
Werbung
In Kooperation mit NVIDIA
GDDR5, GDDR5X, GDDR6, HBM
Neben der GPU ist der Speicher die wichtigste Komponente einer Grafikkarte, denn die Daten müssen der GPU möglichst schnell zugeführt werden. Über das PCI-Express-Interface gelangen sie zunächst einmal in den Grafikspeicher und können von dort mit fast 1 TB/s in die GPU geladen werden. Im Laufe der Jahre hat sich die Speichertechnik bei den Grafikkarten rasant weiterentwickelt.
GDDR steht dabei für Graphics Double Data Rate und ist neben High Bandwidth Memory (HBM) ein wichtiger Speicher-Standard auf aktuellen Grafikkarten. Wie auch beim DDR-Arbeitsspeicher im Mainboard gibt es vom GDDR-Speicher mehrere Generationen. Die Double Data Rate von DDR-Speicher und damit auch GDDR wird durch eine Übertragung sowohl bei der auf- als auch bei der absteigenden Flanke des Taktsignals erreicht. Über die Generationen hinweg konnte die Bandbreite des GDDR-Speichers massiv gesteigert werden. Zugleich sank die Leistungsaufnahme deutlich. Bei GDDR sprachen wir von einer Speicherbandbreite von 25,6 GB/s an einem 256 Bit breiten Speicherinterface. Mit GDDR6X werden aktuell 936 GB/s erreicht und zukünftig sind noch schnellere Varianten geplant. Die Taktraten wurden über die Generationen hinweg von 166 MHz auf nunmehr 2.000 MHz und mehr gesteigert.
NVIDIA setzt bei den neuen GeForce-RTX-Karten auf den neuen GDDR6X-Speicher, der von Micron gefertigt wird. GDDR6X arbeitet in etwa mit dem gleichen Takt wie GDDR6 und auch die Spannungen sind vergleichbar. Aber es gibt dennoch einige Unterschiede, auf die wir nun genauer eingehen wollen.

In den vergangenen Jahren gab es mehrere Anläufe HBM auf dem Markt für Grafikkarte zu etablieren. Die hohen Kosten für den Speicher und die Entwicklung des entsprechenden Interfaces sowie in der Fertigung haben aber dazu geführt, dass wir aktuell durch die Bank mit GDDR-Speicher bestückte Karte sehen. Anders sieht dies im Server-Segment aus. Hier bietet auch NVIDIA mit der A100 Tensor GPU die Ampere-Architektur im Zusammenspiel mit HBM-Speicher an. Mittels HBM2 werden inzwischen Datenraten von bis zu 2 TB/s und mehr erreicht, während mit GDDR6X bei derzeit 936 GB/s das Ende der Fahnenstange erreicht ist.
Die Speicherbandbreite ist eine technische Spezifikation. Unterstützt wird dies durch Verfahren der Komprimierung der im Speicher befindlichen Daten. Dies spart Platz im Speicher selbst, beschleunigt aber auch die Übertragung der Daten. Eine Delta-Farbkompression hat sich bei GPUs von NVIDIA seit einigen Generationen durchgesetzt. Bei NVIDIA handelt es sich um die 6. Generation eines solchen Kompressionsverfahrens.
Wichtig dabei ist, dass es sich um ein verlustloses Kompressionsverfahren handelt. Es gehen also keine Daten verloren und Entwickler können sich auf das Verfahren verlassen, ohne speziell darauf angepasst zu entwickeln.
NVIDIA verwendet für die Speicherkomprimierung eine sogenannte Delta Color Compression. Dabei wird nur der Basispixelwert gespeichert und für die umliegenden Pixel in einer 8x8-Matrix nur noch der Unterschied (das Delta) abgelegt. Da das Delta ein deutlich kleinerer Wert ist, kann dieser schneller gespeichert werden und es wird auch weniger Platz im Speicher benötigt. Es müssen also weniger Daten in den VRAM geschrieben und daraus gelesen werden. Komprimiert werden kann aber auch der einzelne Farbwert, sodass auch hier Speicherplatz oder besser Speicherbandbreite eingespart werden kann. Ein Beispiel für die Kompression ist ein vollständiges Schwarz und Weiß, deren Wert üblicherweise als {1.0, 0.0, 0.0, 0.0} oder {0.0, 1.0, 1.0, 1.0} im Speicher abgelegt wird. In einem einfachen Verfahren reichen aber auch die Werte 0.0 oder 1.0 aus, um dies eindeutig zu beschreiben.
NVIDIA hat die Verfahren zur Detektion der komprimierbaren Bildinhalte verbessert. Das bereits bekannte 2:1 Verhältnis kann also schneller angewendet werden und ist zudem auf einen größeren Datenbestand anwendbar. Mit der vorletzten Generation hinzugekommen sind die Kompressionen um den Faktor 4:1 und 8:1.
So wird es möglich, zur Steigerung der Speicherbandbreite durch den schnelleren Speicher auch noch die Menge der Daten zu verringern, die übertragen werden müssen, was die Effektivität des Speicherinterface zusätzlich erhöht.
Mit dem GDDR6(X) Speichercontroller führt NVIDIA den Einsatz von Error Detection and Replay (EDR) fort. Der GDDR6X-Speicher arbeitet mit effektiven Taktraten von etwa 1.200 MHz. Aufgrund der immer komplexeren Fertigung des Speichers kann es bei hohen Taktraten zu Fehlern kommen. Diese lassen sich nicht verhindern und sind unter anderem einer der Gründe, warum auch für DDR5 ein On-Die-ECC eingeführt wird. Das On-Die-ECC ist mit EDR vergleichbar.
Per Error Detection and Replay werden Fehler in der Übertragung des Speichers erkannt (Error Detection) und die Daten so lange wiederholt übertragen, bis sie fehlerfrei ankommen (Replay). Anstatt der Darstellung von Artefakten werden die Übertragungsfehler erkannt und der Speichercontroller versucht diese zu kompensieren. Es handelt sich um einen Cyclic Redundancy Check (CRC) und damit um ein Verfahren, welches mit einem Prüfwert für die Daten arbeitet. Stimmt der Prüfwert nicht, ist es bei der Übertragung zu einem Fehler gekommen.

Ohne CRC bzw. Error Detection and Replay kommt es bei steigendem Takt zu Fehlern und damit zu Artefakten. Damit steigt auch das Risiko, dass es zu einem Absturz kommt bzw. der Treiber zurückgesetzt wird.
Mit Error Detection and Replay werden Fehler immer ausgeglichen. Beim Overclocking ist dann aber irgendwann ein Plateau erreicht, an dem die effektive Speicherbandbreite nicht mehr ansteigt. Bis zum Erreichen des Plateaus kommt es üblicherweise noch nicht zu Abstürzen. EDR sichert also zum einen die Daten für den Normalbetrieb ab und macht ein derart schnelles Speicherinterface überhaupt erst möglich. Die Funktion hilft aber auch beim Overclocking und ist eine Hilfestellung im Grenzbereich des Speichers.
Die Spannungsversorgung
Der Strom- und Spannungsversorgung kommt auf den modernen Grafikkarten eine wichtige Rolle zu. NVIDIA sich in jüngster Vergangenheit mit den aktuellen Referenz-Umsetzungen sehr positiv hervorgetan. PCB-Designs und die der Spannungsversorgung der GeForce-RTX-30-Serie sind extrem durchdacht. Einerseits zeigt sich dies im Design der Founders Editionen, aber auch in den Referenzdesigns der PCBs, die dann von den Boardpartnern verwendet werden.
Die Versorgung von GPU, Speicher und den weiteren Komponenten ist ein sehr komplexes Thema. Eine NVIDIA-GPU kommt auf bis zu 28 Milliarden Transistoren aus einer 8-nm-Fertigung, die in mehreren Spannungsebenen, die extrem genau abgestimmt sind, versorgt werden muss. Hinzu kommt, dass wir nicht von einer statischen Versorgung sprechen, sondern diese aufgrund von Lastwechseln eine weitere Ebene der Komplexität erreicht. Ein weiterer Faktor ist, dass eine Spannungsversorgung nicht zum eigentlichen Verbraucher einer Grafikkarte werden sollte, sondern effizient arbeiten muss.

Die wichtigste Rolle innerhalb einer Strom- und Spannungsversorgung kommt den Voltage Regulator Modulen (VRM) zu. Die VRMs sorgen dafür, dass aus den 12 V, die aus dem Netzteil des PCs kommen, die etwa 1 V werden, die zur Versorgung der GPU und des Speichers notwendig sind.
Viele Hersteller werben mit der Anzahl der Spannungsphasen. Doch hier gilt nur auf den ersten Blick "je mehr, desto besser". Grundsätzlich lässt sich sagen: Je höher die Thermal Design Power, also der Verbrauch der Karte, desto mehr Spannungsphasen sind zur Versorgung notwendig.
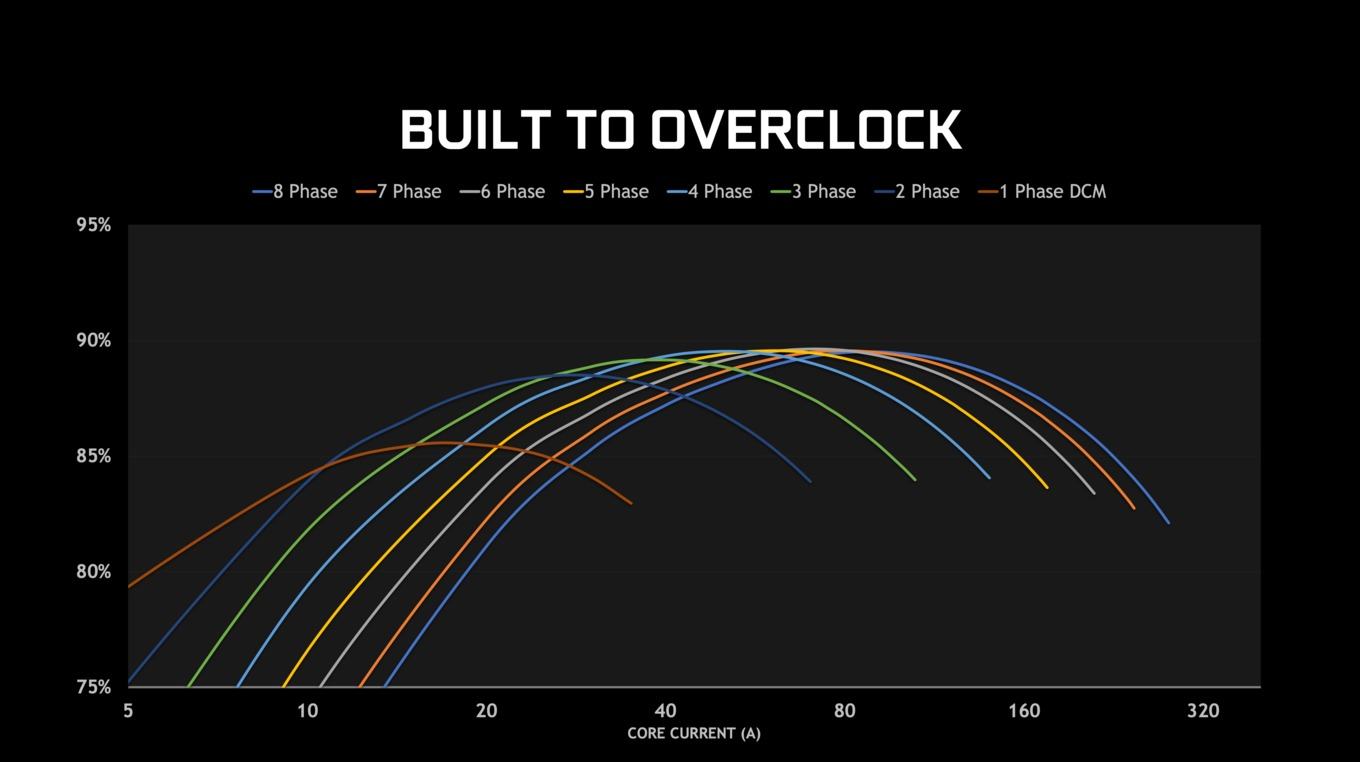
Grundsätzlich kann festgehalten werden: Je mehr Phasen verbaut sind, desto besser ist die Versorgung bei höheren Strömen. Allerdings zeigt sich auch, dass eine Mehrzahl an benötigen Phasen den Bereich der höchsten Effizienz immer weiter nach oben schiebt. Viele Phasen haben während des Switchings hohe Verluste. Je mehr Phasen, desto höher sind also die ungewollten Verluste. NVIDIA hat daher bereits für die GeForce-RTX-20-Serie eine Spannungsversorgung entwickelt, die dynamisch Phasen zu- und abschalten kann – je nachdem wie viel gerade von der Karte gefordert wird. Damit soll sich die Spannungsversorgung immer in einem idealen Bereich bewegen. Die GeForce RTX 3090 verfügt über eine 20-Phasen-Spannungsversorgung, die dynamisch zwischen einer und den vollen acht Spannungsphasen hinzu- oder abgeschaltet werden können. Bei der GeForce RTX 3080 sind es 18 Phasen und so nimmt die Anzahl mit den kleineren Modellen und einem geringeren Verbrauch immer weiter ab.
