Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Außerdem verschwende ich ungerne Threadspace, für die Antwort einer Person - besonders, sollte ich nichts lernbares anhängen können.
Wie dem auch sei.
Ich kann nicht jedem hinterherrennen~
Wenn du denkst dass ich es angreifend meine, so soll es so bleiben
Mehr als versuchen es neutral zu erklären, da Daten keine emotionale basis haben
Kann ich nicht.
Du bist alt genug und suchst dir selbstständig aus, wie du dazu stehen magst.
Ich kann nur das beilegen:
Das soll kein Angriff an OC/XOCer sein.
Aber im Grundgenommen verstehen wenige was die verwendeten Tools überhaupt testen oder derren schwächen.
Nur ob sie schneller oder langsamer sind.
Bitte lass uns darüber nicht reden.
Es ist schwierig nicht angreifend verstanden zu werden.
Das ist nicht meine Intention. So bin ich nicht
Ab hier liegt alles an dir, wie du die Sache sehen bzw verstehen möchtest.
Wenn es dich glücklich macht, dass es angreifende Worte wären ~ dann bin ich auch damit zufrienden
Von meiner sichtweise aus, wird es wirklich lästig leuten nachzurennen.
Ob du dich betroffen siehst, gehöre dir alleine.
Ich weiß was ich meine und ich meine es nicht angreifend und nicht dich fokussiert. Jedoch ist es Realität für mich.
Außerdem kaam ich nicht hier her um mir Freunde zu suchen.
Weder Datassheets, noch die Ryzen Architecture ändern sich durch "eine nette Freundschaft".
Daten haben keine emotionale ebene. Nur eine Missinterpretation des Forschers.
Ebenfalls kann ich die Spannung von 1,35v bei 6200 30-37 nicht fahren, da rattern die Fehler bei Memtest nur so durch,. Während ich das hier schreibe läuft er mit ner Spannung von 1,38v seit ca 30 min im 8.Cycle Fehlerfrei. Temps sind auch im grünen Berreich bei ca 53°C im Memtest
Nein.
Dem abgesicherten Modus fehlen Powersaving features, sowie core-sleep features.
Es macht keinen Sinn im abgesicherten Modus zu testen. Ebenso AIDA nicht.
Benchmate, priority->realtime, 5 fenster öffnen und dann diese als (2B) durchrennen.
Win 11. DailyOS
Median 304.8 // -10, +11 , geht besser, noch leicht unstabil
Das letzte AGESA hat mal wieder an VDDG bzw ODT geschraubt und mir die Stabilität ruiniert. WIP
So in etwa kann es aussehen (gestern), obwohl ich hier gerade kein DDR5 system habe
// Die ehmaligen Posts haben bessere AM5 Screenshots.
Beide sind zurück zu deren Eigentümer/Firma.
Ich hatte Q3 2022-Juni 2023 meinen Spaß mit AM5 (7900X, 7900X, 7950X, 7800X3D, 7800X3D) & July bis November meinen Spaß mit LGA1700.
Doch @Veii
Ich habe alles gelesen und auch diese Regeln gelesen. Ich bin auch dankbar dafür!
Aber:
Es ergibt in meiner Welt einfach keinen Sinn. Auf OCN stehen im AMD DDR5 OC Thread beispielsweise folgende Regeln:
1.) tWRRD = tWRWR_DD
tWRRD ist bei mir derzeit auf "8". Dementsprechend müsste ich tWRWR_DD auch auf die "8" packen. Bei mir ist es aber auf "7" stabil. Soll ich es jetzt trotzdem um 1 erhöhen?
In Deinen Regeln sagst Du "tWRRD = 4". Wenn ich tWRRD = tWRWR_DD beide auf "4" setze, dann bootet mein System nicht mehr.
2.) tRDRD_DD = tWTRS
tRDRD_DD steht bei mir auch auf 7 und ist stabil. Das dürfte es aber normalerweise gar nicht sein, weil Du in Deinen Regeln sagst: "tRDRD = 8". Mein Wert ist hier um 1 zu niedrig. Zudem: Wenn ich tWTRS auf 7 setze, dann ist es nicht mehr die Hälfte von tRRDS.
Ich verstehe jetzt gerade gar nichts mehr. Ich habe mir alle Regeln angeschaut, aber sie funktionieren nicht zusammen.
Wie sollte ich denn meine Timings Deiner meiner nach setzen, wenn es Stand jetzt so bei mir stabil ist?
