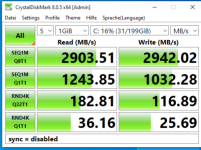
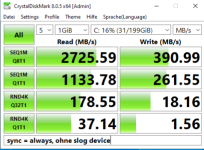
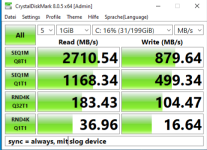
ZFS Pools bestehen aus vdevs, vdevs aus Platten.
In napp-it cs unter Windows ermittle ich die Platten in der Powershell mit
Get-PhysicalDisk | Select DeviceID,UniqueId,Manufacturer,Model,CanPool,OperationalStatus,HealthStatus,Serialnumber,size
Platten heißen z.B. physicaldisk1 (1 ist die deviceID aus dem powershell Listing)
btw
There is a new Open-ZFS 2.2 rc.13 for Windows
Jorgen Lundman: " I threw in some code that looks up ashift to use instead of 512. If you can, check out OpenZFSOnWindows-debug-2.2.99-13-gfddfb6aeb5.exe. I did the most obvious places, but there are quite a few ways to query that.
*** Please update, the trim bug might be corrupting pools! ***
Now trim is disabled by default, to check it works (on test pools right?) change
HLM/System/ControlSet001/Services/OpenZFS
windows_enable_trim to 1. "
Care: ashift is not a pool but a vdev property. Different ashift in a pool is bad but can happen if you add vdevs without forcing ashift manually.

 github.com
github.com
In napp-it cs unter Windows ermittle ich die Platten in der Powershell mit
Get-PhysicalDisk | Select DeviceID,UniqueId,Manufacturer,Model,CanPool,OperationalStatus,HealthStatus,Serialnumber,size
Platten heißen z.B. physicaldisk1 (1 ist die deviceID aus dem powershell Listing)
btw
There is a new Open-ZFS 2.2 rc.13 for Windows
Jorgen Lundman: " I threw in some code that looks up ashift to use instead of 512. If you can, check out OpenZFSOnWindows-debug-2.2.99-13-gfddfb6aeb5.exe. I did the most obvious places, but there are quite a few ways to query that.
*** Please update, the trim bug might be corrupting pools! ***
Now trim is disabled by default, to check it works (on test pools right?) change
HLM/System/ControlSet001/Services/OpenZFS
windows_enable_trim to 1. "
Care: ashift is not a pool but a vdev property. Different ashift in a pool is bad but can happen if you add vdevs without forcing ashift manually.
Releases · openzfsonwindows/openzfs
OpenZFS on Linux and FreeBSD. Contribute to openzfsonwindows/openzfs development by creating an account on GitHub.
github.com



")