Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
pumuckel
Urgestein
- Mitglied seit
- 13.12.2002
- Beiträge
- 8.206
- Ort
- Bayern
- Desktop System
- Workstation
- Laptop
- Acer Travemate AMD 4650 pro - 32GB 2TB und Samsung S6 Lite Tablet mit pen
- Details zu meinem Desktop
- Prozessor
- i5 12600 (non k - AVX 512 fähig)
- Mainboard
- AsRock z690 itx TB4 (nur weil super billig bekommen)
- Kühler
- Thermalright SI-100 full black (toller Kühler!)
- Speicher
- 2*16GB Corsair 6000 30-36-36-76 ( (nur weil super billig bekommen))
- Grafikprozessor
- PNY 4070 XLR8 - undervolting incomming aber auch so sehr sparsam und leise
- Display
- LG48 Zoll C27 Oled (<50W modded) + Dell G2724 Pivot (18W) + 2 Lenovo T22( (je 9W)
- SSD
- 4TB WD 850x (nur weil super billig bekommen)
- HDD
- dafür hat man Truenas Scale :)
- Opt. Laufwerk
- was ist ein optisches Laufwerk ? Datasette ?
- Soundkarte
- onboard mit Logitech Z906 per opt - oder interne des LG Oled je nach Game/Anwendung
- Gehäuse
- Cooler Master HAF Stacker 915R (davon hab ich 3 übereinander für 3 Systeme)
- Netzteil
- Seasonic Focus PX-750
- Keyboard
- Razer Tartarus 2 Gamepad, (rein nur um nur noch eine SW zu haben), Behelfstastatur
- Mouse
- Razer Basilisk V3 (rein nur um nur noch eine SW zu haben)
- Betriebssystem
- Leider auf dem Hauptsystem nun Win 11
- Webbrowser
- Firefox (full privacy modded) und Librewolf portable (für Käufe), dazu Vivaldi (für den Rest)
- Sonstiges
- in den Rear NVMe 4*4x slot kommt noch ein Riser Cable für ne 10GBe Karte irgendwann
wer lust hat etwas "zu spielen"
es gibt hier:
... grad günstige LSI 2008 Controller : Fujitsu Siemens SAS RAID Controller 6GBs PCI-E x8, S26361-D2607-A21-1-R791 | eBay
... auf meinen Preisvorschlag (unverschämt) hab ich ein Gegenangebot von 50€ /ST erhalten , sollte also Vorschläge = 50 annehmen (bei mehr evtl weniger)
das umflashen auf IT ist etwas tricky, aber es gibt ja Leute die gern tüfteln : https://marcan.st/2016/05/crossflashing-the-fujitsu-d2607 (hat auch die gepatchten files drin zum DL)
wenn jemand so böse ist und die zum resellen (umgeflashed) kauft wäre es lieb an mich zu denken (bräuchte atm einen ^^ , hab aber keine Zeit zum spielen)
2008 deshalb, weil sie funktionieren und etwas weniger verbrauchen als die 3008
es gibt hier:
... grad günstige LSI 2008 Controller : Fujitsu Siemens SAS RAID Controller 6GBs PCI-E x8, S26361-D2607-A21-1-R791 | eBay
... auf meinen Preisvorschlag (unverschämt) hab ich ein Gegenangebot von 50€ /ST erhalten , sollte also Vorschläge = 50 annehmen (bei mehr evtl weniger)
das umflashen auf IT ist etwas tricky, aber es gibt ja Leute die gern tüfteln : https://marcan.st/2016/05/crossflashing-the-fujitsu-d2607 (hat auch die gepatchten files drin zum DL)
wenn jemand so böse ist und die zum resellen (umgeflashed) kauft wäre es lieb an mich zu denken (bräuchte atm einen ^^ , hab aber keine Zeit zum spielen)
2008 deshalb, weil sie funktionieren und etwas weniger verbrauchen als die 3008
Zuletzt bearbeitet:
besterino
Legende
- Mitglied seit
- 31.05.2010
- Beiträge
- 7.980
- Desktop System
- Rechenknecht
- Laptop
- Lenovo Legion 5 (Intel, 4080, 32GB)
- Details zu meinem Desktop
- Prozessor
- AMD 9800X3D (-25, +200)
- Mainboard
- MSI MAG X870E Tomahawk Wifi
- Kühler
- Kryo Next AM5, 2xMora 420, Tube 150, 2x Apex VPP, Aquaero 6 Pro, DFS High Flow USB, Farbwerk360
- Speicher
- 96GB (2x48GB@6000,CL28)
- Grafikprozessor
- 5090 Palit Gamerock OC
- Display
- 55" OLED (Dell AW5520QF)
- SSD
- 1x2TB PCIe 5.0, 2x4TB NVME PCIe 4.0 (Raid0), Rest (~12TB NVME) über SMB Direct
- HDD
- Näh. Technik von gestern.
- Opt. Laufwerk
- Näh. Technik von gestern.
- Soundkarte
- Cambridge Audio DacMagic 200M
- Gehäuse
- Lian-Li DK-05F
- Netzteil
- Seasonic TX-1600 Noctua Edition
- Keyboard
- Keychron Q6 Pro, Maxkeyboard Custom Caps, Black Lotus / Dolphin Frankenswitch, Everest Pads
- Mouse
- Swiftpoint Z2
- Betriebssystem
- Windows 11 Pro for Workstations (SMB Direct - yeah baby)
- Sonstiges
- Mellanox ConnectX-4 (Dual 100Gbit Netzwerk + WaKü), Rode NT-USB, Nubert ampX uvm. ...
Gehört hier vielleicht nicht exakt hin, aber das ist hier ja quasi auch ein "Solarish Sammler" bzw. "napp-it Sammler" ... ")
@gea: magst Du vielleicht in Napp-it irgendwo (zum Beispiel unter "System --> HW and Localization"?) eine Funktion zum Setzen der richtigen Zeit einbauen? Vielleicht hab' ich es auch nur übersehen bzw. nicht gefunden ? Jedenfalls stimmte bei mir die Zeit trotz Auswahl der richtigen Zeitzone bei Installation von Solaris und richtiger Systemzeit im Bios nicht. Ist mir irgendwann erst später aufgefallen, als ich mich wunderte, warum Jobs nicht zur gewünschten Zeit liefen.
Insofern fänd' ich eine Anzeige der "Systemzeit" oder vielleicht wenigstens der Login-Zeit irgendwo im Kopf (z.B. ganz oben links neben/unter der Napp-it/Hostname/Version-Zeile, oder ganz oben rechts neben/unter "logout:admin/...") ganz praktisch, so dass man eine Chance hat, etwaige Abweichungen von der "eigenen Zeit" gut zu erkennen. Und wenn man dann irgendwo vielleicht noch einen ntp-Server setzen könnte...
Naja, wirklich nur eine Anregung und nice-to-have, geht ja zur Not auch über die Konsole. Hab jetzt den NTP-Dienst laufen und hole mir die Zeit bei de.pool.ntp.org. Jetzt zeigt ein "date" endlich die richtige Zeit.
@gea: magst Du vielleicht in Napp-it irgendwo (zum Beispiel unter "System --> HW and Localization"?) eine Funktion zum Setzen der richtigen Zeit einbauen? Vielleicht hab' ich es auch nur übersehen bzw. nicht gefunden ? Jedenfalls stimmte bei mir die Zeit trotz Auswahl der richtigen Zeitzone bei Installation von Solaris und richtiger Systemzeit im Bios nicht. Ist mir irgendwann erst später aufgefallen, als ich mich wunderte, warum Jobs nicht zur gewünschten Zeit liefen.
Insofern fänd' ich eine Anzeige der "Systemzeit" oder vielleicht wenigstens der Login-Zeit irgendwo im Kopf (z.B. ganz oben links neben/unter der Napp-it/Hostname/Version-Zeile, oder ganz oben rechts neben/unter "logout:admin/...") ganz praktisch, so dass man eine Chance hat, etwaige Abweichungen von der "eigenen Zeit" gut zu erkennen. Und wenn man dann irgendwo vielleicht noch einen ntp-Server setzen könnte...
Naja, wirklich nur eine Anregung und nice-to-have, geht ja zur Not auch über die Konsole. Hab jetzt den NTP-Dienst laufen und hole mir die Zeit bei de.pool.ntp.org. Jetzt zeigt ein "date" endlich die richtige Zeit.
fdiskc2000
Enthusiast
- Mitglied seit
- 30.05.2007
- Beiträge
- 2.232
Bei mir wird die Zeit oben rechts mit angezeigt. Das ist meine ich kein pro-Feature.
Aber das mit dem einstellen ist wirklich so ein Ding. Mein ml310e der nur ab und an läuft hat eine Abweichung von 7 Minuten. Keine Ahnung. Hatte bisher aber noch keine Möge dem auf den Grund zu gehen.
Gesendet von iPhone mit Tapatalk
Aber das mit dem einstellen ist wirklich so ein Ding. Mein ml310e der nur ab und an läuft hat eine Abweichung von 7 Minuten. Keine Ahnung. Hatte bisher aber noch keine Möge dem auf den Grund zu gehen.
Gesendet von iPhone mit Tapatalk
besterino
Legende
- Mitglied seit
- 31.05.2010
- Beiträge
- 7.980
- Desktop System
- Rechenknecht
- Laptop
- Lenovo Legion 5 (Intel, 4080, 32GB)
- Details zu meinem Desktop
- Prozessor
- AMD 9800X3D (-25, +200)
- Mainboard
- MSI MAG X870E Tomahawk Wifi
- Kühler
- Kryo Next AM5, 2xMora 420, Tube 150, 2x Apex VPP, Aquaero 6 Pro, DFS High Flow USB, Farbwerk360
- Speicher
- 96GB (2x48GB@6000,CL28)
- Grafikprozessor
- 5090 Palit Gamerock OC
- Display
- 55" OLED (Dell AW5520QF)
- SSD
- 1x2TB PCIe 5.0, 2x4TB NVME PCIe 4.0 (Raid0), Rest (~12TB NVME) über SMB Direct
- HDD
- Näh. Technik von gestern.
- Opt. Laufwerk
- Näh. Technik von gestern.
- Soundkarte
- Cambridge Audio DacMagic 200M
- Gehäuse
- Lian-Li DK-05F
- Netzteil
- Seasonic TX-1600 Noctua Edition
- Keyboard
- Keychron Q6 Pro, Maxkeyboard Custom Caps, Black Lotus / Dolphin Frankenswitch, Everest Pads
- Mouse
- Swiftpoint Z2
- Betriebssystem
- Windows 11 Pro for Workstations (SMB Direct - yeah baby)
- Sonstiges
- Mellanox ConnectX-4 (Dual 100Gbit Netzwerk + WaKü), Rode NT-USB, Nubert ampX uvm. ...
Ah, bin noch auf der 16.03 - muss wohl mal updaten.
EDIT: Updated auf 16.07pro. Zeit ist in der Tat da, links neben der Pro-Monitoranzeige. Aber nur, wenn der Monitor aktiv ist (also vermutlich nur in der Pro-Version). Jetzt wo ich die Zeitanzeige mal gefunden habe (danke für den Hinweis), es gibt sie übrigens auch schon in der 16.03...
Hinschauen hilft übrigens in der Tat häufiger: habe gerade festgestellt, dass die aktuelle Zeit quasi auch auf der "About"-Seite unter "Server Overview" bei "uptime" angezeigt wird... Hatte offenbar Tomaten auf den Augen.
Bleibt also nur die Anmerkung für einen Menüpunkt (und vielleicht nur noch ein sehr kleiner Verbesserungsvorschlag, die aktuelle Zeit vielleicht besser sichtbar zu machen für Blinde wie mich...).
- - - Updated - - -
Uh.... Nachtrag und Error-Report zur 16.07p: Nach update von 16.03 auf 16.07 (inkl. Reboot) bekomme ich bei den Menüs "User", "Disks", "Pools", "ZFS Filesystems" und "Snapshots" folgende Fehlermeldung (oder so ähnlich):
System: Solaris 11.3 auf x86:
Die Menüs "About", "Help", "Services", "System", "Comstar", "Jobs" und "Extensions" gehen. Habe aber jeweils nur die Hauptmenüs probiert.
Reproduzierbar auf zwei Systemen (vergleichbare Hardware-/OS-Basis).
EDIT: Updated auf 16.07pro. Zeit ist in der Tat da, links neben der Pro-Monitoranzeige. Aber nur, wenn der Monitor aktiv ist (also vermutlich nur in der Pro-Version). Jetzt wo ich die Zeitanzeige mal gefunden habe (danke für den Hinweis), es gibt sie übrigens auch schon in der 16.03...
Hinschauen hilft übrigens in der Tat häufiger: habe gerade festgestellt, dass die aktuelle Zeit quasi auch auf der "About"-Seite unter "Server Overview" bei "uptime" angezeigt wird... Hatte offenbar Tomaten auf den Augen.
Bleibt also nur die Anmerkung für einen Menüpunkt (und vielleicht nur noch ein sehr kleiner Verbesserungsvorschlag, die aktuelle Zeit vielleicht besser sichtbar zu machen für Blinde wie mich...).
- - - Updated - - -
Uh.... Nachtrag und Error-Report zur 16.07p: Nach update von 16.03 auf 16.07 (inkl. Reboot) bekomme ich bei den Menüs "User", "Disks", "Pools", "ZFS Filesystems" und "Snapshots" folgende Fehlermeldung (oder so ähnlich):
Code:
Can't load '/var/web-gui/data/napp-it/CGI/auto/IO/Tty/Tty.so' for module IO::Tty: ld.so.1: perl: fatal: relocation error: file /var/web-gui/data/napp-it/CGI/auto/IO/Tty/Tty.so: symbol PL_thr_key: referenced symbol not found at /usr/perl5/5.12/lib/i86pc-solaris-64int/DynaLoader.pm line 200. at /var/web-gui/data/napp-it/CGI/IO/Tty.pm line 30 Compilation failed in require at /var/web-gui/data/napp-it/CGI/IO/Pty.pm line 7. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/CGI/IO/Pty.pm line 7. Compilation failed in require at /var/web-gui/data/napp-it/CGI/Expect.pm line 22. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/CGI/Expect.pm line 22. Compilation failed in require at /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl line 2816. BEGIN failed--compilation aborted at /var/web-gui/data/napp-it/zfsos/_lib/illumos/zfslib.pl line 2816. Compilation failed in require at admin.pl line 437.System: Solaris 11.3 auf x86:
Code:
running on:SunOS [____] 5.11 11.3 i86pc i386 i86pc
Oracle Solaris 113 X86 Copyright c 1983 2015 Oracle andor its affiliates All rights reserved Assembled 06 October 2015Die Menüs "About", "Help", "Services", "System", "Comstar", "Jobs" und "Extensions" gehen. Habe aber jeweils nur die Hauptmenüs probiert.
Reproduzierbar auf zwei Systemen (vergleichbare Hardware-/OS-Basis).
Zuletzt bearbeitet:
Das Problem mit dem Expect.pm Modul unter Solaris 11.3 ist gefixt.
Bitte 16.07 oder 16.08 (bereite da gerade eine neue Free und Pro Edition vor) erneut laden
Zum Einstellen der Zeit:
Am einfachsten einen "other Job" erstellen.
Da ist "ntpdate pool.ntp.org" bereits als Beispiel vermerkt (Rückgabewert ignorieren)
Anzeige der Zeit und sonstiger Statusinfos: Menü About
neu u.A. in 16.08 siehe http://napp-it.org/downloads/changelog.html
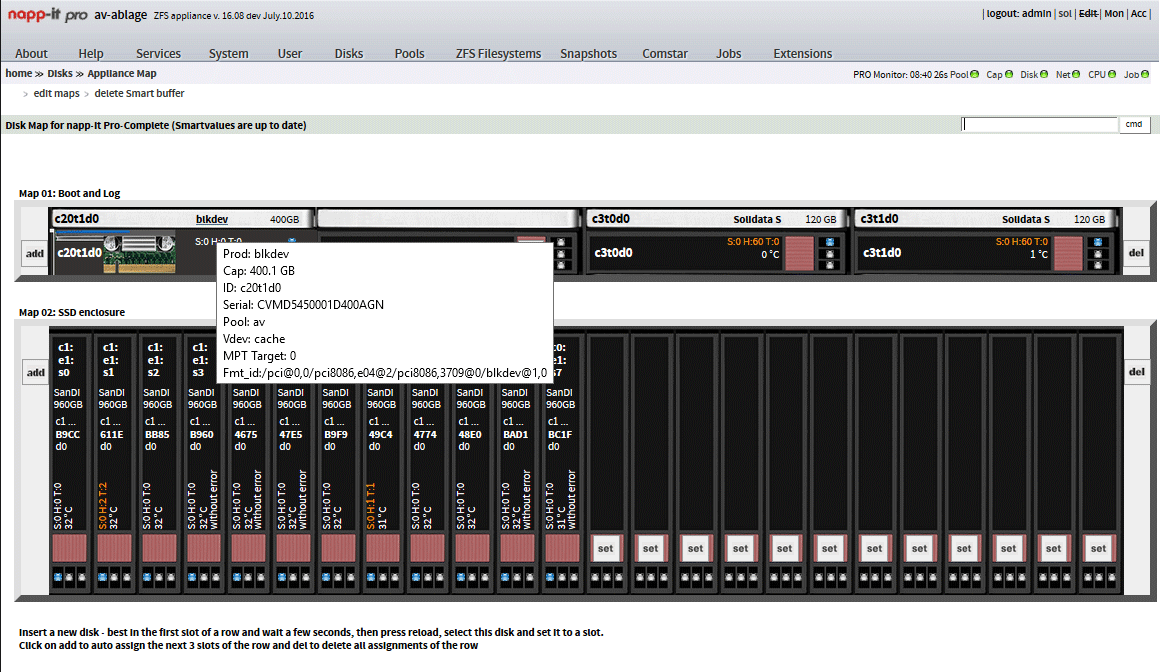
Appliance Maps
HA Cluster Plugin support (RSF-1 von http://www.high-availability.com/zfs-ha-plugin/)
Bitte 16.07 oder 16.08 (bereite da gerade eine neue Free und Pro Edition vor) erneut laden
Zum Einstellen der Zeit:
Am einfachsten einen "other Job" erstellen.
Da ist "ntpdate pool.ntp.org" bereits als Beispiel vermerkt (Rückgabewert ignorieren)
Anzeige der Zeit und sonstiger Statusinfos: Menü About
neu u.A. in 16.08 siehe http://napp-it.org/downloads/changelog.html
Appliance Maps
HA Cluster Plugin support (RSF-1 von http://www.high-availability.com/zfs-ha-plugin/)
Zuletzt bearbeitet:
fdiskc2000
Enthusiast
- Mitglied seit
- 30.05.2007
- Beiträge
- 2.232
Auf die 16.08 freue ich mich wegen der Maps auf jeden Fall schon. Sieht schick aus und ist nützlich.
Das Zeit-Problem: das mit dem Job habe ich gerade sofort ausprobiert. Ich habe trotzdem einen Versatz von -2 Minuten zur Atomuhr. Sehr merkwürdig. Natürlich auf dem Backupserver der nur ab und an am Tag läuft.
Der ML10v2 welcher aktuell nahezu 24/7 läuft ist auf die Sekunde genau - auch ohne extra Zeit-Job
- auch ohne extra Zeit-Job
OK, Kommando zurück. War nur etwas ungeduldig und klappt
Das Zeit-Problem: das mit dem Job habe ich gerade sofort ausprobiert. Ich habe trotzdem einen Versatz von -2 Minuten zur Atomuhr. Sehr merkwürdig. Natürlich auf dem Backupserver der nur ab und an am Tag läuft.
Der ML10v2 welcher aktuell nahezu 24/7 läuft ist auf die Sekunde genau
- auch ohne extra Zeit-JobOK, Kommando zurück. War nur etwas ungeduldig und klappt
Zuletzt bearbeitet:
layerbreak
Enthusiast
- Mitglied seit
- 30.12.2010
- Beiträge
- 590
Zum Thema Zeit einstellen:
Hier mach ich die Einstellungen, in /etc/inet/ntp.conf, wie von Joerg Moellenkamp auf seiner Webseite beschrieben plus den Kommentar von Brian Utterback.
Und Alles ist gut.
Hier mach ich die Einstellungen, in /etc/inet/ntp.conf, wie von Joerg Moellenkamp auf seiner Webseite beschrieben plus den Kommentar von Brian Utterback.
Code:
#####################################################
# http://www.c0t0d0s0.org/archives/7453-Configuring-an-NTP-client-in-Solaris-11.html #
#####################################################
server 0.de.pool.ntp.org iburst
server 1.de.pool.ntp.org iburst
server 2.de.pool.ntp.org iburst
server 3.de.pool.ntp.org iburst
#####################################################Und Alles ist gut.
Zuletzt bearbeitet:
besterino
Legende
- Mitglied seit
- 31.05.2010
- Beiträge
- 7.980
- Desktop System
- Rechenknecht
- Laptop
- Lenovo Legion 5 (Intel, 4080, 32GB)
- Details zu meinem Desktop
- Prozessor
- AMD 9800X3D (-25, +200)
- Mainboard
- MSI MAG X870E Tomahawk Wifi
- Kühler
- Kryo Next AM5, 2xMora 420, Tube 150, 2x Apex VPP, Aquaero 6 Pro, DFS High Flow USB, Farbwerk360
- Speicher
- 96GB (2x48GB@6000,CL28)
- Grafikprozessor
- 5090 Palit Gamerock OC
- Display
- 55" OLED (Dell AW5520QF)
- SSD
- 1x2TB PCIe 5.0, 2x4TB NVME PCIe 4.0 (Raid0), Rest (~12TB NVME) über SMB Direct
- HDD
- Näh. Technik von gestern.
- Opt. Laufwerk
- Näh. Technik von gestern.
- Soundkarte
- Cambridge Audio DacMagic 200M
- Gehäuse
- Lian-Li DK-05F
- Netzteil
- Seasonic TX-1600 Noctua Edition
- Keyboard
- Keychron Q6 Pro, Maxkeyboard Custom Caps, Black Lotus / Dolphin Frankenswitch, Everest Pads
- Mouse
- Swiftpoint Z2
- Betriebssystem
- Windows 11 Pro for Workstations (SMB Direct - yeah baby)
- Sonstiges
- Mellanox ConnectX-4 (Dual 100Gbit Netzwerk + WaKü), Rode NT-USB, Nubert ampX uvm. ...
Das Problem mit dem Expect.pm Modul unter Solaris 11.3 ist gefixt.
Bitte 16.07 oder 16.08 (bereite da gerade eine neue Free und Pro Edition vor) erneut laden
Kann ich bestätigen! Spitze und vielen Dank, Gea!
Zum Thema Zeit einstellen:
Hier mach ich die Einstellungen, in /etc/inet/ntp.conf, wie von Joerg Moellenkamp auf seiner Webseite beschrieben plus den Kommentar von Brian Utterback.
Ich hab's mit den Oracle Docs (how to setup an ntp client) hinbekommen. Die ntp.conf hat die restlichen Informationen ja drin. Auch alles gut.
Zuletzt bearbeitet:
Moin,
ich hab jetzt einen integrierten ESXi-OmniOS-Stick erstellt. D.h. von dem 32GB-Stick startet der ESXi 6.0U2, gleichzeitig ist auf dem Stick ein ESXi-Datastore, auf dem sich die OmniOS-VM befindet und automatisch startet.
Um den Stick ein wenig besser zu erhalten (Schreibzugriffe reduzieren), würde ich in OmniOS das SWAP- und das DUMP-Volume entfernen. Spricht da was dagegen? Ist das sinnvoll?
Atime steht für den rpool schon auf OFF...
ich hab jetzt einen integrierten ESXi-OmniOS-Stick erstellt. D.h. von dem 32GB-Stick startet der ESXi 6.0U2, gleichzeitig ist auf dem Stick ein ESXi-Datastore, auf dem sich die OmniOS-VM befindet und automatisch startet.
Um den Stick ein wenig besser zu erhalten (Schreibzugriffe reduzieren), würde ich in OmniOS das SWAP- und das DUMP-Volume entfernen. Spricht da was dagegen? Ist das sinnvoll?
Atime steht für den rpool schon auf OFF...
layerbreak
Enthusiast
- Mitglied seit
- 30.12.2010
- Beiträge
- 590
ich hab jetzt einen integrierten ESXi-OmniOS-Stick erstellt. D.h. von dem 32GB-Stick startet der ESXi 6.0U2, gleichzeitig ist auf dem Stick ein ESXi-Datastore, auf dem sich die OmniOS-VM befindet und automatisch startet.
Um den Stick ein wenig besser zu erhalten (Schreibzugriffe reduzieren), würde ich in OmniOS das SWAP- und das DUMP-Volume entfernen. Spricht da was dagegen? Ist das sinnvoll?
Atime steht für den rpool schon auf OFF...
Du hast auf dem 32GB Stick ESXi UND eine VM (OmniOS) installiert?
Ist der Stick mit 32GB nicht etwas zu klein?
Hallo zusammen,
würden diejenigen von euch, die es geschafft haben, erfolgreich einen Datastore auf einem per USB angebundenen Datenträger zu erstellen, mir kurz verraten, ob noch immer diese eher aufwendige Vorgehensweise (wie hier beschrieben) notwendig war, oder ob es bei ihnen tatsächlich wie weiter vorne angedeutet sehr simpel per GUI über den Web-Client erledigt werden konnte.
Des Weiteren würde mich interessieren, ob der USB-Datastore auch nach einem Host-Reboot sofort wieder zur Verfügung steht und ob es nach anschließendem Aktivieren des "usbarbitrator" wieder möglich war, USB-Devices an VMs durchzureichen.
All das klappt bei mir nämlich nicht (mit 6.0u2+).
Besten Dank
ces
würden diejenigen von euch, die es geschafft haben, erfolgreich einen Datastore auf einem per USB angebundenen Datenträger zu erstellen, mir kurz verraten, ob noch immer diese eher aufwendige Vorgehensweise (wie hier beschrieben) notwendig war, oder ob es bei ihnen tatsächlich wie weiter vorne angedeutet sehr simpel per GUI über den Web-Client erledigt werden konnte.
Des Weiteren würde mich interessieren, ob der USB-Datastore auch nach einem Host-Reboot sofort wieder zur Verfügung steht und ob es nach anschließendem Aktivieren des "usbarbitrator" wieder möglich war, USB-Devices an VMs durchzureichen.
All das klappt bei mir nämlich nicht (mit 6.0u2+).
Besten Dank
ces
Zuletzt bearbeitet:
Du hast auf dem 32GB Stick ESXi UND eine VM (OmniOS) installiert?
Ist der Stick mit 32GB nicht etwas zu klein?
Also bis jetzt nicht...
Mein Bootstick (SANDisk UltraFit 32GB) sieht in VMware so aus:
Code:
partedUtil getptbl /dev/disks/mpx.vmhba32\:C0\:T0\:L0
gpt
3738 255 63 60062500
1 64 8191 C12A7328F81F11D2BA4B00A0C93EC93B systemPartition 128
5 8224 520191 EBD0A0A2B9E5443387C068B6B72699C7 linuxNative 0
6 520224 1032191 EBD0A0A2B9E5443387C068B6B72699C7 linuxNative 0
7 1032224 1257471 9D27538040AD11DBBF97000C2911D1B8 vmkDiagnostic 0
8 1257504 1843199 EBD0A0A2B9E5443387C068B6B72699C7 linuxNative 0
9 1843200 7086079 9D27538040AD11DBBF97000C2911D1B8 vmkDiagnostic 0
10 7086080 59022809 AA31E02A400F11DB9590000C2911D1B8 vmfs 0Und OmniOS kommt mit 20GB ein paar Jahre aus... - solang man keinen anderen Kram darauf installiert. Um dennoch noch ein paar Byte zu sparen, hab ich die SWAP- und DUMP-Volumes noch eliminiert, die auch nochmal lt. Voreinstellung 2GB bzw. 4GB groß waren.
Aktuell hat mein rpool 3,6GB allocated und ca. 16GB sind noch frei...
Also ich hab den Menüpunkt auch noch nicht gefunden......ob noch immer diese eher aufwendige Vorgehensweise (wie hier beschrieben) notwendig war, oder ob es bei ihnen tatsächlich wie weiter vorne angedeutet sehr simpel per GUI über den Web-Client erledigt werden konnte.
Aber so schlimm ist es nicht per ssh. Allerdings muss man schon ein wenig mitdenken:
- wenn man seinen Stick beackern möchte, von dem man grad ESX gestartet hat, dann ist die Partitionstabelle nicht beschreibbar. Lösung: Stick kurz raus und wieder rein und der Stick erscheint nun als vmhba38, der nun beschreibbar ist. ESXi zum Schluß natürlich sauber neustarten nicht vergessen, damit er seinen Stick wieder sauber zur Verfügung hat...
- auf die Berechnung des Endsektors mittels veröffentlichter Kommandozeile würde ich mich nicht verlassen - lt. dieser hätte mein Stick eine Größe von 1.947.583,381080627 TB !
 Da ich grad die Reihenfolge der nächsten Einheiten nicht im Kopf hab, hab ich das Komma mal an dieser Stelle belassen...
Da ich grad die Reihenfolge der nächsten Einheiten nicht im Kopf hab, hab ich das Komma mal an dieser Stelle belassen... 
Aber zum Glück gibts ja noch Rechenschieber! (Für alle Jüngeren: das ist keine Harke)

Bei mir steht er sofort zu Verfügung und OmniOS startet wie im ESXi eingestellt automatisch.ob der USB-Datastore auch nach einem Host-Reboot sofort wieder zur Verfügung steht
Hab ich nicht probiert. Ich hab den Dienst komplett deaktiviert. Ich könnte mir aber vorstellen, dass das gehen könnte. Ich nehme an, der Blogbeitragsersteller ging davon aus, einen zweiten USB-Speicher neben dem ESXi-Boot-Device als Datastore zur Verfügung stellen zu wollen. Da kann das natürlich nicht gehen...ob es nach anschließendem Aktivieren des "usbarbitrator" wieder möglich war, USB-Devices an VMs durchzureichen
Zuletzt bearbeitet:
besterino
Legende
- Mitglied seit
- 31.05.2010
- Beiträge
- 7.980
- Desktop System
- Rechenknecht
- Laptop
- Lenovo Legion 5 (Intel, 4080, 32GB)
- Details zu meinem Desktop
- Prozessor
- AMD 9800X3D (-25, +200)
- Mainboard
- MSI MAG X870E Tomahawk Wifi
- Kühler
- Kryo Next AM5, 2xMora 420, Tube 150, 2x Apex VPP, Aquaero 6 Pro, DFS High Flow USB, Farbwerk360
- Speicher
- 96GB (2x48GB@6000,CL28)
- Grafikprozessor
- 5090 Palit Gamerock OC
- Display
- 55" OLED (Dell AW5520QF)
- SSD
- 1x2TB PCIe 5.0, 2x4TB NVME PCIe 4.0 (Raid0), Rest (~12TB NVME) über SMB Direct
- HDD
- Näh. Technik von gestern.
- Opt. Laufwerk
- Näh. Technik von gestern.
- Soundkarte
- Cambridge Audio DacMagic 200M
- Gehäuse
- Lian-Li DK-05F
- Netzteil
- Seasonic TX-1600 Noctua Edition
- Keyboard
- Keychron Q6 Pro, Maxkeyboard Custom Caps, Black Lotus / Dolphin Frankenswitch, Everest Pads
- Mouse
- Swiftpoint Z2
- Betriebssystem
- Windows 11 Pro for Workstations (SMB Direct - yeah baby)
- Sonstiges
- Mellanox ConnectX-4 (Dual 100Gbit Netzwerk + WaKü), Rode NT-USB, Nubert ampX uvm. ...
Hallo zusammen,
würden diejenigen von euch, die es geschafft haben, erfolgreich einen Datastore auf einem per USB angebundenen Datenträger zu erstellen, mir kurz verraten, ob noch immer diese eher aufwendige Vorgehensweise (wie hier beschrieben) notwendig war, oder ob es bei ihnen tatsächlich wie weiter vorne angedeutet sehr simpel per GUI über den Web-Client erledigt werden konnte.
Ging bei mir simpel per webgui.
Des Weiteren würde mich interessieren, ob der USB-Datastore auch nach einem Host-Reboot sofort wieder zur Verfügung steht
Ja, tut er. Kann konzeptionell keinen Unterschied zu einem separaten Datastore auf HDD oder SSD erkennen.
und ob es nach anschließendem Aktivieren des "usbarbitrator" wieder möglich war, USB-Devices an VMs durchzureichen.
All das klappt bei mir nämlich nicht (mit 6.0u2+).
Keinen blassen Schimmer.
Anhänge

Zuletzt bearbeitet:
...ob noch immer diese eher aufwendige Vorgehensweise (wie hier beschrieben) notwendig war, oder ob es bei ihnen tatsächlich wie weiter vorne angedeutet sehr simpel per GUI über den Web-Client erledigt werden konnte.
Ging bei mir simpel per webgui.
Ahhhh..., das muss einem doch gesagt werden... Das geht wohl nur per HOST-webgui. Im vCenter-webgui ist nix dergleichen zu finden...
- - - Updated - - -
Ich habe eine kurze Frage:
habe via HP Smart Arry ein Raid1 aus 2x3TB erstellt und reiche dieses über RAW an OMV weiter.
Wenn ich nun das Raid als ZFS Basic einstelle, betrifft mich diese 80% Kapazitäts-Regel dann auch?
Ja klar, der zfs-Pool muss sich ja selbst managen, d.h. er braucht Platz für sein copy-on-write. Ansonsten wirds halt irgendwann langsamer...
Allerdings ist dein Konstrukt grundsätzlich nicht ideal. Durch den HP-Smart-Array-Unterbau gehen dir ne Menge der zfs-Vorteile verloren.
Ja, das habe ich mittlerweile auch schon gelesen.Allerdings ist dein Konstrukt grundsätzlich nicht ideal. Durch den HP-Smart-Array-Unterbau gehen dir ne Menge der zfs-Vorteile verloren.
Aber mir persönlich ist Speicherplatz zu teuer um 20% freihalten zu müssen.
Wäre eine nette Spielerei gewesen, aber für mein Anwendungszweck, in dem sich die Daten nur seltens ändern, nicht notwendig
")
besterino
Legende
- Mitglied seit
- 31.05.2010
- Beiträge
- 7.980
- Desktop System
- Rechenknecht
- Laptop
- Lenovo Legion 5 (Intel, 4080, 32GB)
- Details zu meinem Desktop
- Prozessor
- AMD 9800X3D (-25, +200)
- Mainboard
- MSI MAG X870E Tomahawk Wifi
- Kühler
- Kryo Next AM5, 2xMora 420, Tube 150, 2x Apex VPP, Aquaero 6 Pro, DFS High Flow USB, Farbwerk360
- Speicher
- 96GB (2x48GB@6000,CL28)
- Grafikprozessor
- 5090 Palit Gamerock OC
- Display
- 55" OLED (Dell AW5520QF)
- SSD
- 1x2TB PCIe 5.0, 2x4TB NVME PCIe 4.0 (Raid0), Rest (~12TB NVME) über SMB Direct
- HDD
- Näh. Technik von gestern.
- Opt. Laufwerk
- Näh. Technik von gestern.
- Soundkarte
- Cambridge Audio DacMagic 200M
- Gehäuse
- Lian-Li DK-05F
- Netzteil
- Seasonic TX-1600 Noctua Edition
- Keyboard
- Keychron Q6 Pro, Maxkeyboard Custom Caps, Black Lotus / Dolphin Frankenswitch, Everest Pads
- Mouse
- Swiftpoint Z2
- Betriebssystem
- Windows 11 Pro for Workstations (SMB Direct - yeah baby)
- Sonstiges
- Mellanox ConnectX-4 (Dual 100Gbit Netzwerk + WaKü), Rode NT-USB, Nubert ampX uvm. ...
Tjo, das könntest Du mit der ziemlich guten und eingebauten lz4 Kompression wahrscheinlich zwar locker wieder rausholen, aber wer nicht will der hat schon (was anderes).
Es gibt bei ZFS keine 80% Grenze.
Wer mag kann den Pool auch vollaufen lassen.
Für alle Dateisysteme und für CopyOnWrite Dateisysteme etwas mehr gilt jedoch dass Performance abhängig vpm Füllgrad ist. Ein leerer Pool ist viel schneller als ein voller und besonders wenn es Richtung 90% und mehr geht werden die Arrays deutlich langsamer, bei Platten durch die zunehmende Fragmentierung und bei SSDs durch immer schwieriger werdende Garbage Collection.
Ein Ausweg ist Komprimierung. LZ4 kostet kaum Performance und hat exzellente Kompressraten.
Wer mag kann den Pool auch vollaufen lassen.
Für alle Dateisysteme und für CopyOnWrite Dateisysteme etwas mehr gilt jedoch dass Performance abhängig vpm Füllgrad ist. Ein leerer Pool ist viel schneller als ein voller und besonders wenn es Richtung 90% und mehr geht werden die Arrays deutlich langsamer, bei Platten durch die zunehmende Fragmentierung und bei SSDs durch immer schwieriger werdende Garbage Collection.
Ein Ausweg ist Komprimierung. LZ4 kostet kaum Performance und hat exzellente Kompressraten.
Ahh, ich verstehe, du legst den Datastore auf dem USB-Stick an, von dem du auch bootest, daher taucht der bei dir schon unter "Speicher" auf!Ging bei mir simpel per webgui.