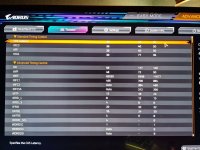
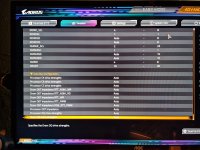
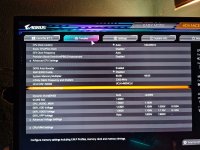
VSoC = 1.23 V
VDDP = 1,15 V
VDD = 1,36 V
VDDQ = VDDIO = 1,28 V
VDD MISC = 1,1 V
VDDG = 1,15 V (beide)
Ach ja, tRDWR = 16 ist korrekt bei mir und tWRWR steht auch auf 7 und wäre damit auch um 1 zu hoch.
Da ZenTimings bei mir keine Daten ausliest, hier mal meine Werte aus dem Bios:
Läuft bisher stabil, werde mich heute Nachmittag mal an folgenden Werten orientieren (für 7200):
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
Fällt jemanden vielleicht jetzt schon etwas gravierendes an dem jetzigen Setup auf, was definitiv geändert werden sollte?
Bitte schneide die Screenshots richtig und nicht selektiv
Außerdem verschwende ich ungerne Threadspace, für die Antwort einer Person - besonders, sollte ich nichts lernbares anhängen können.
Wie dem auch sei.
Ich kann nicht jedem hinterherrennen~
Wenn du denkst dass ich es angreifend meine, so soll es so bleiben
Mehr als versuchen es neutral zu erklären, da Daten keine emotionale basis haben
Kann ich nicht.
Du bist alt genug und suchst dir selbstständig aus, wie du dazu stehen magst.
Ich kann nur das beilegen:
Ab hier liegt alles an dir, wie du die Sache sehen bzw verstehen möchtest.
Wenn es dich glücklich macht, dass es angreifende Worte wären ~ dann bin ich auch damit zufrienden
Von meiner sichtweise aus, wird es wirklich lästig leuten nachzurennen.
Ob du dich betroffen siehst, gehöre dir alleine.
Ich weiß was ich meine und ich meine es nicht angreifend und nicht dich fokussiert. Jedoch ist es Realität für mich.
Außerdem kaam ich nicht hier her um mir Freunde zu suchen.
Weder Datassheets, noch die Ryzen Architecture ändern sich durch "eine nette Freundschaft".
Daten haben keine emotionale ebene. Nur eine Missinterpretation des Forschers.
...
ich kann dir nicht folgen, anscheinend aber auch Aufgrund deiner Schreibweise - war aber der Auffassung weil du mich direkt zitiert hast das du auch mich damit gemeint hast ^^
nun denn, egal... dein technischer Input ist überragend und nur darum sollte es hier weiterhin gehen
Hier PYPrime2.2 mit "nur" DDR5-6000. Ich habe gemerkt, dass mehr Takt zumindest mit diesem RAM nicht wirklich mehr Geschwindigkeit bringt. Die bisher geposteten Ergebnisse scheinen das eher zu bestätigen.. ?
Starke Werte und straffe Timings. Kann man nicht anders sagen für 64 GiB! Was erreichst Du damit für eine Latenz?
Ich habe halt noch nie DDR5-6000 ausprobiert, sondern direkt mit DDR5-6400 angefangen und seitdem "wurschtel" ich damit rum.
Ich weiß auch nicht, ob sich das mit meinen 2x32 GiB 6800er A-Dies "lohnt" so tief zu gehen. Auf der anderen Seite sind Deine Werte klar besser als meine.
Starke Werte und straffe Timings. Kann man nicht anders sagen für 64 GiB! Was erreichst Du damit für eine Latenz?
Ich habe halt noch nie DDR5-6000 ausprobiert, sondern direkt mit DDR5-6400 angefangen und seitdem "wurschtel" ich damit rum.
Ich weiß auch nicht, ob sich das mit meinen 2x32 GiB 6800er A-Dies "lohnt" so tief zu gehen. Auf der anderen Seite sind Deine Werte klar besser als meine.
Die Werte solltest du mit deinem Kit leicht nachstellen können. Ich habe auch einiges mit meinem, eher durchschnittlichen, M-Die Kit probiert. Je höher ich aber mit dem Takt wollte, desto mehr Kompromisse musste ich wiederum bei den Timings eingehen, sodass die Latenz trotz des höheren Taktes nicht besser wurde..
Das ist ja fast schon missbrauch der Module aber ich will mal sehen was die Rams für das Intel System auf dem Ryzen hergeben...also werde ich mal hier starten.
ich kann dir nicht folgen, anscheinend aber auch Aufgrund deiner Schreibweise - war aber der Auffassung weil du mich direkt zitiert hast das du auch mich damit gemeint hast ^^
nun denn, egal... dein technischer Input ist überragend und nur darum sollte es hier weiterhin gehen
Das Problem war, dass ich memOC sehr seriös ansehe und auch nahe-zu Perfektion erwarte. Als Arbeit/Forschung und nicht als Hobby.
Mir wurde viel zu oft research-blödsinn gezeigt und man stand zu seinem Ergebnis naive, obwohl selbst nach der Erklärung weswegen man etwas übersehen hatte, man weiterhin zu seinem "flawed-tested" Ergebnis stand anstelle zu versuchen nochmal zu testen.
Ich hatte bei genau der selben Schreibweise auch nicht mehr erwartet und das war ein Fehler. Ich gab dir ebenso keine Möglichkeit zu zeigen was du getestet hast, und das war auch ein Fehler.
Ich sollte generell diese Fehler vermeiden und dann nicht grob zu Leuten sein, selbst wenn ich finde dass man manchmal ... komische Fragen stellt.
Wo man sich sehr viel mühe gibt so gut es geht nicht missverstanden zu werden.
Ich bin nur da um etwas auszuhelfen und nicht Leute zu kritisieren welche man nicht kennt.
My bad, sorry !
~ ich hätte es netter formulieren können, und definitiv nachsichtiger sein sollen. 🙇♂️🙇♂️
Nicht jeder sieht es gleich und will einfach nur Spaß haben.
Es stört mich dann zwar dass man sich selbst als falsches Beispiel darstellt (example Buildzoid mit dem tREFI) und das dazu führt dass mehrere Leute den selben Blödsinn fortfahren = mehr Arbeit für mich
Aber ich muss lernen geduldiger zu werden. Tut mir leid~
Ah und danke für die nettere Antwort.
ASRock bekommt es weiterhin nicht hin Renesas OC Stepping (sind 3) freizuschalten. Und mit mir möchte keiner zusammenarbeiten;
Nun AMD ~ ASRock , die Schuld liegt an beiden.
AMD möchte korrekten EC Zugriff und keine korrupten sticks.
ASRock bekommt es halb hin mit zb dem Z790 NOVA, jedoch auch nicht ganz richtig.
Schwierig . . . aber dennoch irgendwo peinlich. An alle Boardpartner.
Nur ASUS kann es, aber lässt es ebenso nur auf dem GENE zu.
// Ich frage mich ob nur das GENE ein "specs-breaking" board sein darf. Den das Verhalten macht keinen Sinn für mich. Auch nicht von der Business-Seite.
Leider, minimal Verlust ist an den potentiellen Writes mit kaviats
Die CCDLWR Regel gehört nicht mir.
Der WTRS = RRDS/2 exploit jedoch schon.
Laut den offiziellen Dokumenten hat RDRDSC_L = (CCDL-ReadBurstChop+PhyDly bzw OdtEnableDelay) zu sein
Und WRWRSC_L (SG) = CCDLWR-WriteBurstChop+ODTEnableDly)
Dann wäre tRDWR = LD+tBURST+PhyDly+WPRE
Das sind offiziellen AMD™ Formeln für/von dem IMC. Für DDR4 & DDR5.
Da DDR5 standalone ist, gehe die tBURST (interface, momentan 3 nCK) Formel nicht und der minimum delay ist Read/WriteBurstLength /2 (RBL & WBL = 16, sprich 8 = burstchop)
^ Der echte und wahre Delay on dem Standalone! DIMM Stick. Ein Strobe pro Seite.
Da es allerdings von Read zu Write wäre, haben wir nur den BurstChop und nicht den kompletten Roundtrip delay aka RBL oder WBL.
RBL = ReadBurstLength
BL = BurstLength
BC = BurstChop
Ich schreibe momentan RBC (ReadBurstChop) damit man versteht was ich meine.
tBURST = BurstChop , jedoch auf der Host Seite (CPU).
In AMDs fall müsste tWRRD ebenso (CWL+tBURST+WTR_L(S)) = sein,
Done write to Read. Aber ...
AMD liebt es Asse aus (der Rückwand) bzw "dem Magischen Zylinder" zu zaubern und tWRRD wäre theoretisch instant *. Somit folgen sie deren eigenen Specs nicht.
Nun 1 delay da Phy/ODTEn auch einen hat, jedoch nur diesen einen "action delay". Für generell jedes timing welches ein transition-timing/transition-schritt wäre. * tWRRD;
Ist ein Transition delay und ein ausgedachter von AMD von einem fertigen Write zu einem Read.
Beide eigentlich, tRDWR & tWRRD sind transition timings.
// Eigentlich ... hat WRRD genau gleich von WTRL oder WTRS zu sein 🤔🤔 ... eventuell +1, ich müsste genauer nachdenken
Und beide können das gesammte Set verlangsamen.
Ebenso sind SC_Longs eine AMD Sache.
Im Grundegenommen hat es tRDWR_SG & _DG zu sein
SG wäre same group aka _Short, und wäre hier CCDS bzw tBURST (same thing)
Für den Stick hat CCDS auch bekannt als BurstChop, nun 8 zu sein. Wie man es als BC8 timing kennt.
Es ist der minimum Delay, welcher für einen gesammten Strobe von einem ende zum anderen ende , durch alle IC's gebraucht wird.
Dass wir 8 ICs haben und der standart BC8 wäre ~ ist aber reiner Zufall.
_DG hat dann der Roundtrip delay zu sein ~ kurzgefasst RBL oder WBL
// und nein, WRWR_DG auf 12 ist falsch !!, der delay hat 16 oder 32 zu sein Nur sollten es nicht-AMD Nutzer lesen.
Sorry, ich schweife ab;
* tWRRD;
Gehört auf dem kleinsten Wert für Single Sided DIMMs
Und hat ein delay zu haben für Dual-Sided dimms.
Abseits dass mir AM5 PPR Dokumente fehlen, macht AMDs formel schon bei AM4 keinen Sinn 🤭
Auch nicht von derren denkweise aus. Die Formel ist einfach nicht richtig. Besonders wenn sie eher SC_Long als delay nehmen anstelle RDWR oder WRRD.
Aber:
Es ergibt in meiner Welt einfach keinen Sinn. Auf OCN stehen im AMD DDR5 OC Thread beispielsweise folgende Regeln:
1.) tWRRD = tWRWR_DD
tWRRD ist bei mir derzeit auf "8". Dementsprechend müsste ich tWRWR_DD auch auf die "8" packen. Bei mir ist es aber auf "7" stabil. Soll ich es jetzt trotzdem um 1 erhöhen?
In Deinen Regeln sagst Du "tWRRD = 4". Wenn ich tWRRD = tWRWR_DD beide auf "4" setze, dann bootet mein System nicht mehr.
2.) tRDRD_DD = tWTRS
tRDRD_DD steht bei mir auch auf 7 und ist stabil. Das dürfte es aber normalerweise gar nicht sein, weil Du in Deinen Regeln sagst: "tRDRD = 8". Mein Wert ist hier um 1 zu niedrig. Zudem: Wenn ich tWTRS auf 7 setze, dann ist es nicht mehr die Hälfte von tRRDS.
Ich verstehe jetzt gerade gar nichts mehr. Ich habe mir alle Regeln angeschaut, aber sie funktionieren nicht zusammen.
Wie sollte ich denn meine Timings Deiner meiner nach setzen, wenn es Stand jetzt so bei mir stabil ist?
Ich verstehe leider einiges von AMDs Denkweise nicht.
Ein paar timings zeigen deutlich dass sie doppelte MC links benützen. Den ansonnsten braucht du den delay nicht.
Andere defaults wie WRWRSC_Long aka eine CCDLWR Nutzung, werden nur gebraucht, sollte man den Zugriff zu beiden Subchannels (pro seite)
Nicht simultan ansprechen.
Da mir niemand genau beantworten kann ob AMD nun dual MC links benützt oder nur einen.
Welches layout genau gewählt wurde, kann ich dir auch nicht die exakten minimums sagen.
Aufgrund mehreren Problemen
tBURST ist auf der CPU Seite als 3nCK (AMD Only) erzwungen.
Es kann nur ein 133/100 synronization's Topic sein. Aber ich verstehe es nicht ganz.
Beide subchannels werden individual zu der CPU gezogen , in unserem Fall der APU und dort interleaved und scheduled.
Normalerweise sollte Bank bzw Rank scheduling auf dem DIMM selber passieren.
Bei beiden brechen Intel und AMD die eigentlichen Specifications von DDR5.
Das macht es weiterhin ein unklares Argumentation Thema. Mit mehreren richtigen "it depends" Antworten.
Sorry zu deiner Frage nun,
Der Grund weswegen es verwirrend ist, abseits des Logik Thema's
Ist dass der Hauptpost nicht von mir gewartet wird, und doch einiges an Zeit zwischen den Posts vergangen ist
WRWR_DD zu tWRRD matching, wurde benötigt, als AMD noch Schwierigkeiten mit dem RTL bzw IOL ~ in unserem Fall tPHYRDL & WRRD hatte.
War dieser Wert nicht exakt identisch, so hattest du PHYRDL missmatches und dank denen kaamen dann #0er in memtests.
"Dropped DQS thanks to missmatch in channel delay and so missmatch unstable delays = unstable clock and generally a mess'n'a half"
So in etwa 🤭
Es zeigt auch deutlich, dass _DD timings im Einsatz kommen, aber auch nur weil es ein RTL und Syncronizations Topic ist.
Obwohl ehmalige zb Anandtech Artikel "Subchannel" als "eine falsche Ausgabe der Realität" betiteln.
Leider gibt es einen großen Unterschied zwischen den design-specifications und der Realität die wir hier haben.
DDR5 is a mess Unsere fehlerhafte Umsetzung macht es nicht einfacher.
Ich wünschte der Start wäre anders und wir würden DDR5 korrekt benützen. Das heißt ebenso FGR an !!! mit korrektem clock halting
Mir fehlt die motivation die Biose für alle Boards zu patchen damit es endlich weitergeht . . . Etwas ausgebrannt immer nur ein one-man-army Rebell zu sein.
Jedenfalls:
Diese Werte sind korrekt.
Solange man RRDS über 8 hält.
Sollte man RRDS unter 8 laufen lassen, in dem Fall RRDS 4 (GDM trickst, RRDS4 ohne GDM braucht spezielle Vorraussetzungen)
Dann wären die minimums, 4-8-2-3 anstelle 8-16-4-6
Es gibt leider ein weiteres "it depends"
Und zwar ob wir nun den CCDLWR Spec nützen möchten oder nicht.
Das heißt welchen Wert wir für WRWRSC_L angeben.
Man könnte die CCDL Formel nützen und nur RRDL als CCDL bezeichnen bzw nehmen.
Dann wäre das effektive SC_L minimum, RRDL (also CCDL) - BC8 +1.
SC_L sind samechip (roundtrip) latency.
Was wir ausrechnen ist der CPU-Interface (HOST) delay, minus dem Mem-Interface delay + den ODTEnableDelay)
Sprich SC_Short wäre so oder so instant = 1
SC_Long wäre dann ODTEnableDly (pulled high). Der Reine offset zwischen beiden , aka zwischen read to read oder write to write commands.
Das sollte hoffentlich auch erklären weswegen WRWRSC_L tiefer kann.
Bzw hofffentlich erklären weswegen manche XOCer diesen als "its just not used" betiteln.
Nun Fehler stacken.
Es ist schon ein Hauptproblem dass man RAS zu tief setzt, aber nun ja.
A never ending discussion :')
Somit tut mir leid sollte ich sehr harsch zu solchen Leuten reagieren~~
SC, SD/DR, DD, SC_L ~ sind alles transition delays.
Sie sind keine ! fixen Timing delays
Nicht nur manche OCN nutzer gehen mir auf die nerven, sondern auch Boardpartner.
Ich muss jedes-mal Leuten nachrennen damit die Industrie weitergeht. Tut mir leid sollte ich jemanden mit meinem gestrigen Kommentar verletzt haben
Guten morgen allesamt
Beitrag automatisch zusammengeführt:
Ah,
Selbst wenn ich falsch liege und es nicht wissen kann ~ sprich AMD wirklich sich korrekt verhält und aus "panik?" FGR bzw Mixed-Mode nicht einschalten möchte;
Sollten die Werte doppelt so hoch sein, kann RAM sich von BL16 zu BL32 ändern.
Das gleicht die Latenz und zugriffszeit an, mit minimal langsamerer Peak Bandwidth ~ auf deutlich niedrigereren Spannungen.
@RedF
Eigentlich ist dein Ergebniss nicht soo schlecht, wenn ich mir mein Safedisk vs Veii Beispiel aus dem Post #3,124 ~ anschaue
Bei dir sind beide recht gut balanciert und werden durch die Architektur limitiert.
Bzw der Vergleich
// RFC und ODT sind absichtlich gleich gewählt.
Ich bin etwas langsamer im max-write Zugriff.
Sollte es sich auf BL32 benehmen, erklärt es den Grund. Denke allerdings dass es an WRRD liegt, da beide RDWR & WRRD sehr auf die BW gehen.
Brauche jedoch nur ein Bruchteil der Spannungen und somit wäre SI besser
Es ist kaum bis garkein Latenz Unterschied.
Im Copy welches eine Rolle spielt wäre ich sogar effizienter dran.
Aber AIDA gibt nur das Potential an und ist weit von der Realität
Die Realität testet man anders und ist je nach SKU etwas anders.
SiSoftware Sandra ist dein Freund bei dem Thema
Und Riftbreaker Demo, müsste ebenso dezent gut skallieren.
// Es würde die GPU Auslastung ändern (ins positive), wenn Zugriff zum L3$ und dann leakage zu Mem ~ effizienter wird.
Es heißt weiterhin nicht dass es "Sinnlos" wäre
Aber dass man nicht wirklich so tief gehen muss um die selbe bzw in manchen teilen +1% in anderen -1% Leistungsverlust hätte - auf 50-100mV weniger Spannung
Grund ~ die Architektur kann damit nichts anfangen, und nun ja ~ das MC Thema ist seit über einem Jahr noch nicht geklärt.
Die transition delays zwischen den Timings spielen eine wichtige Rolle. Auf welchem Startwert diese sind bzw wie tief sie wirklich gehen, ist ein komplett anderes ~noch unklares~ Thema.
Jedes Timing geht in paaren bzw dreier ~ (pre timing, timing, past timing infuence)
Niedriger heißt nicht gleich besser~~
Ich hoffe man versteht mich.
Vielen herzlichen Dank. Ich habe es noch nicht komplett verstanden, aber werde mich in die Thematik einarbeiten und schauen, was stabiler und konsistenter läuft.
Also 4-8-2-3 vs. 8-16-4-6 in Abhängigkeit von tRRDS. Das heißt wohl trial and error!
Danke für Deine Zeit auf jeden Fall. Das ist ja auch immer eine Menge Arbeit solche langen Posts zu schreiben. Ich bin von der Sache her eigentlich mehr Praktiker, aber die Theorie dahinter sollte man meiner Meinung nach zumindest wissen.
Use SiSoftware Sandra - Interthread latency test
Der Rest der "benchmarks" schaffen es kaum über einem IC zu gehen, geschweige den überhaupt die Buswidth limits zu erreichen.
Aida testet diese Buswidth limits, aber es ist eine Bruteforce methode. Weit weg on der Realität, jedoch ok um throttle oder ECC zu bemerken.
Höre nicht auf mich und vergleiche es mit einem guten Tool
Höre lieber auf das was AMD macht.
Fast alles hat einen Grund weswegen es sich so benimmt wie es sich benimmt.
Durch "Leistungstests" findet man allerdings diesen Grund nicht heraus. Nur dass es schneller sein kann, jedoch "wieso".
Natürlich sind niedrige timings in irgendwas schon schneller, wenn ECC noch nicht einsetzt. 🤭
Nun sollte hoffentlich alles klar sein
AMD nützt kein SD/DR/DD für RDWR bzw WRRD.
Und tRDWR bzw tWRRD sind andere Timings.
Ich meinte dort nur die _DD's bzw _SD's.
RDWR und WRRD sind komische AMD-HQ Timings.
Aber die Formel davon steht extra.
Hoffentlich verständlich beschrieben.
Theoretisch kann RRD(S) tiefer sein, mit höherem vom Board angelegtem CCDL
Aber die Regel im ersten ersten Post gilt weiterhin.
Es wird mathematisch das minimum CCDL ausgerechnet (dank user timings)
Weswegen es sehr wichtig ist SC_L's korrekt zu haben, selbst wenn man WRWRSC_L gleich RDRDSC_L stellen möchte (wobei der WTRS Exploit bricht und mehr tRTP & tWR braucht)
Wären SC_L's falsch bzw RRD_L's höher als die minimums.
Also RRDL höher als SC_L, dann wird SC_L hochgerechnet. EDIT ~ Example:
RRDL 8 ~ minimum CCDL 8
RDRDSCL 5 (minimum CCDL 12 ~ da 12-8+1 = 5 SCL)
= 12 liegt an, RRDL 8 ist eine Verschwendung
RRDL 15 (CCDL 15)
RDRDSCL 3 (CCDL 10)
= 15 liegt an, zwischen reads with noch ein tAL on 5 nCK eingesetzt ... im besten Fall. Im schlimmsten crasht es
Es haut immer den höchsten delay rein.Im gesammtbild, macht es wenig sinn commands zu queue'n , wenn CCDS und CCDL der Limiter sind.
// Aber natürlich bemerkt man sowas nicht, wenn man kaum mehr als 1024MB auslastet mit seinem Benchmark. 🤭
Sprich es macht wenig Sinn diese Timings niedrig zu halten, obwohl es "nur" der Bankgroup swap delay ist (RAS to RAS different/same bankgroup = RRD)
Im gesammtbild, geht mehr schief. Selbst wenn es "kleine" benchmarks, als schneller darstellen.
