
Hi,
obwohl ich mit Linux sonst wenig am Hut habe, betreibe ich seit vielen Jahren einen Linux-Server und setze ihn alle paar Jahre neu auf - erst unter Debian 3, dann unter Centos, dann wieder Debian 9. Er lässt sich nicht mehr updaten (broken irgendwas), gehört also neu aufgesetzt. Und jetzt ist mir eine HDD dabei über den Jordan zu gehen *) - der ideale Zeitpunkt um die Frage zu stellen: Server 'runderneuern' oder NAS?
Hardware derzeit:
Soll ich mir jetzt Gedanken über ein NAS machen? Könnte ich mir da auch ZoneMinder drauf installieren? Welche NAS sollte ich mir anschauen? Oder doch einfach 2 HDDs für 'Media' kaufen und den vorhandenen Server (nach Neuinstallation) weiter betreiben (da würd' ich mich so halbwegs auskennen)?
Thx für Input
Oktavus
obwohl ich mit Linux sonst wenig am Hut habe, betreibe ich seit vielen Jahren einen Linux-Server und setze ihn alle paar Jahre neu auf - erst unter Debian 3, dann unter Centos, dann wieder Debian 9. Er lässt sich nicht mehr updaten (broken irgendwas), gehört also neu aufgesetzt. Und jetzt ist mir eine HDD dabei über den Jordan zu gehen *) - der ideale Zeitpunkt um die Frage zu stellen: Server 'runderneuern' oder NAS?
Hardware derzeit:
- Büro: (teure WD-Server-) 2 TB HDD für SoHo + (billige) 2 TB HDD für die Spiegelung
- Media: 6 TB HDD für Video, Audio, Fotos + 6 TB HDD für die Spiegelung (erstere ist am abnippeln; der Platz wird bald knapp)
- eine alte AV-taugliche 500 GB HDD für administrative Dinge
- Samba-Shares (>SMB1) für Bürodaten,
- Samba-Shares (>SMB1) für die Linux-SAT-Receiver (zum Aufnehmen/Wiedergeben + Video-Audiosammlung)
- DLNA-Server fürn TV
- ZoneMinder für die Überwachungskameras
- Connection zur USV (d.h. wenn Strom weg, soll kontrolliert herunter gefahren werden)
Soll ich mir jetzt Gedanken über ein NAS machen? Könnte ich mir da auch ZoneMinder drauf installieren? Welche NAS sollte ich mir anschauen? Oder doch einfach 2 HDDs für 'Media' kaufen und den vorhandenen Server (nach Neuinstallation) weiter betreiben (da würd' ich mich so halbwegs auskennen)?
Thx für Input
Oktavus
Zuletzt bearbeitet:
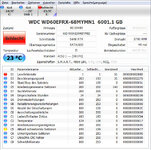
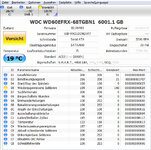
 (wo plötzlich die Drucker nicht mehr gehen oder SMB1 einfach abgeschaltet wird ^^
(wo plötzlich die Drucker nicht mehr gehen oder SMB1 einfach abgeschaltet wird ^^ . Nachteil: die 12 TB ext4 HDD läuft unter Windows mit (verschmerzbar), backuppen muss ich manuell. Vorteil: ich kann auch das Emailverzeichnis der Workstation sichern.
. Nachteil: die 12 TB ext4 HDD läuft unter Windows mit (verschmerzbar), backuppen muss ich manuell. Vorteil: ich kann auch das Emailverzeichnis der Workstation sichern.") . Installation weitgehend problemlos - allerdings bin ich über ein paar Steine gestolpert:
. Installation weitgehend problemlos - allerdings bin ich über ein paar Steine gestolpert: