Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Bin jetzt auf ein altes Setting gegangen (hatte es unter 6400 TM5/Karhu gespeichert ^^)
Also bin gespannt, ob das stabil war (hatte damit bei einem Game Probleme, was im Nachhinein aber an etwas anderem lag) .
Fehler 6 = IF/IMC überlastet bzw zu wenig oder zuviel? Saft . VDIMM / VSOC erhöhen, VDDQ höher. ProcODT hoch oder runter?
Fehler 12 sollte sich dann vermutlich erledigt haben?
Würde eher wiederstandswerte senken 43 30 43 43 bzw 40 30 40 40. Die Rtt bin ich übergegangen sie vom Mainboard selbst trainieren zu lassen. Habe das Ram Training verlängert boot brauch jetz 70sek. Bei 64 GB.
Ich würde nicht mit der Spannung höher gehen. Sonst kommste evtl. in ein thermal Problem rein.
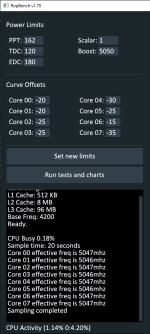
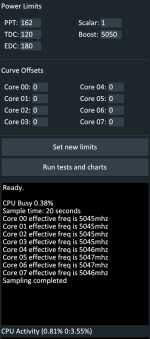
Mit Ropbench kann man mit einem startbefehl statt der peak clock die effektive clock über Zeitraum x zb. 20 sekunden messen. (Siehe readme) Habe so lange co gesenkt. Bis dort kein mhz gewinn durch weiteres senken möglich war.
hab da jetzt auch mal ein bisschen mit rumgespielt. Hatte meinen CO vorher ausgelotet mit CC etc. und würde gerne herausfinden ob ich im Clockstretching bin. Allerdings werde ich da nicht so wirklich schlau draus.
Ein Run mit meinen CO Werten und ein Run ohne CO.
Kann ich da nun was draus ableiten?
Siehst du eh nur wenn du Last hast. z.B. CB und in HWInfo siehst du den Unterschied. RB bringt m.E. keine Last die Stretching sichtbar macht. Lt RB müsste mein Core 0 auch echt übel sein. Das ist definitiv falsch.
Falls es mit CB nicht geht, versuche es mit CPUZ (Stress CPU). Hier kannst du auch auf 2 Threads reduzieren. Um jeden Kern einzeln zu testen muss das Programm gestartet sein. Danach im Taskmanager den CPU-Kern zuweisen. 0 und 1 = Core 1
2 und 3 = Core 2 usw. Dann sollten die Unterschiede sichtbar werden. Sollte aber eigentlich auch mit CB funktionieren.
Schau mal in den Taskmanager. Bestimmt ist fast kein RAM mehr belegt. Es ist dann inrgendein undefinierter Zustand durch einen Fehler aufgetreten und TM5 ist ausgestiegen.
Genau umgekehrt.
Jedoch wird weiterhin das Boosting System bzw die Algo angepasst.
Dass wir kein throttle mehr im 0 CO Zustand sehen, ist sehr schön.
Endlich.
Das heißt, dass das FIT VID-Spannungslimit , aka das Throttle Limit bei hohen VID requests
Nahezu gelöst is. Bzw "it is weighted on CAC" ~ der Fokus darauf ist auf der Lastart [CAC] (erkannt durch Last & instruction sets)
Traurig oder nicht,
Es ist sehr schön zu sehen.
Natürlich könnte der Ropbench Dev die Instruction-set Art abändern
Damit es nahezu ähnliche AVX2/FMA lasten wiederspiegelt
Doch dann fällt das nicht mehr als "versprochener Game-Boost" clock.
Der Boostclock bei nicht-SSE Lasten, wurde nämlich niemals garantiert.
Was garantiert wurde ist der "Base Clock" . Welcher bei jeglicher Art von Last eigenhalten werden muss.
Generell wurde der Boostclock niemals konkret garantiert, sowie hatte keine exakte Beschreibung welche Art von Boost es sein muss.
Siehe Marketing-Fiasko? , die Problematik bei Matisse ~ welcher die Boosting Targets nicht erreichen konnte;
Da , nun , TechMedia einerseits nicht anerkennen konnte wie das Zen-Ecosystem funktioniert
~ andererseits von AMDs Community Support-Team , aka Mr Hallock Robert + Co - es ungenügend für den Hauptmarkt erklärt wurde.
Teils durch AMDs eigenen NDA Regelungen.
Ich denke zu ehmaliger AMD Pioneer Zeit, war "die Angst" auf Konkurenz noch relativ hoch
Mr. Hallock hat seine Arbeit sehr gut erledigt und war (zu der Zeit wo er frei war) , ein sehr guter Lehrer und Helfer
~ damit die Community vestehen darf wie das komplexe Ryzen-Ecosystem nun funktioniert.
Sehr viele Pyramiden-Fehler, sind weiterhin Schuld daran dass die Community nicht versteht wie man mit dem Boosting System arbeiten soll
Aber solange AMD selbst fortschritt macht und alle Nutzer (mit neuer OC-Mentalität) glücklich sind ~ sollte alles ok sein.
Der Boostclock bei nicht-SSE Lasten, wurde nämlich niemals garantiert.
Was garantiert wurde ist der "Base Clock" . Welcher bei jeglicher Art von Last eigenhalten werden muss.
Da zb RDNA's AVFS ~ weitaus komplexer ist als Ryzen's
Und ebenso das Hauptziel "Gaming" ist
Haben wir hier:
~ Baseclock
~ Boostclock
~ Gameclock
Gameclock wäre der SSE clock
Boostclock wäre der curve AVFS peak clock
Baseclock ist der Render/Compute clock.
Ich hoffe man versteht es.
EDIT:
Wenn man das ganze dann als "per-kern Last" ausbreitet
Ist der Faktor von Clock/CoreAmount ~ Load
Dynamisch, je nach Laststärke+Lastart (CAC) sowie von SampleLeakageFactor (FIT/VID Max)
Dem PowerBudget (cTDP) bzw sPPT, cTDP (short PPT/constant PPT or TDP)
Und mitterweile umso relevanter ~ der Fokusierten Application
Sowie zuletzt die Architetur Thermal limiters (short THM & Hardcap TjMAX)
Angereit als Hirarchy wäre:
First stage power limiter (TDP, EDC)
First stage thermal limiter (THM , TjMAX)
Front?end VID limiter (FIT-VID Limiter für single und n-Kern Last)
Frontend Boosting Scalar ~ Loadtype clock hold duration within FIT (amount of allowed errors in n/time)
Sehr schön beschrieben. Danke sehr. Zumindest CPUZ kann doch als "Gamelastindikator" genutzt werden.
Welche Game-Last erzeugt Timespy & Co, bzw die Spiele selber? Wenn ich den Demo-Bench von Sottr laufen lasse, habe ich idR eine weitaus höhere - zugegebenermaßen Allcore" Last. Scalar wirkt sich dort bestimmt nicht mehr so stark aus. Die Belastung ist da höher als die Ropebench erzeugt. Denke mal Shader Kompilieren gehört nicht zu typischen Gamelast.
TimeSpy normal bench müsste SSE sein
Timespy CPU bench sollte AVX(2) sein
Ich bin mir leider unsicher ob TimeSpy mit AVX512 skaliert oder es ein reines Cache Thema ist.
SOTTR ist ein SSE titel - fast alle Games sind das. *
Hier müsste ich wieder lügen, da ich nicht zuu sehr mit der Engine vertraut bin
Ich benchmarke selten Spiele. Sie haben für mich leider ein großes Problem , und die variable wären die Developer dieses.
// Wie gut und effizient sie Instruction-Set Packages senden, bzw wie effizient jede Aktion im Titel verarbeitet werden kann. Codesize usw.
Moment,
"Ich nutze Spiele für aussagekräftige Daten nicht."
"Ich nutze synthetische Programme für den Zweck welche sie entwickelt wurden . Analysistische, welche jedoch keinerlei dynamisch genug sind, als das man sie als [real world] bezeichnen kann."
Synthetische Programme sind dafür da gezielt etwas spezifisches zu testen. Niemals die Gesammtperformance
Sollte das Ergebniss dann zufriendestellend sein und es dort skalieren worin das Programm sich fokusiert
Danach erst kann man verifizieren ob X Titel mit dieser Änderung skaliert oder nicht.
Es macht die Änderung nicht weniger wirksam oder weniger-bedeutend, bloß gibt es einem die Chance Variablen zu isolieren weswegen es nun mal "nicht skaliert".
So sehe ich das,
Ich hoffe man versteht
* The Devison 2 , müsste ein AVX Titel sein. Riftbreakers Demo ist ein guter Cache/Mem Benchmark
Project Hydra kann das teils auslesen, aber auch das Thema hier ist sehr komplex.
Für die CPU spielt nur "n-Instructionsets/Time" eine Rolle.
Wie viele Kerne werden ausgelastet. Reicht der L2 & L3 Cache.
Sind noch genug freie plätze im Branch-Predictor frei, um instruction-sets zu bearbeiten oder müssen sachen verlangsamt und verzögert werden.
Natürlich auch hier spielt die Anzahl an Kernen (verbreitete last) eine Rolle wie effizient die Datasets (die größe dieser instruction-chunks)
Nun bearbeitet werden können, bzw in kleine chunks zusammengeschnitten werden können (OpCache) ~ bevor sie an dem Branch-Predictor bzw generell subsystem gesendet werden.
Hier zb spielt die Frequenz der Kerne keine Rolle
Und IOPS ist das wichtigste. IPC wäre ein anderer Name dafür.
Processable instructions per target clock/time ~ within Input/Output time per sec.
EDIT:
IOPS & ROP's sind sich hier sehr ähnlich.
Solange ein kalkulierter hoher MHz Wert auf basis von ROPs existiert
"Kann" es schnell und effizient sein. Jedoch heißt es nicht dass der Titel auch effizient und gezielt die gesammte CPU nutzt.
Somit sind Spiele keine wirklichen Benchmarks für mich. Nicht für den Zweck welche ich sie brauche. Und zwar analytischem.
Spiele skalieren nur, wenn die Gesammtleistung verbessert wird ~ jedoch nicht jedes Spiel skaliert gleich.
Somit ist "das Tracking der Gesammtleistung" mit Spielen eher sub-optimal.
Haha, danke an jedem welcher meine langen Beiträge liest. ♥️


") . VDIMM / VSOC erhöhen, VDDQ höher. ProcODT hoch oder runter?
. VDIMM / VSOC erhöhen, VDDQ höher. ProcODT hoch oder runter?

")