es gibt keine herstellerspezifische Optimierung. Daher seien auch die Ergebnisse sehr gut vergleichbar und bevorteilen keine bestimmte Hardware. Ob die Compute Queue aber seriell oder parallel ausgeführt würde, sei nicht die Entscheidung des Benchmarks, sondern des Treibers und hierher rühren laut Futuremark auch die Unterschiede in der Auswertung und Beurteilung des Benchmarks. Futuremark sei nicht in der Lage, bestimmten Prozessen ein spezifisches Verhalten oder bestimmte Bedürfnisse anzuheften. Demnach sei es auch nicht möglich, Einfluss auf die Abarbeitung durch den Treiber und letztendlich die Hardware zu nehmen.
[h3]Direct und Compute Queue bei der GeForce GTX 970, GeForce GTX 1080 und Radeon R9 Fury[/h3]
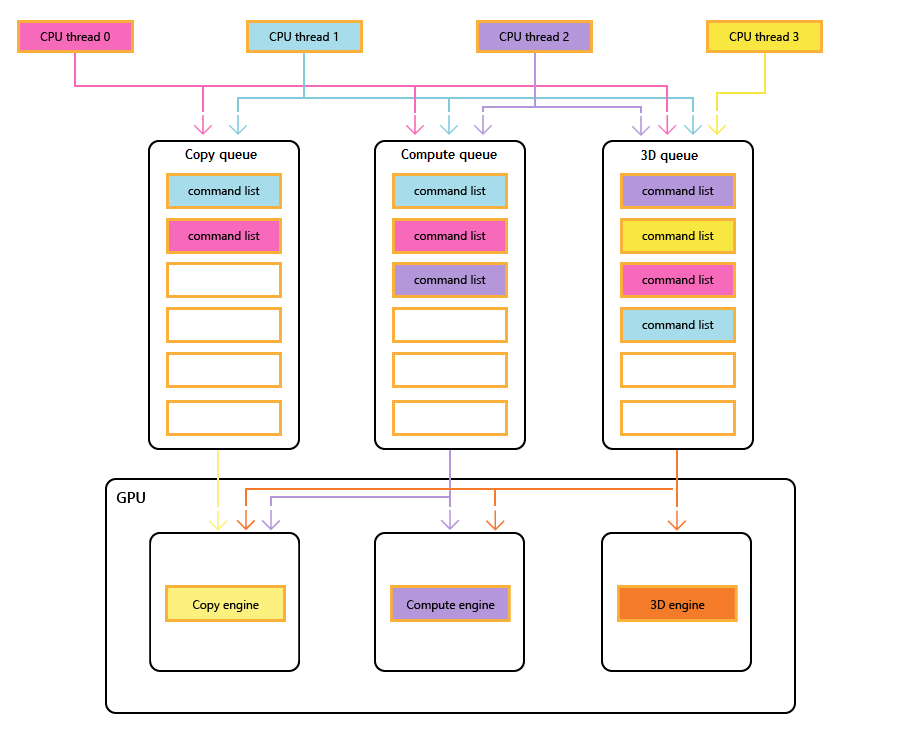
Futuremark möchte dies auch mit einer detaillierten Analyse belegen, die wir versucht haben nachzuvollziehen. Erstellt wurde die Analyse mit einem Programm namens GPUView. GPUView stellt die Pakete dar, die in die Queues einsortiert und abgearbeitet werden. Horizontal getrennt dargestellt werden eventuell vorhandene Direct- und Compute-Queues.
Für die GeForce GTX 970 stellt sich dies wie folgt dar:


Prozess- und Queue Verhalten der GeForce GTX 970 (links mit Asynchronous Compute, rechts mit deaktiviertem Asynchronous Compute)
Links ist GPUView mit aktiviertem Asynchronous Compute zu sehen, rechts mit deaktivierter Einstellung. In beiden Fällen aber ist das Verhalten grundsätzlich identisch, denn aus der dedizierten Compute Queue wird der Compute-Prozess seriell durch den Treiber an die Hardware-3D-Queue weitergeleitet. Auch wenn GPUView zwei separate Queues andeutet (gemischt mit Direct- und Compute-Prozessen), so werden diese letztendlich in einer einzige Hardware-Queue zusammengeführt.
Das Verhalten der Radeon R9 Fury unterscheidet sich hingegen maßgeblich:
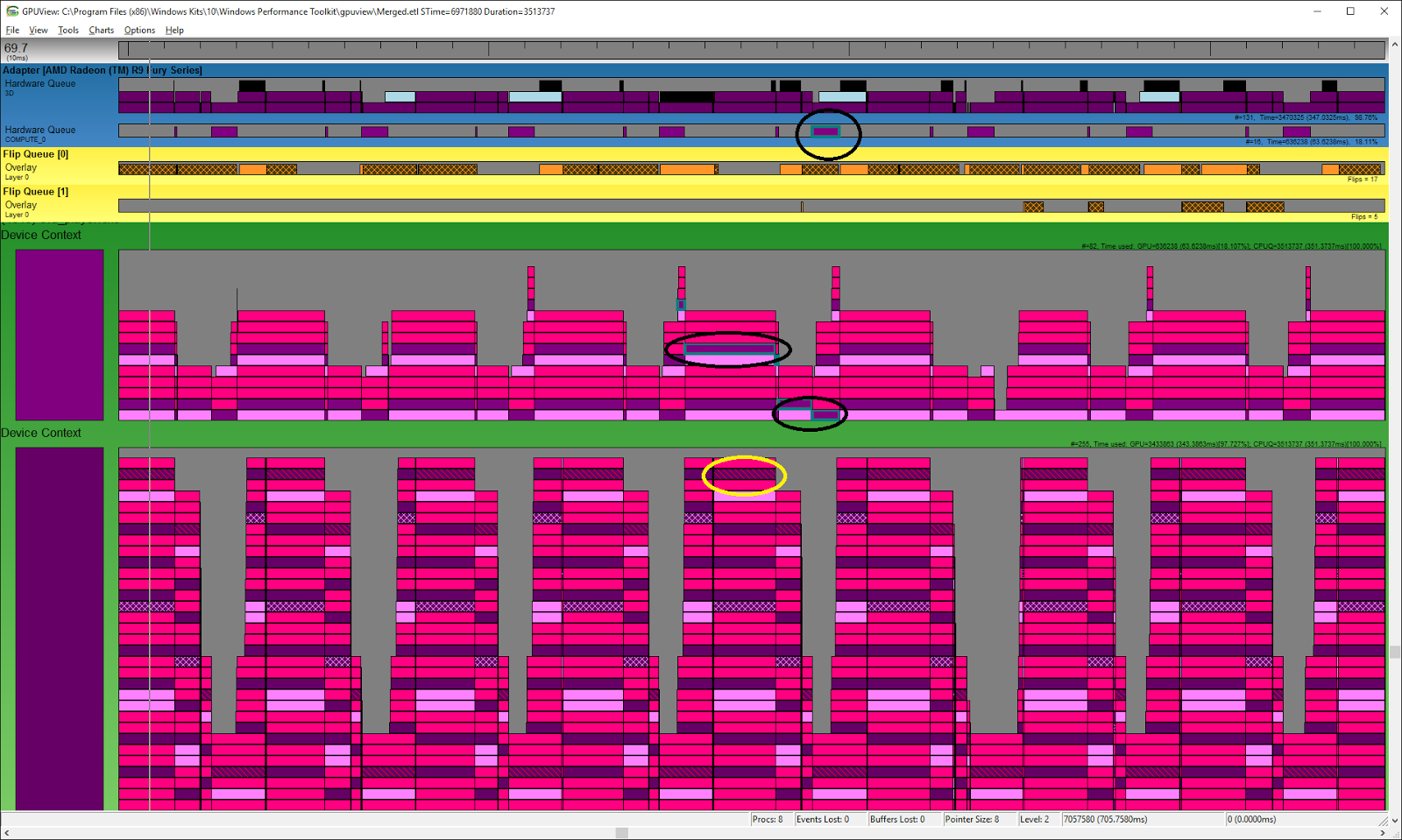

Prozess- und Queue Verhalten der Radeon R9 Fury (links mit Asynchronous Compute, rechts mit deaktiviertem Asynchronous Compute)
Hier sind zwei dedizierte Queues zu sehen, die von der Kontext-Seite (dem Spiel und in diesem Fall vom Time-Spy-Benchmark) in zwei Hardware-Queues überführt werden. Die dazugehören Prozesse können parallel ausgeführt werden. Anders sieht dies aus, wenn Asynchronous Compute abgeschaltet wird. Dann ist nur noch eine Queue zu sehen, sowohl auf der Kontext-Seite wie auch in der Hardware-Queue. Die Hardware bzw. der Treiber hat bei ausgeschaltetem Asynchronous Compute auch keine Möglichkeit aus einer Queue eine zusätzliche mit Compute-Prozessen zu erstellen. Der Time-Spy-Benchmarks gibt vor, wie die Grafikkarten die Prozesse abzuarbeiten hat. Eine Einflussnahme durch den Treiber oder die Hardware soll damit ausgeschlossen sein.
Um den Unterschied zur GeForce GTX 970 darzustellen, ein Blick auf das Verhalten der GeForce GTX 1080:


Prozess- und Queue Verhalten der GeForce GTX 1080 (links mit Asynchronous Compute, rechts mit deaktiviertem Asynchronous Compute)
Grundsätzlich sehen wir ein ähnliches Bild wie bei der Radeon R9 Fury, allerdings werden die Queues bei NVIDIA bereits etwas anders verarbeitet – daher auch der leichte Unterschied in der Darstellung. Es wird aber deutlich, dass die GeForce GTX 1080 eine zusätzliche Compute-Queue verwendet, aus der heraus Direct- und Compute-Prozesse gleichzeitig ausgeführt werden können. Bei ausgeschaltetem Asynchronous Compute ist auch die korrespondierende Compute-Queue verschwunden.
