
nVidia GK110/Geforce 7xx/Geforce Titan [Speku-, News- & Diskussion] (1. Seite lesen!)
Nachdem GK104 nun erschienen ist, wird das Themengebiet in den Sammler von Edge verschoben: http://www.hardwareluxx.de/communit...ches-bei-fragen-erste-seite-lesen-880765.html danke, an dieser Stelle für den Thread.
Hier soll es nun um GK110 gehen.
Short Facts:
Release: Tesla im Q4/2012, Geforce im Q1/2013
Zu erwartene Chips: sollte 7xx zutreffen dann 780, 770. Eine Dualversion kann man offiziel wohl ausschließen.
Daten zum Chip gibt es weiter unten.
1.1 Die Architektur
Nvidia hat auf der GTC viele neue Details zum GK110 verraten.
So soll der 7,1 Milliarden (!) Transistoren schwere Chip zuerst auf der Tesla K20 arbeiten, die gegen Ende des Jahres erscheinen soll. Mit dieser Masse an Transistoren stellt er den bis dato größten Chip der Geschichte dar. Desktoplösungen werden erst 2013 folgen, was zum einen niedrigen Yields als auch der bisher guten Position Nvidias in diesem Markt geschuldet sein kann.
Anders als beim GK104 bestizt GK110 pro SMX zusätzlich 64 DP-Einheiten um dort die Leistungsfähigkeit zu steigern (SP : DP = 3:1). Nicht ganz klar ist allerdings wie diese Einheiten aussehen. Bei Fermi arbeiteten einfach zwei Unified-Shader an einer DP-Berechnung, das hat den Vorteil keinen zusätzlichen Platz für DP-Einheiten aufbringen zu müssen. Würde NV bei GK110 nun wieder einen anderen Weg gehen dürfte die Chipfläche ohne massige erhöhung der Transistordichte nicht unter 600mm² bleiben. Immerhin müssten so 960 wietere Einheiten auf dem Chip untergebracht werden.
Auch der restliche Aufbau ist stark HPC orientiert, so kann ein Thread jetzt mehr Register nutzen als bei GK104 und mit Hyper Q sowie Dynamic Parallelism (Cuda 5.0) finden noch zwei weitere Features Einzug die GK104 nicht bot, aber für Desktopanwender keine Rolle spielen dürften. Allgemein ist GK110 stark Richtung HPC entwickelt worden, da in diesem Bereich der GK104 aufgrund mangenlder Fähigkeiten für DP nicht positioniert ist.

Die-Vergleich von GK110 und GK104. Achtung, die Größe ist nicht Maßstabsgetreu! (siehe weiter unten)
Für Spieler interessant könnte sein das NV angibt die TMUs nicht nur verdoppelt zu haben, sodern sie auch effizienter arbeiten. Ob man als Vergleich "nur" GF110 heranzieht oder wirklich GK104 ist zwar ungewiss, allerdings sprächen auch in letztem Fall die 240 TMUs für ausreichend Texturierleistung.

Bild einer Tesla K20 Karte mit GK110
1.2 kleiner Chart
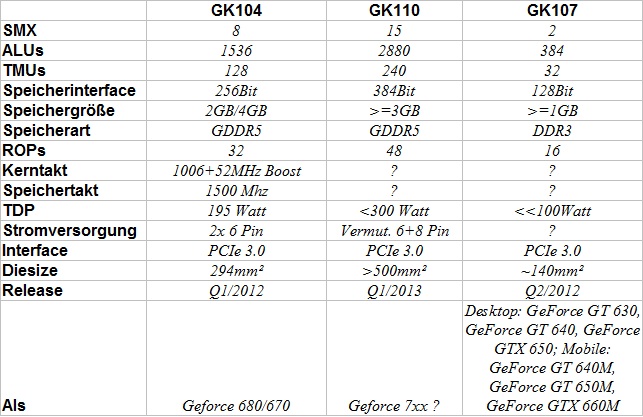
1.3 Aussichten
Leistungsfähigkeit
Da Nvidia vor hat bei der Tesla K20 nur 13 oder 14 SMX zu aktivieren dürfte der Geforce wohl ein ähnliches Schicksal ereilen. Das steigert zum einen die Yields für NV und lässt natürlich auch Spekulationen über eine spätere Version mit allen Einheiten zu.
Ginge man von 13 SMX für die erste Version aus kämen wir bei einem halbwegs realistischen Chiptakt von 900 MHz auf 4,493 TFlops. Das wären immerhin ca. 45% mehr als bei GK104 (ohne Turbo). Dazu kommen noch die 208 verbleiben TMUs, was auch etwas 46% höhere Texturleistung bei 900 MHz entspricht und die um 50% höhere Bandbreite.
Summa Summarum scheinen 50% mehr Leistung also drin zu sein zum GK104, wieviel davon real bleibt muss man natürlich abwarten. Nvidia selbst gibt nur recht schwammige Aussagen über die Leistungsfähigkeit. So soll die DP-Leistung bei >1 TFlops liegen, was bei dem Ratio von 3:1 immerhin 3 TFlops SP bedeiten würde. Für die oben errechneten 4,5 TFlops sollten es dann aber schon 1,5 TFlops DP sein")

