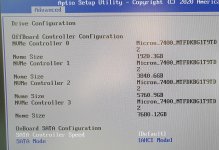
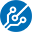
Kommt darauf an.
ZFS (bis auf Draid) arbeitet mit dynamischen Recsizes. Vereinfacht gesagt passiert folgendes:
Bei 128k default Recsize.
Schreibt man 60k Daten, so wird ein kleinerer 64k Datenblock geschrieben, "Verschnitt" 4k
Worst Case
Schreibt man 128,01k Daten, so werden 2 Datenblöcke je 128k geschrieben, max Verschnitt praktisch 128k
Mit 1M recsize
und kleinen Datenblöcken, werden dynamisch kleinere Datenblöcke 2 Hoch n also 4k, 8k, 16k, 32k, .. genutzt.
4k ist Minimum (physical Blocksize der Platte), ZFS Compress, Prüfsummen, Verschlüssellung ist extrem ineffektiv bei so kleinen Blöcken.
Worst Case
Schreibt man 1,01M Daten, so werden 2 Datenblöcke je 1M geschrieben, max Verschnitt praktisch 1M
Hat man im Wesentlichen große Daten, kommt der worst case selten vor. Ist das ein "Office filer" ist das nicht ganz so optimal.
Hinzu kommt dass man auch bei größeren Dateien bei denen man einen Teil lesen möchte, immer 1M einlesen muss, auch wenn man nur ein paar Bytes Text oder einen einzelnen Datenbankeintrag benötigt.
Bei einem Video Filer ist also 1M eher günstiger, bei einem Filer mit vielen unterschiedlichen Dateien ist 128k Default eher besser, bei einer VM oder Datenbank eher 32-64k
ZFS (bis auf Draid) arbeitet mit dynamischen Recsizes. Vereinfacht gesagt passiert folgendes:
Bei 128k default Recsize.
Schreibt man 60k Daten, so wird ein kleinerer 64k Datenblock geschrieben, "Verschnitt" 4k
Worst Case
Schreibt man 128,01k Daten, so werden 2 Datenblöcke je 128k geschrieben, max Verschnitt praktisch 128k
Mit 1M recsize
und kleinen Datenblöcken, werden dynamisch kleinere Datenblöcke 2 Hoch n also 4k, 8k, 16k, 32k, .. genutzt.
4k ist Minimum (physical Blocksize der Platte), ZFS Compress, Prüfsummen, Verschlüssellung ist extrem ineffektiv bei so kleinen Blöcken.
Worst Case
Schreibt man 1,01M Daten, so werden 2 Datenblöcke je 1M geschrieben, max Verschnitt praktisch 1M
Hat man im Wesentlichen große Daten, kommt der worst case selten vor. Ist das ein "Office filer" ist das nicht ganz so optimal.
Hinzu kommt dass man auch bei größeren Dateien bei denen man einen Teil lesen möchte, immer 1M einlesen muss, auch wenn man nur ein paar Bytes Text oder einen einzelnen Datenbankeintrag benötigt.
Bei einem Video Filer ist also 1M eher günstiger, bei einem Filer mit vielen unterschiedlichen Dateien ist 128k Default eher besser, bei einer VM oder Datenbank eher 32-64k
Zuletzt bearbeitet: