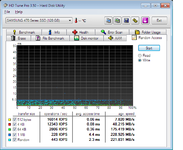
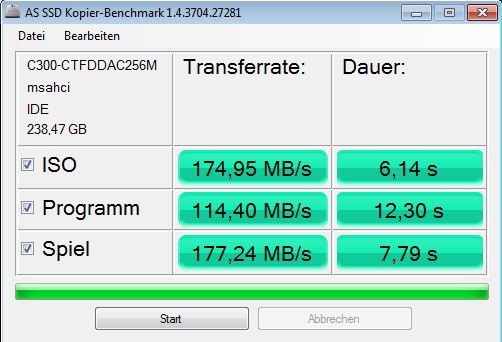
Die geringe Stromaufnahme und hohe Schreibrate sprechen eigentlich für Toggle DDR NAND in der 470er, andererseits hätte dann die Leseleistung noch viel besser ausfallen können und ein SATA3 Interface mehr als gerechtfertigt. Mit 8 Kanälen und normalen NANDs, die ja nur max 40MB/s schaffen, bringt man halt in der Praxis nur etwas mehr als 300MB/s zustande, wie eben die Crucial C300. Mit dem Toggle DDR NANDs hätte man mit 8 Kanälen den SATA3 Bus richtig auslasten können. Wäre ein tolles drive zum Testen der Controller gewesen.
---------- Beitrag hinzugefügt um 20:07 ---------- Vorheriger Beitrag war um 18:23 ----------
Für die IOPS ist es in erster Linie wichtig, die groß die Zugriffszeit ist. Wenn die Software die Anfage zum Lesen einer Datei stellt, dann muß das Betriebssystem via Dateisystem nachsehen, auf welchem LBA diese beginnt und schickt dann die Anfrage zum lesen dieses LBAs an die Platte. Wenn es nicht gerade der erste Zugriff auf das Directory ist, hat das Betriebssystem die Information zum LBA wohl schon im Cache, andernfalls muß es dies vorher auch von Platte lesen. Einige Benchmarkprogramm umgehen das Betriebssystem und fragen den LBA direkt an.
Festplatten wurden früher direkt über Kopf, Zylinder und Sektor angesprochen, heute wird dies per LBA gemacht und die HDD muß diese Daten selbst auf Kopf, Zylinder und Sektor umrechnen und prüfen, ob der Sektor nicht auf einen Reservesektor ausgelagert wurde. SSDs müssen die Adresse des Blockes im NAND finden, wozu wegen des Waerlevelings Tabellen konsultiert werden müssen. Ob diese im RAM gehalten oder vom NAND gelesen werden und wie diese aufgebaut sind, kann da schon einen großen Unterschied ausmachen. Davor kommt ggf. noch eine Abfrage, ob die Daten zufällig im Cache stehen, was ebenfalls Zeit in Anspruch nimmt. HDDs müssen dann den Kopf auf die richtige Spur positionieren, was abhängig von der vorherigen Position schon mal über 10ms brauchen kann und warten, bis der richtige Sektor unter dem Kopf vorbeikommt, was schlimmstenfalls fast eine Umdrehung dauert, dann wird ein Sektor gelesen, die Checksummen werden geprüft und die Übertragung kann beginnen.
Bei einer SSD wird dagegen der oder die NAND Chip(s) angesprochen und nach einer Verzögerung im us Bereich kann der Controller beginnen Daten zu lesen. Da die SSDs intern die Flashchips als RAID0 organisieren, müssen die Daten natürlich noch zusammengestellt, die Prüfsummen gebildet und geprüft werden.
Das alles summiert sich also zu der Latenzzeit auf, bis die ersten Daten über den Bus zum Rechner geschickt werden. Dann kommt natürlich die sequentielle Übertragungsleistung ins Spiel, denn je schneller die Daten jetzt übertragen werden, umso früher die der ganze I/O Request fertig abgearbeitet und der nächste kann beginnen. Da die Betriebssysteme die Datenanfragen der Anwendungen in der Regel auch noch puffern, ist es nicht so leicht den Beginn der Übertragung zu messen und die meißten Benchmarks geben daher nur die gesamte Zeit als Zugriffszeit aus, nicht die Zeit bis zum Begiff der Übertragung. Für die I/Os pro Sekunde ist es aber im Prinzip erstmal egal, wenn diese sequentiell ablaufen. Wenn die gesamte Zeit 100ms wären, dann schaffe ich eben 10 IOPS, egal ob ich jetzt 99ms gewartet und 1ms lang übertragen habe oder umgekehrt.
Heute ist aber im Rechner meißt mehr als ein Kern in der CPU oder gar mehr als eine CPU und es laufen hunderte oder tausende Thread im System mehr oder weniger gleichzeitig, die fast alle hin und wieder mal auf die Festplatte zugreifen wollen. Damit diese nicht alle so lange warten müssen, gibt es NCQ um die Zugriffe möglichst optimal zu ordnen.
Das ist wie beim Fastfoot, der vorne in der Schlange will einen Burger der gerade nicht fertig da liegt und erst gemacht werden muß. Also stellt man seine Bestellung solange hinten an, bittet ihn zu warten und bedient die nächsten, die hoffentlich etwas verlangen, was gerade vorrätig ist. Wenn nicht, so müssen auch die in die zweite Warteschlange und bekommen ihre Bestellung, wenn der Burger hinten fertiggemacht wurde. Im DriveThru ist das ganze halt kaum möglich und wenn, dann hat man nur einen oder zwei Ausweichplätze und der zweite oder dritte, für den Extra was gemacht werden muß, hält gleich die ganze Schlange auf.
Zurück zu den Festplatten heißt das, wenn die Wartezeit 99ms und die Übertragung nur eine ms gedauert hat, dann kann man die Leistung bis zum hundertfachen steigern, wenn in diesen 99ms die Daten andere Anfragen übertragen würden.
Bei HDDs heißt das also, wenn die nächste Anfrage nun Daten lesen möchte, die an der aktuellen Kopfposition stehen oder auf der Weg von der aktuellen zur nächsten, dann bearbeitet man diese zuerst minimiert so die Kopfbewegungen, die ja die meißte Zeit beim Zugriff ausmachen. Bei SSDs gibt es diese große Zeit nicht, aber hier adressiert man immer gleich einen ganzen Bereich im NAND und wenn für eine weitere Anfrage in der Queue Daten aus dem gleich Bereich benutzt werden, so kann man diese gleich mit auslesen. Oder man adressiert schon ein NAND, während auf die Daten des andere noch gewartet wird und hat die Daten der nächsten Anforderung so schneller bereit.
Das zurückstellen von Anfragen die nicht sofort beantwortet werden können kann natürlich dazu führen, daß diese länger brauchen, als wenn nur auf sie gewartet werden würde, da aber andere Anfragen in der Zeit abgearbeitet werden, kommen pro Sekunde mehr Operationen heraus.
Nun habe ich erstmal nur Reads behandelt, Writes sind noch komplexer. HDDs helfen sich meißt mit dem Cache, der kleine Datenmengen aufnimmt und es der Platte erlaubt, die Köpfe zu positionieren und die Daten wirklich zu schreiben, während das Betriebssystem schon glaubt es wäre alle getan, weswegen sie in manchen Benchmarks mit sehr kurzen Zugriffszeiten beim Schreiben kleiner Dateien glänzen können. Mit 8 bis 64 MB kommen sie aber nicht so weit. Bei den SSDs macht das wohl nur der Sandforce 1500, welcher extra einen Goldencap auf der Platine verlangt, damit er die Daten bei Stromausfall auch noch aufs Flash bekommt. Die Schreibgeschwindigkeit einer SSD hängt im wesentlichen davon ab, die viele der Daten direkt in freies NAND geschrieben werden können und wie oft der Controller dafür erst Teile eines Ereaseblocks lesen, den ganzen Block löschen und dann erst schreiben kann. Dazu kommt noch das Wearleveling, welches den Controller dann zuweilen veranlasst Daten eines Blocks in einen anderen zu schreiben, damit auch mal in die Blocks geschrieben wird, die eigentlich statische Daten enthalten und sonst niemals beschrieben würden. NCQ kann auch hierbei helfen die Daten mehrerer Anfragen zusammenzufassen und gemeinsam zu schreiben.


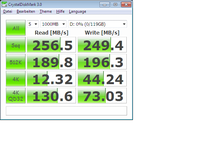
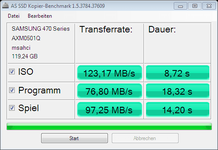
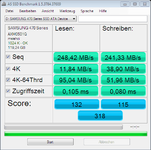
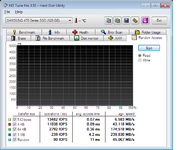





")





")