Dann lies du gerne mal meinen Comment zu der News.
Die Sparmaßnahmen bei Intel gehen weiter. In den vergangenen Wochen musste der Chipriese bereits mehrfach mitteilen, dass Projekte komplett eingestellt, verkauft oder zusammengestrichen werden. Einige Beispiele: Die Netzwerk-Sparte wurde gestrichen, die RISC-V-Projekte wurden gestoppt. Die...

www.hardwareluxx.de
Die aktuellen Entwicklungen bei Intel sind mehr als verständlich und werden durch die letzten vorbeugenden Aktionen wie das Abstoßen von Sparten und Forschung in den Bereichen / Deals / Partnerschaften / Unterstützung durch EU Förderung bei Intel die Löcher füllen können und den Aktienkurs kurz - bis mittelfristig beruhigen.
Ob das wirklich so große Auswirkungen besitzt, kann man vorerst gar nicht genau wissen oder beurteilen. Das werden die nächsten Jahre erst aufzeigen können.
Strategisch ist es ein cleverer Schachzug von Intel.
Auf lange Sicht, werden wir sehen, ob die Strategie aufgeht oder nicht.
Was ich oben mit "Prestige" Auswirkungen meinte, betrifft die Supercomputer / HPC Sparte.
Dort wird angesagt, welcher Hersteller was genau leisten kann.
Das hat weitaus mehr praktische Auswirkungen auf das Enterprise Business als man ggfls. zuerst annimmt.
AMD hat seit der Zen Architektur die Anzahl im Top Ranking verdoppeln können und Intel muss sich auch NVIDIA (dank Übernahmen z.B. von Mellanox für schlanke / schlappe 7 Milliarden US Dollar) dort seit längerer Zeit geschlagen geben.
Intel loses out as Instinct GPUs power the world’s fastest big-iron system

www.theregister.com
Das sind die wahren Gründe für die Probleme von Intel und deren Handeln.
Warum sollte die es auch weiterhin versuchen? Den Krieg können die seit Jahren schon nicht mehr gewinnen.
Also schnappt man der Konkurrenz lieber andere Segmente Mithilfe der Partnerschaft zu ARM weg, um sich zu sanieren und wieder danach forschen zu können mit frischer und sanierter Haushaltskasse.
Ansonten Bezug nehmend auf deine vorigen Anmerkungen:
Teillast beschreibt für mich die Auslastung bis zu 50 % der Cores (bei mir in der CPU Video Konvertierung der Fall).
Desktop, Office (bis auf Excel, Teams und deren Konnektoren für PowerApps und Co) Youtube oder Browsing ist im WS Bereich eher Idle für mich.
Ab zocken (1 bis 8 Cores auch wirklich voll ausgelastet bzw. auf noch mehr Cores verteilt - je nach Sheduler / Engine) gehe ich auch schon eher mit, das dies Teillast wäre.
Als Vergleich, müsste man den Takt der zu vergleichenden CPUs normalisieren (2 GHz Server CPUs und 3 GHz Workstations CPUs ).
Dann hätte man auch eine gute Basis, die Plattformen und CPUs zu vergleichen. Ansonten geht das nicht (rational).
Laut des nachfolgenden Artikels, könnten bei den Saphire Rapids schon noch Energie gespart werden:
It's (probably) not going to kill your latency and it could save you a buck
www.theregister.com
"Power Mode” to its Sapphire Rapids Xeon Scalable processors, which the company claims can reduce per-socket power consumption by as much as 20 percent, in exchange for a performance hit of roughly 5 percent.
According to Intel Fellow Mohan Kumar, the power management feature is particularly effective in scenarios where the CPUs are only running at 30-40 percent utilization. With Optimized Power Mode enabled, he says customers can expect to see a 140W reduction in power consumption on a dual socket system."
Also sollen da angeblich 60 Watt rauszuholen zu sein... Gilt aber wahrscheinlich (leider) nur für die Server CPUs und nicht den Workstations CPUs?
Ansonsten lese dir gerne mal die Artikel zu CXL / PCIe durch. Die Latenzen werden hier auf lange Sicht kein Hindernis darstellen.
Eher die Einführung / Implementierung mit den Partnern. Das dauert einfach lange und kostet Geld, was Intel aktuell einfach nicht (mehr alleine) aufbringen kann / möchte.
Ggfls. wird das dann noch ein Partner übernehmen anstatt Intel selbst.
Nach diesem Artikel könntest du mit deiner Vermutung aber Recht behalten, dass Intel ab Granite Rapids Mithilfe von SK Hynix auf Multiplexer Combined Rank (MCR) memory wechseln möchte / wird (Siehe Anhang).
It was a reasonable enough gut reaction given the many changes happening at Intel in recent months. The chip designer and maker – the last one in the

www.nextplatform.com
Im selben Zuge sollte die Partnerschaft mit ARM dafür sorgen, dass die anvisierte Roadmap inkl. wechsel zu reinen E-Cores im HPC Segment Marktanteile zurück gewinnen werden können (Siehe Anhang).
Ob das dann 2024 / 2025 auch mal besser klappt als mit Saphire Rapids, wird sich dann zeigen...
Schlechter kann es fast schon nicht mehr laufen. 😂
HBM2e wäre (wahrscheinlich) trotzdem die beste Lösung gewesen. Aber wenn es halt Lieferschwierigkeiten gibt, ist DDR5 mit 8000 MT/s halt eine schöne Umgehung.
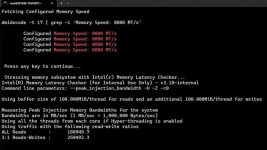
Vielleicht für andere mal als Gefühl zur Einheit von MT/s ~ MT/s ist die Abkürzung für Mega- (oder Millionen-)Übertragungen pro Sekunde!
Als Zahl: 1.008.000 (Millionen) Übertragungen pro Sekunde! 😵
Da kann man aber auch erst mal abwarten, ob die Leistung auch überhaupt später realisiert werden kann (nur 4 DIMMs mit der Peak Leistung read / write auszuwerten, ist da halt noch ein cherry picker Benchmark) .
Für 2025 sollten wir uns bereit halten und ggfls. neue Anschaffungen (falls bis dahin nicht nötig) noch zurückstellen.
Das könnte ein schöner Kampf werden.
Selbst Intel möchte da 128 Cores (im HPC Segment) ankündigen. Vielleicht sehen wir da auch schon PCIe 6.0 inkl. neuen Formfaktoren für NVMe ... Wer weiß.
@dbode: (Herr Schilling)
Können Sie bei Intel dazu noch ein wenig Hintergrundmaterial erhalten?
Auch ein Nachtest, ob die Energieoptionen (angeblich) wirklich 60 Watt beim CPU Package herausholen können wären wirklich interessant zu erfahren!













 Ich nehme mal das
Ich nehme mal das