Abseits davon,
Bei hohem clock, musst du zurück auf den richtigen Werten, aka RRD minimums 8+
Und sollte ich mit RRDS, bzw CCDS falsch liegen und es 3 oder 4 sein [dank double MC] - passt es dennoch, da BL32 eine Sache ist.
Nun ja
Kann schon sein, dass das noch niedriger geht, aber ja, reicht mir erstmal. Spannungen sind auch akzeptabel für mich (VDD = 1,38 V; VDDIO = VDDQ = 1,3 V; VSoC = 1,225 V; restl. Spannungen auf auto).
tRAS habe ich die "optimale" Variante genommen, also tRCD + tRTP + 8 (Burst?)
Wenn ich Lust und Zeit habe, schaue ich mir diesen SiSoft Sandra Test mal an.
Das ist schön balanciert Bottleneck CPU Arch, nicht mem.
AMD kann seine instant writes wann-auch-immer ausführen (ReBAR spielt ebenso eine Rolle, viele AMD trickserein),
und du kannst manche timings nun tiefer setzten und solltest verbesserungen feststellen können.
Ich würde aber erstmal GDM weghauen. Nummer 1
Danach würde ich versuchen ob tWRRD auf 4 oder 5 eine Verbesserung bringt.
// nicht sicher ob 5 oder 4 hinkommen. AMDs Formel ist ... falsch ? , komisch definitiv. Sollte gleich WTR sein bzw +/- 1 dank PhyDly.
Und die WRWR's danach um 1 absenken.
Bzw SD's sind immer höher als DD's. Laut specs haben sie gleich zu sein, aber ja.
// ^ single side braucht keine SD's. Reine delay Verschwendung.
Danach wenn du damit fertig bist es auszuloten (bzw bei keinem sichtbaren Unterschied mit SiSoftware Sandra Inter-thread test gegentesten)
Das ist halt ... misst
Dann kann ProcDQ zum schwächeren Wert (größere ziffer) und VDDIO tiefer
Da du eine Delta zwischen VDDQ_MEM und VDD_MEM hast
Muss VDDIO (VDD2_CPU/MC) mindestens um die selbe Delta hinunter.
// ^ versteckte VDDQ_CPU synchronization Thematik ~ AMD macht es automatisch, bei Intel muss man selber ran.
Später wenn dir langweilig wird, kannst du gegentesten wie tief VDDQ_MEM bei dir sein kann.
Je tiefer, desto besser ist die Signal Integrity. 50mV gehen immer, ab 100mV wirds schwer und instabil (Tm5 reports bitte hier-her)
Es kann sein dass du dich mit den ODT's spielen musst.
Beitrag automatisch zusammengeführt:
Ah
RDWR kann runter bis zum Wert von 13.
Das minimum hängt von WPRE ab, und der Wert hängt vom Training ab bzw Nitro settings.
Er ist pro clock unterschiedlich
Aber es sollte dir helfen die echten minimums rauszufinden, nun wo die Timings sich nicht gegenseitig stören.
^ dafür muss GDM weg. GDM gaukelt dir Stabilität vor.
Nur nicht vergessen, alles geht in Paaren.
RDWR 14-15 müsste auf Dual sided rennen. Ich denke 14(+1 für stabilität, micron) wäre gut genug.
Bringt am meisten Bandwidth, aber es wird nicht "ein" benchmark sein, der auschlaggebend sein muss.
Alle müssen positiv skalieren, ansonsten macht man als Timing-Tuner irgendwo etwas falsch. (ein Timing stört das andere)
FCLK ist kein Timing oder Voltage Thema.
Es ist ein ODT/Impedance Thema.
// Du kannst es kaum bis garnicht mit VDDG und SOC lösen.
// Es hängt von der APU ab wie hoch max UCLK & FCLK sein kann. Nun FCLK hat mehr Variablen.
FCLK kann sich selbstständig korrigieren, da es loadbalanced ist.
On-Die ECC existiert in der CPU und an dem DIMMs. Genannt PPR (Post Package Repair);
Zu hoher FCLK hat eher eine negative Skallierung.
EDIT: Das selbe mit zu hohen (-) CO Werten.
Clock-gating Thema. Bleibt stabil, skaliert negativ und auto-korrigiert VID. (dcBTC ~ AVFS Thema)
Sehr-schwer zu überprüfen, da clock im 1ms Abstand fällt. AMDs (RSMU) API ist weitaus zu langsam.