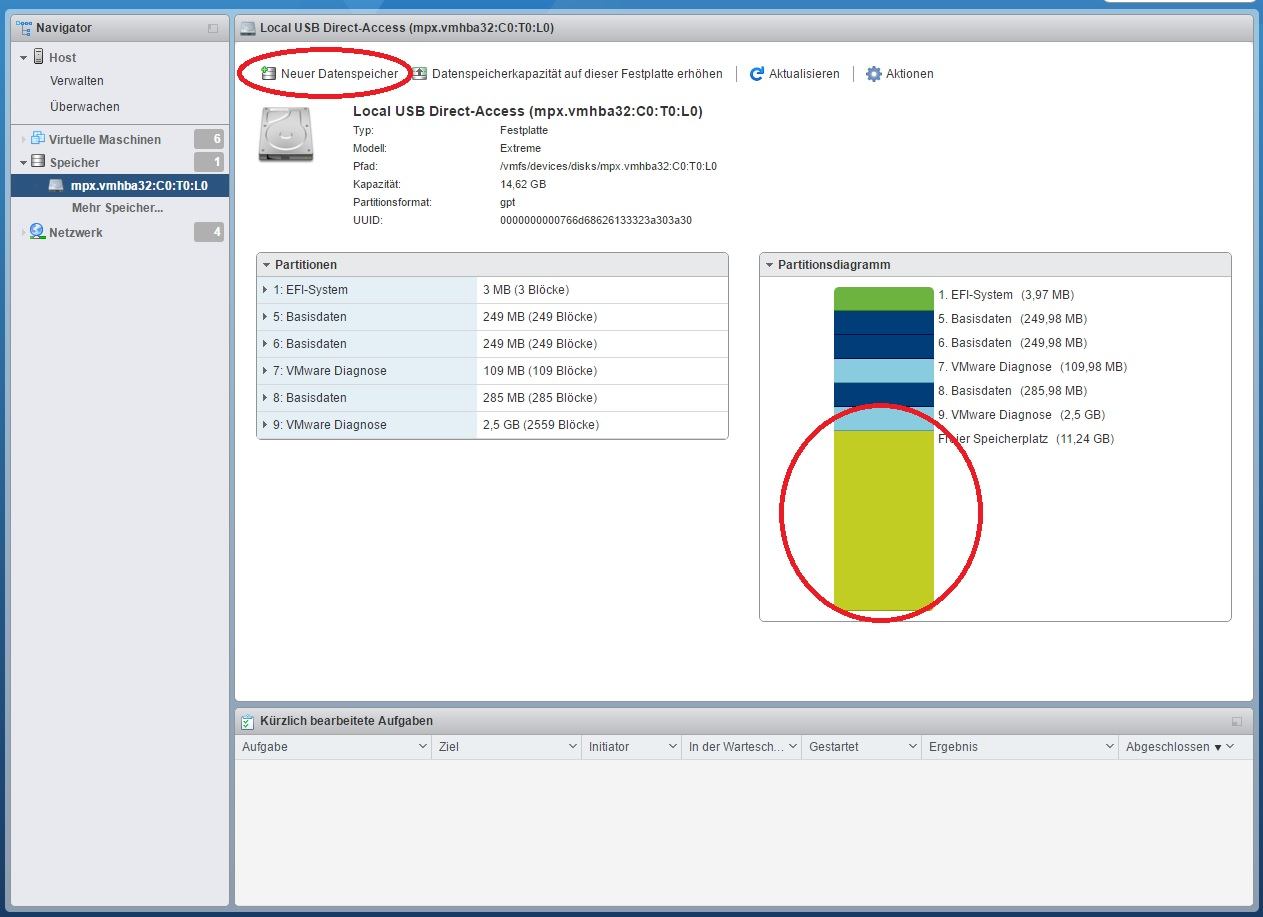
Vielleicht ist das der "Trick"!
Ein zusätzlich angestecktes USB-Device (mit dem ich es testen wollte, ohne direkt meinen derzeitigen produktiven Bootstick zu ersetzen) taucht dort nämlich nur bei deaktiviertem "usbarbitrator" auf und verschwindet auch wieder sobald der Dienst wieder aktiviert wird.
Das werd ich testen und mich zurückmelden.
Danke
ces
Ich bräuchte Hilfe bei der Einrichtung von Napp-IT One... Die Doku habe ich mir bereits durchgelesen, denke aber das ich ein paar Verständnisprobleme habe.
Ich habe bereits einen ESXi v6 Server aufgesetzt und das Napp-it One Template importiert. Dann habe ich zwei ZFS Datapools erstellt (1x für SSD Mirror, 1x für HDD Raid Z) und danach jeweils auf den Datapools ein ZFS Filesystem erstellt.
Die Konfiguration sieht so aus (habe alles so eingestellt wie beschrieben):

1. Was ist der Unterschied zw. dem ZFS Datapool und dem ZFS Filesystem? Muss ich den überhaupt noch ein ZFS Filesystem erstellen?
2. Kann ich jetzt bereits die 2 ZFS Pools an ESXi weitergeben oder müssen noch andere Einstellungen vorgenommen werden? Ich hab hier irgendwie ziemliche Verständnisprobleme bzgl. SMB, CIFS, NFS, ...
3. Der Server soll als Fileserver dienen. Sollen die Files über OmniOS freigegeben werden, oder muss ich noch ein anderes Betriebssystem zwischenschalten?
4. Habt ihr nen Link für eine ausführlichere Anleitung für Napp-it? Ich als Laie habe da echt Verständnisprobleme... Auch ne Anleitung für die Snapshots etc wäre interessant.
Vielen Dank")
Ich habe bereits einen ESXi v6 Server aufgesetzt und das Napp-it One Template importiert. Dann habe ich zwei ZFS Datapools erstellt (1x für SSD Mirror, 1x für HDD Raid Z) und danach jeweils auf den Datapools ein ZFS Filesystem erstellt.
Die Konfiguration sieht so aus (habe alles so eingestellt wie beschrieben):
1. Was ist der Unterschied zw. dem ZFS Datapool und dem ZFS Filesystem? Muss ich den überhaupt noch ein ZFS Filesystem erstellen?
2. Kann ich jetzt bereits die 2 ZFS Pools an ESXi weitergeben oder müssen noch andere Einstellungen vorgenommen werden? Ich hab hier irgendwie ziemliche Verständnisprobleme bzgl. SMB, CIFS, NFS, ...
3. Der Server soll als Fileserver dienen. Sollen die Files über OmniOS freigegeben werden, oder muss ich noch ein anderes Betriebssystem zwischenschalten?
4. Habt ihr nen Link für eine ausführlichere Anleitung für Napp-it? Ich als Laie habe da echt Verständnisprobleme... Auch ne Anleitung für die Snapshots etc wäre interessant.
Vielen Dank
besterino
Legende
- Mitglied seit
- 31.05.2010
- Beiträge
- 7.980
- Desktop System
- Rechenknecht
- Laptop
- Lenovo Legion 5 (Intel, 4080, 32GB)
- Details zu meinem Desktop
- Prozessor
- AMD 9800X3D (-25, +200)
- Mainboard
- MSI MAG X870E Tomahawk Wifi
- Kühler
- Kryo Next AM5, 2xMora 420, Tube 150, 2x Apex VPP, Aquaero 6 Pro, DFS High Flow USB, Farbwerk360
- Speicher
- 96GB (2x48GB@6000,CL28)
- Grafikprozessor
- 5090 Palit Gamerock OC
- Display
- 55" OLED (Dell AW5520QF)
- SSD
- 1x2TB PCIe 5.0, 2x4TB NVME PCIe 4.0 (Raid0), Rest (~12TB NVME) über SMB Direct
- HDD
- Näh. Technik von gestern.
- Opt. Laufwerk
- Näh. Technik von gestern.
- Soundkarte
- Cambridge Audio DacMagic 200M
- Gehäuse
- Lian-Li DK-05F
- Netzteil
- Seasonic TX-1600 Noctua Edition
- Keyboard
- Keychron Q6 Pro, Maxkeyboard Custom Caps, Black Lotus / Dolphin Frankenswitch, Everest Pads
- Mouse
- Swiftpoint Z2
- Betriebssystem
- Windows 11 Pro for Workstations (SMB Direct - yeah baby)
- Sonstiges
- Mellanox ConnectX-4 (Dual 100Gbit Netzwerk + WaKü), Rode NT-USB, Nubert ampX uvm. ...
Du hast bereits ZFS Filesysteme eingerichtet und die auch als SMB/CIFS Freigaben konfiguriert.
Zu 1.) Du kannst Dir den Unterschied zwischen Pool und Filesystem ein bisserl wie Partition und Volume in der Windows-Welt vorstellen, nur dass du den Pool eben über verschiedne Devices anlegen kannst. Nur mit dem Pool kannst Du noch nichts anfangen, du musst darauf eben erst Filesysteme bauen (in Windows würdest du ein Volume anlegen und z.B. mit NTFS formatieren). Der Vergleich hinkt etwas, aber vielleicht hilft das beim Grundverständnis.
Zu 2.) Wenn du an ESXi eine Freigabe für VMs "zurückgeben" willst, musst du das als NFS-Freigabe machen, SMB/CIFS spricht ESXi nicht. Dazu gibt es einen eigenen Reiter in NAPP-IT in der Übersicht, die du da gepostet hast. Du hast bisher nur SMB-Freigaben. Ich würde normale Freigaben für die Windows-Welt und die für ESXi logisch trennen und unterschiedliche Filesysteme dafür anlegen.
Zu 3.) Freigaben für Windows machst du wie du sie schon hast, am einfachsten geht das, wenn du den Gast-Zugriff erlaubst (dann kann jeder auf den Freigaben lesen und schreiben).
Zu 4.) Doku von Nappit und das Forum hier, mehr brauchst du nicht.
Zu 1.) Du kannst Dir den Unterschied zwischen Pool und Filesystem ein bisserl wie Partition und Volume in der Windows-Welt vorstellen, nur dass du den Pool eben über verschiedne Devices anlegen kannst. Nur mit dem Pool kannst Du noch nichts anfangen, du musst darauf eben erst Filesysteme bauen (in Windows würdest du ein Volume anlegen und z.B. mit NTFS formatieren). Der Vergleich hinkt etwas, aber vielleicht hilft das beim Grundverständnis.
Zu 2.) Wenn du an ESXi eine Freigabe für VMs "zurückgeben" willst, musst du das als NFS-Freigabe machen, SMB/CIFS spricht ESXi nicht. Dazu gibt es einen eigenen Reiter in NAPP-IT in der Übersicht, die du da gepostet hast. Du hast bisher nur SMB-Freigaben. Ich würde normale Freigaben für die Windows-Welt und die für ESXi logisch trennen und unterschiedliche Filesysteme dafür anlegen.
Zu 3.) Freigaben für Windows machst du wie du sie schon hast, am einfachsten geht das, wenn du den Gast-Zugriff erlaubst (dann kann jeder auf den Freigaben lesen und schreiben).
Zu 4.) Doku von Nappit und das Forum hier, mehr brauchst du nicht.
als Ergänzung
1.
Ein ZFS Pool ist auch ein ZFS Dateisystem.
Man könnte also durchaus einen Pool anlegen und diesen per NFS oder SMB/CIFS freigeben.
Das ist aber ein schlechter Plan. Wenn man mal weitere Dateisysteme möchte (als eigenes Share oder mit eigenen ZFS Eigenschaften, weil man das separat replizieren oder snapshotten möchte oder warum auch immer) und dann ein Dateisystem auf dem Pool anlegt, so erbt das alle Pool Eigenschaften. Das ist in dem Fall eher schlecht. Zudem gibt es ZFS Eigenschaften die nur auf den Pool wirken und solche die für Dateisysteme gelten.
besser: Den Pool als Container für Dateisystem sehen. Hier legt man nur Voreinstellungen fest.
2
Man muss lediglich ein Dateisystem anlegen, das per NFS freigebe n(NFS=on im Menü Dateisysteme) um es in ESXi als Datastore für VMs zu mounten. Ich würde es zusätzlich per SMB/CIFS (SMB=on im Menü Dateisysteme) freigeben um von Windows darauf zugreifen zu können (backup/copy/clone/previous version)
3.
Einfach ein Dateisysterm per SMB/CIFS freigeben (SMB=on im Menü Dateisysteme) .
Entweder guest aktivieren oder user + passwort anlegen
4.
Die napp-it doku sollte für den Einstieg reichen.
Umfangreiche Manuals (Solaris ist immerhin ein OS für die richtig großen Datacenter Sachen),
siehe (Download Solaris Express 11 manuals): napp-it // webbased ZFS NAS/SAN appliance for OmniOS, OpenIndiana, Solaris and Linux : Manual
1.
Ein ZFS Pool ist auch ein ZFS Dateisystem.
Man könnte also durchaus einen Pool anlegen und diesen per NFS oder SMB/CIFS freigeben.
Das ist aber ein schlechter Plan. Wenn man mal weitere Dateisysteme möchte (als eigenes Share oder mit eigenen ZFS Eigenschaften, weil man das separat replizieren oder snapshotten möchte oder warum auch immer) und dann ein Dateisystem auf dem Pool anlegt, so erbt das alle Pool Eigenschaften. Das ist in dem Fall eher schlecht. Zudem gibt es ZFS Eigenschaften die nur auf den Pool wirken und solche die für Dateisysteme gelten.
besser: Den Pool als Container für Dateisystem sehen. Hier legt man nur Voreinstellungen fest.
2
Man muss lediglich ein Dateisystem anlegen, das per NFS freigebe n(NFS=on im Menü Dateisysteme) um es in ESXi als Datastore für VMs zu mounten. Ich würde es zusätzlich per SMB/CIFS (SMB=on im Menü Dateisysteme) freigeben um von Windows darauf zugreifen zu können (backup/copy/clone/previous version)
3.
Einfach ein Dateisysterm per SMB/CIFS freigeben (SMB=on im Menü Dateisysteme) .
Entweder guest aktivieren oder user + passwort anlegen
4.
Die napp-it doku sollte für den Einstieg reichen.
Umfangreiche Manuals (Solaris ist immerhin ein OS für die richtig großen Datacenter Sachen),
siehe (Download Solaris Express 11 manuals): napp-it // webbased ZFS NAS/SAN appliance for OmniOS, OpenIndiana, Solaris and Linux : Manual
Zuletzt bearbeitet:
automatenraum
Enthusiast
- Mitglied seit
- 15.02.2013
- Beiträge
- 179
@gea:
Thema: Fehlende Disks bei der Zuordnung in den Appliance Maps, das ist und 16.09dev immer noch so. Hattest du da schonmal geschaut?
UPDATE: Hab gerade gesehen:
Es gibt aber nur eine Map, alte Maps wurden gelöscht und danach eine neue angelegt, die aktuell leer ist, sprich noch keine Platten zugeordnet sind.
Thema: Fehlende Disks bei der Zuordnung in den Appliance Maps, das ist und 16.09dev immer noch so. Hattest du da schonmal geschaut?
Ja da sind alle da:
Code:all_disks_unassigned -> 'c2t0d0 →c3t50014EE0AE2D7B0Dd0 →c3t50014EE2B40FD35Fd0 →c3t50014EE058D7E1C1d0 →c3t50014EE058D7EAF4d0 →c3t50014EE058D29090d0 →c3t50014EE00382AB3Fd0'Code:all_dsk -> 'c2t0d0 →c3t50014EE0AE2D7B0Dd0 →c3t50014EE0AE282758d0 →c3t50014EE2B40FD35Fd0 →c3t50014EE058D7E1C1d0 →c3t50014EE058D7EAF4d0 →c3t50014EE058D29090d0 →c3t50014EE00382AB3Fd0 →c3t50014EE20959D788d0'
- - - Updated - - -
Kann man das Kommentar Info/Feld auch direkt in der Map anzeigen lassen, oder muss man immer auf den Slot klicken?
UPDATE: Hab gerade gesehen:
Code:
all_disks_ok_in_slots -> 'c3t50014EE0AE282758d0 →c3t50014EE20959D788d0'Es gibt aber nur eine Map, alte Maps wurden gelöscht und danach eine neue angelegt, die aktuell leer ist, sprich noch keine Platten zugeordnet sind.
Zuletzt bearbeitet:
sashXP
Enthusiast
Hilfe! Scrub löst Event 129 aus
Hallo zusammen,
ich benötige Eure Hilfe! Nachdem unser Storageserver, einige Zeit lang nun schon im Betrieb ist und wir im Prinzip auch soweit zufrieden sind, stellt sich ein - für uns - sehr kritisches Problem ein! :-(
Der Storageserver stellt Daten per iSCSI bereit (per COMSTAR, Napp-It konfiguriert) - wenn nun ein Scrub durchläuft (siehe Laufzeit weiter unten) schmeißen die Hyper-V Hosts reihenweise die Festplatten - also die "Geräte" des iSCSI Devices raus. Das ganze tritt auf mit entsprechenden Events in der Ereignisanzeige auf beiden Servern:
Die Beschreibung für die Ereignis-ID "129" aus der Quelle "iScsiPrt" wurde nicht gefunden. Entweder ist die Komponente, die dieses Ereignis auslöst, nicht auf dem lokalen Computer installiert, oder die Installation ist beschädigt. Sie können die Komponente auf dem lokalen Computer installieren oder reparieren.
Falls das Ereignis auf einem anderen Computer aufgetreten ist, mussten die Anzeigeinformationen mit dem Ereignis gespeichert werden.
Die folgenden Informationen wurden mit dem Ereignis gespeichert:
\Device\RaidPort1
Die Meldungressource ist vorhanden, aber die Meldung wurde nicht in der Zeichenfolge-/Meldungstabelle gefunden
Dazu habe ich dies gefunden:
https://blogs.msdn.microsoft.com/nt...anding-storage-timeouts-and-event-129-errors/
Was mich aber bisher nicht wirklich weiter bringt. Warum füghrt der Scrub zum Time-Out? Habt ihr auch solche oder ähnliche Probleme? Was kann ich machen? Aktuell läuft alles stabil, ich muss aber doch regelmäßig einen Scrub fahren?
Eckdaten des Storage-Servers:
Es ist ein OmniOS v11 r151018 installiert/eingerichtet zur Konfiguration wurde Napp-it verwendet. Angebunden ist das Storage per 10GBit (SFP+)
ein zpool status liefert:
Zur Info noch hinsichtlich der Konfiguration:
CPU 2x E5-2630 v4
RAM 128GB
"fast" Storage: 5x SAMSUNG MZ7KM1T9 - 1,92TB SATA - Raid-Z2
"slow" Storage 5x HUH728080AL5200 - 8TB SAS - Raid-Z2 mit Cache und Log-Device (s.o.)
Hallo zusammen,
ich benötige Eure Hilfe! Nachdem unser Storageserver, einige Zeit lang nun schon im Betrieb ist und wir im Prinzip auch soweit zufrieden sind, stellt sich ein - für uns - sehr kritisches Problem ein! :-(
Der Storageserver stellt Daten per iSCSI bereit (per COMSTAR, Napp-It konfiguriert) - wenn nun ein Scrub durchläuft (siehe Laufzeit weiter unten) schmeißen die Hyper-V Hosts reihenweise die Festplatten - also die "Geräte" des iSCSI Devices raus. Das ganze tritt auf mit entsprechenden Events in der Ereignisanzeige auf beiden Servern:
Die Beschreibung für die Ereignis-ID "129" aus der Quelle "iScsiPrt" wurde nicht gefunden. Entweder ist die Komponente, die dieses Ereignis auslöst, nicht auf dem lokalen Computer installiert, oder die Installation ist beschädigt. Sie können die Komponente auf dem lokalen Computer installieren oder reparieren.
Falls das Ereignis auf einem anderen Computer aufgetreten ist, mussten die Anzeigeinformationen mit dem Ereignis gespeichert werden.
Die folgenden Informationen wurden mit dem Ereignis gespeichert:
\Device\RaidPort1
Die Meldungressource ist vorhanden, aber die Meldung wurde nicht in der Zeichenfolge-/Meldungstabelle gefunden
Dazu habe ich dies gefunden:
https://blogs.msdn.microsoft.com/nt...anding-storage-timeouts-and-event-129-errors/
Was mich aber bisher nicht wirklich weiter bringt. Warum füghrt der Scrub zum Time-Out? Habt ihr auch solche oder ähnliche Probleme? Was kann ich machen? Aktuell läuft alles stabil, ich muss aber doch regelmäßig einen Scrub fahren?
Eckdaten des Storage-Servers:
Es ist ein OmniOS v11 r151018 installiert/eingerichtet zur Konfiguration wurde Napp-it verwendet. Angebunden ist das Storage per 10GBit (SFP+)
ein zpool status liefert:
Code:
pool: rpool
state: ONLINE
scan: scrub repaired 0 in 0h3m with 0 errors on Mon Aug 1 00:48:18 2016
config:
NAME STATE READ WRITE CKSUM CAP Product /napp-it IOstat mess
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c6t0d0s0 ONLINE 0 0 0 120 GB SAMSUNG MZ7LM120 S:0 H:0 T:0
c6t1d0s0 ONLINE 0 0 0 120 GB SAMSUNG MZ7LM120 S:0 H:0 T:0
errors: No known data errors
pool: tank_hdd_sas
state: ONLINE
scan: scrub repaired 0 in 20h11m with 0 errors on Sat Aug 6 23:11:53 2016
config:
NAME STATE READ WRITE CKSUM CAP Product /napp-it IOstat mess
tank_hdd_sas ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
c2t5000CCA23B1B8FFDd0 ONLINE 0 0 0 8 TB HUH728080AL5200 S:0 H:2 T:0
c2t5000CCA23B3689D1d0 ONLINE 0 0 0 8 TB HUH728080AL5200 S:0 H:2 T:0
c2t5000CCA23B369009d0 ONLINE 0 0 0 8 TB HUH728080AL5200 S:0 H:2 T:0
c2t5000CCA23B52DE89d0 ONLINE 0 0 0 8 TB HUH728080AL5200 S:0 H:2 T:0
c2t5000CCA23B5305CDd0 ONLINE 0 0 0 8 TB HUH728080AL5200 S:0 H:2 T:0
logs
mirror-1 ONLINE 0 0 0
c4t1d0p1 ONLINE 0 0 0 12 GB S:0 H:0 T:0
c7t1d0p1 ONLINE 0 0 0 12 GB S:0 H:0 T:0
cache
c4t1d0p2 ONLINE 0 0 0 124 GB S:0 H:0 T:0
c7t1d0p2 ONLINE 0 0 0 124 GB S:0 H:0 T:0
errors: No known data errors
pool: tank_ssdonly_sata
state: ONLINE
scan: scrub canceled on Sun Jul 24 01:24:30 2016
config:
NAME STATE READ WRITE CKSUM CAP Product /napp-it IOstat mess
tank_ssdonly_sata ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
c1t5002538C00092621d0 ONLINE 0 0 0 1.9 TB SAMSUNG MZ7KM1T9 S:0 H:0 T:0
c1t5002538C0009262Bd0 ONLINE 0 0 0 1.9 TB SAMSUNG MZ7KM1T9 S:0 H:0 T:0
c1t5002538C0009262Dd0 ONLINE 0 0 0 1.9 TB SAMSUNG MZ7KM1T9 S:0 H:0 T:0
c1t5002538C402C5FECd0 ONLINE 0 0 0 1.9 TB SAMSUNG MZ7KM1T9 S:0 H:0 T:0
c1t5002538C402C5FEDd0 ONLINE 0 0 0 1.9 TB SAMSUNG MZ7KM1T9 S:0 H:0 T:0
errors: No known data errorsZur Info noch hinsichtlich der Konfiguration:
CPU 2x E5-2630 v4
RAM 128GB
"fast" Storage: 5x SAMSUNG MZ7KM1T9 - 1,92TB SATA - Raid-Z2
"slow" Storage 5x HUH728080AL5200 - 8TB SAS - Raid-Z2 mit Cache und Log-Device (s.o.)
Ähnliche Themen
- Antworten
- 5
- Aufrufe
- 1K
- Antworten
- 17
- Aufrufe
- 1K