Größenvergleich eines GK110 mit ca. 550mm² und einem GK104 mit ca. 295mm² (real sind es 294mm²)
Möglicher Refresh?
Interessant ist natürlich auch was bei einem Refresh zum GK110 drin wäre.
Ein Chip mit vollen SMX und einem höheren Takt von 950 MHz käme auf 5,472 TFlops, also ca. 21% mehr Leistung gegenüber der Version mit 13 SMX. Gleiche 21% gelten auch bei den Texturleistung.
Beim Speicher wird sich dagegen wohl kaum was ändern, denn GDDR5 scheint so langsam an seine bezahlbaren Grenzen zu kommen. Insgesamt wären also 15%+/- Mehrleistung drin um die Zeit bis Maxwell zu überbrücken.
Ob es so kommt weiß natürlich nur Nvidia selbst.
1.4 Linkliste
Größter Chip der Welt mit 7 Mrd. Transistoren und Hyper-Q (Golem, de)
GTC 2012: GK110-Grafikchip hat bis zu 2880 Shader-Kerne (heise, de)
GTC 2012: Die GK110-Schöpfer über Performance und zukünftige Herausforderungen (heise, de)
Nvidia gibt erste Infos zum großen Kepler GK110 bekannt (computerbase, de)
GK110: Weitere Details zur größten GPU der Welt [Update: Inside Kepler] (pcgh, de)
nVidias GK110-Chip mit 2880 Shader-Einheiten - im Gamer-Bereich aber erst im Jahr 2013 (3DCenter, de)
Ich bitte alle User die an diesem Thread teilnehmen sich an eine gewisse Netiquette zu halten. Bitte lasst den Thread auch nicht zu einem Flamewar Rot gegen Grün verkommen sondern spekuliert aufgrund bekannter Fakten über den GK110. Versucht eigene Meinungen so wenig wie möglich in euren Post einfließen zu lassen, ebenso sind eure Wünsche und Kaufpläne evtl für andere User uninteressant.
Über ein Danke würde ich mich natürlich sehr freuen
nVidia GK110/Geforce 7xx [Speku-, News- & Diskussionsthread]

Dieshot eines GK110
Dieshot eines GK110
Nachdem GK104 nun erschienen ist, wird das Themengebiet in den Sammler von Edge verschoben: http://www.hardwareluxx.de/communit...ches-bei-fragen-erste-seite-lesen-880765.html danke, an dieser Stelle für den Thread.
Hier soll es nun um GK110 gehen.
Short Facts:
Release: Tesla im Q4/2012, Geforce im Q1/2013
Zu erwartene Chips: sollte 7xx zutreffen dann 780, 770. Eine Dualversion kann man offiziel wohl ausschließen.
Daten zum Chip gibt es weiter unten.
1.1 Die Architektur
Nvidia hat auf der GTC viele neue Details zum GK110 verraten.
So soll der 7,1 Milliarden (!) Transistoren schwere Chip zuerst auf der Tesla K20 arbeiten, die gegen Ende des Jahres erscheinen soll. Mit dieser Masse an Transistoren stellt er den bis dato größten Chip der Geschichte dar. Desktoplösungen werden erst 2013 folgen, was zum einen niedrigen Yields als auch der bisher guten Position Nvidias in diesem Markt geschuldet sein kann.
Anders als beim GK104 bestizt GK110 pro SMX zusätzlich 64 DP-Einheiten um dort die Leistungsfähigkeit zu steigern (SP : DP = 3:1). Nicht ganz klar ist allerdings wie diese Einheiten aussehen. Bei Fermi arbeiteten einfach zwei Unified-Shader an einer DP-Berechnung, das hat den Vorteil keinen zusätzlichen Platz für DP-Einheiten aufbringen zu müssen. Würde NV bei GK110 nun wieder einen anderen Weg gehen dürfte die Chipfläche ohne massige erhöhung der Transistordichte nicht unter 600mm² bleiben. Immerhin müssten so 960 wietere Einheiten auf dem Chip untergebracht werden.
Auch der restliche Aufbau ist stark HPC orientiert, so kann ein Thread jetzt mehr Register nutzen als bei GK104 und mit Hyper Q sowie Dynamic Parallelism (Cuda 5.0) finden noch zwei weitere Features Einzug die GK104 nicht bot, aber für Desktopanwender keine Rolle spielen dürften. Allgemein ist GK110 stark Richtung HPC entwickelt worden, da in diesem Bereich der GK104 aufgrund mangenlder Fähigkeiten für DP nicht positioniert ist.
Die-Vergleich von GK110 und GK104. Achtung, die Größe ist nicht Maßstabsgetreu! (siehe weiter unten)
Für Spieler interessant könnte sein das NV angibt die TMUs nicht nur verdoppelt zu haben, sodern sie auch effizienter arbeiten. Ob man als Vergleich "nur" GF110 heranzieht oder wirklich GK104 ist zwar ungewiss, allerdings sprächen auch in letztem Fall die 240 TMUs für ausreichend Texturierleistung.
Bild einer Tesla K20 Karte mit GK110
1.2 kleiner Chart
1.3 Aussichten
Leistungsfähigkeit
Da Nvidia vor hat bei der Tesla K20 nur 13 oder 14 SMX zu aktivieren dürfte der Geforce wohl ein ähnliches Schicksal ereilen. Das steigert zum einen die Yields für NV und lässt natürlich auch Spekulationen über eine spätere Version mit allen Einheiten zu.
Ginge man von 13 SMX für die erste Version aus kämen wir bei einem halbwegs realistischen Chiptakt von 900 MHz auf 4,493 TFlops. Das wären immerhin ca. 45% mehr als bei GK104 (ohne Turbo). Dazu kommen noch die 208 verbleiben TMUs, was auch etwas 46% höhere Texturleistung bei 900 MHz entspricht und die um 50% höhere Bandbreite.
Summa Summarum scheinen 50% mehr Leistung also drin zu sein zum GK104, wieviel davon real bleibt muss man natürlich abwarten. Nvidia selbst gibt nur recht schwammige Aussagen über die Leistungsfähigkeit. So soll die DP-Leistung bei >1 TFlops liegen, was bei dem Ratio von 3:1 immerhin 3 TFlops SP bedeiten würde. Für die oben errechneten 4,5 TFlops sollten es dann aber schon 1,5 TFlops DP sein
Größenvergleich eines GK110 mit ca. 550mm² und einem GK104 mit ca. 295mm² (real sind es 294mm²)
Möglicher Refresh?
Interessant ist natürlich auch was bei einem Refresh zum GK110 drin wäre.
Ein Chip mit vollen SMX und einem höheren Takt von 950 MHz käme auf 5,472 TFlops, also ca. 21% mehr Leistung gegenüber der Version mit 13 SMX. Gleiche 21% gelten auch bei den Texturleistung.
Beim Speicher wird sich dagegen wohl kaum was ändern, denn GDDR5 scheint so langsam an seine bezahlbaren Grenzen zu kommen. Insgesamt wären also 15%+/- Mehrleistung drin um die Zeit bis Maxwell zu überbrücken.
Ob es so kommt weiß natürlich nur Nvidia selbst.
1.4 Linkliste
Größter Chip der Welt mit 7 Mrd. Transistoren und Hyper-Q (Golem, de)
GTC 2012: GK110-Grafikchip hat bis zu 2880 Shader-Kerne (heise, de)
GTC 2012: Die GK110-Schöpfer über Performance und zukünftige Herausforderungen (heise, de)
Nvidia gibt erste Infos zum großen Kepler GK110 bekannt (computerbase, de)
GK110: Weitere Details zur größten GPU der Welt [Update: Inside Kepler] (pcgh, de)
nVidias GK110-Chip mit 2880 Shader-Einheiten - im Gamer-Bereich aber erst im Jahr 2013 (3DCenter, de)
Thread im Aufbau!
Ich bitte alle User die an diesem Thread teilnehmen sich an eine gewisse Netiquette zu halten. Bitte lasst den Thread auch nicht zu einem Flamewar Rot gegen Grün verkommen sondern spekuliert aufgrund bekannter Fakten über den GK110. Versucht eigene Meinungen so wenig wie möglich in euren Post einfließen zu lassen, ebenso sind eure Wünsche und Kaufpläne evtl für andere User uninteressant.
Über ein Danke würde ich mich natürlich sehr freuen
Zuletzt bearbeitet:




")