Wenn ich GDM ausstelle und TM5 1usmus starte, dann wirft es innerhalb von SEKUNDEN Errors und crasht unmittelbar danach (Blackscreen - PC Neustart). Mir ist dabei aufgefallen, dass "tPHYWRL" von 16 auf 15 springt, wenn ich GDM ausschalte. Ist das die Ursache?
Mit GDM an läuft TM5 1usmus rockstable durch (STUNDEN). Hat das eventuell etwas mit (falsch gesetzten) Spannungen und/oder Widerständen zu tun?
tWRRD auf 4 läuft aber auf jeden Fall!
edit:
Ach ja, und "tPHYRDL" springt von 36 auf 35.
Wenn ich GDM ausstelle und TM5 1usmus starte, dann wirft es innerhalb von SEKUNDEN Errors und crasht unmittelbar danach (Blackscreen - PC Neustart). Mir ist dabei aufgefallen, dass "tPHYWRL" von 16 auf 15 springt, wenn ich GDM ausschalte. Ist das die Ursache?
PHYRDL springt tiefer. Bitte überprüfe ob es für beide Dimms identisch wäre.
Aber ja - wie gesagt, GDM gaukelt einem Stabilität vor
Bleiben wir mal bei
SD/DD als 8
Kannst du 2T nehmen, anstelle 1T ?
Wir werden sehr viel mit ODTs spielen müssen
Alleine RTT_NOM sieht mir komisch aus.
Naja eigentlich erwarte ich von ASRock nichts als perfektion.
AMD hat sie dieses Generation als Boardpartner-of-Trust ausgewählt.
Bitte versuche dir zu notieren welche errors du bei TM5 bekommst
Meine Ehemalige foundation auf dem Taichi Carrara
Bis auf die Ausnahme, dass 6400 C26-36, 1.65v braucht, und ich hier effizienter ran'ging.
Taichi hatte kein Renesas Unlock. Bis heute nicht.
FCLK ist kein Timing oder Voltage Thema.
Es ist ein ODT/Impedance Thema.
// Du kannst es kaum bis garnicht mit VDDG und SOC lösen.
// Es hängt von der APU ab wie hoch max UCLK & FCLK sein kann. Nun FCLK hat mehr Variablen.
FCLK kann sich selbstständig korrigieren, da es loadbalanced ist.
On-Die ECC existiert in der CPU und an dem DIMMs. Genannt PPR (Post Package Repair);
Zu hoher FCLK hat eher eine negative Skallierung.
EDIT: Das selbe mit zu hohen (-) CO Werten.
Clock-gating Thema. Bleibt stabil, skaliert negativ und auto-korrigiert VID. (dcBTC ~ AVFS Thema)
Sehr-schwer zu überprüfen, da clock im 1ms Abstand fällt. AMDs (RSMU) API ist weitaus zu langsam.
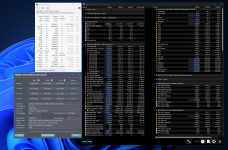
Die Timings sind ein aus einem OC Profil von meinem AUS B650 Board. Ich habe lediglich TREFI angepasst, GDM OFF und spannung ausgelotet. In diesen Profil sind alle Timings wie z.B. die SD&DD Werte vorgegeben. FCLK beobachte ich mal. vorher hatte ich es immer auf 2100 Mhz bei 1,1V laufen. CO z.B. lass ich bei -15, Gibt es kein Benchmark, der überprüfen lässt ob ECC, etc. da rein pfuscht?
Steht im fenster. 0er
Hard dropouts from CPU Side. Link dropouts.
Verringere mal die VDDQ delta. Mehr VDDQ oder versuche einfach mal das Taichi profil von mir zu übernehmen mit Auto RTT's.
ProcODT 43ohm müsste passen. 2100 FCLK ebenso. 2133 wäre gewagt vorerst.
Grüß euch. Ich bin momentan überhaupt nicht up to date was DDR5 Tuning angeht.
Kann mir einer mal ungefähr passende Settings für mein Riegel vorschlagen?
Bei mir ist noch vieles auf Auto.
REFI 66535 ~ 1.45 , etwa bis 44-46°
REFI 32767 ~ 1.5v , bis etwa 60-62°
Ansonnsten je nach airflow oder open-bench gehen 1.55 noch durch.
24/7 wäre ok bis 1.65v mit aktiver Luftkühlung.
VDDQ_MEM setzt die Hitze vorraus. Die Spannungs ist nicht alles
Temp welche du ausließt ist PMIC temp.
IC Temp wäre ungefähr +15° oben drauf.

")