Erfolgt die Versorgung über zwei oder drei 8-Pin-Anschlüsse muss ein gewisses Balancing stattfinden, damit jeder der Anschlüsse gleichmäßig belastet wird. Zudem muss sichergestellt werden, dass über den PCI-Express-Steckplatz nur die maximal zugelassenen 66 W auf der 12-V-Schiene abgerufen werden. Stellt man sich nun auch noch vor, dass eine Grafikkarte nicht stetig sagen wir 250 W verbraucht, sondern dieser Wert im Millisekundenbereich um mehrere Prozent schwankt, wird deutlich wie viel Ingenieurskunst in der Entwicklung einer solchen Spannungsversorgung steckt.
Das GPU-Package
Die wichtigste Hardware-Komponente auf einer Grafikkarte ist die GPU. Diese sitzt allerdings nicht als blanker Chip auf dem PCB (Printed Circuit Board), sondern in einem GPU-Package. Dieses GPU-Package besteht aus einem Trägermaterial, meist ebenfalls ein PCB, welches die Anbindung des Chips über ein BGA (Ball Grid Array) zur Grafikkarte selbst ermöglicht. Es gibt aber auch GPUs, die per BGA direkt mit dem PCB der Grafikkarte verbunden werden. Die Antwort ist also einmal mehr: Es kommt darauf an, wie das GPU-Package aufgebaut ist.
Schaut man sich ein typisches GPU-Package etwas genauer an, ist zentral die eigentliche GPU zu erkennen, darum sind aber bereits die ersten SMD-Bauteile, bei denen es sich meist um Widerstände handelt. Dieses GPU-Package wiederum wird über ein BGA mit dem PCB der Grafikkarte verbunden. Der Grafikspeicher sitzt im Falle von GDDR6(X) außerhalb des GPU-Package.
NVIDIA fertigen aber auch die A100 Tensor GPU, bei der der Grafikspeicher in Form des HBM in direkter Nähe positioniert wird. GPU und HBM sind über einen Interposer miteinander verbunden. Beim Interposer handelt es sich ebenfalls um ein Halbleitermaterial. In dieses werden über unterschiedliche Verfahren vertikale und horizontale Leiterbahnen eingebracht, welche die Verbindung zwischen der GPU und dem HBM herstellen.

Der Vorteil von HBM ist das extrem breite Speicherinface und damit sind auch extrem hohe Speicherbandbreiten möglich. Eine solche Anbindung ist aber nur über einen Interposer möglich, denn pro Speicherchip müssen 1.024 Bit bzw. mindestens 1.024 Leiterbahnen realisiert werden. Bei zwei oder vier Speicherchips sprechen wir also schon von mehr als 4.000 Einzelverbindungen. Die Fertigung eines Interposers ist nicht ganz einfach und vor allem teurer als ein einfaches GPU-Package per BGA auf ein PCB zu bringen. Zudem reicht es nicht mehr aus, die GPU bei einem Auftragsfertiger fertigen und dann aufs PCB bringen zu lassen. Vielmehr müssen weitere Unternehmen mit einbezogen werden, die GPU und HBM auf dem Interposer zusammenbringen.
Dies ist auch einer der Gründe (neben der Verfügbarkeit und den Kosten für HBM), warum HBM bei nur wenigen aktuellen Grafikkarten zum Einsatz kommt. Derzeit setzt NVIDIA den HBM - und damit auch ein entsprechendes GPU-Package - nur bei der A100-Tensor-GPU ein. Hier spielen die Kosten weniger große Rolle und zudem sind die entsprechenden Anwendungen auf eine möglichst hohe Speicherbandbreite angewiesen.
Zusätzliche Anschlüsse
Neben den auf der vorherigen Seite erwähnten Display-Anschlüssen und solchen zur Versorgung der Grafikkarte gibt es aber auch noch einige weitere, die aber größtenteils keine Rolle mehr spielen – zumindest nicht für Spieler. Ein Multi-GPU-Betrieb wird nicht mehr unterstützt, weder von den Grafikkartenherstellern, noch von den meisten Spielen. Dennoch verfügt zumindest die GeForce RTX 3090 noch über einen NVLink-Anschluss. Diese finden sich auch an den Desktop-Workstation-Karten der RTX-Serie.

Per NVLink 3.0 ist es möglich, zwei bis zwölf GPUs miteinander zu verbinden. Bei den RTX-Karten der Workstation-Serie können nur zwei Karten zusammengefasst werden. Bei der A100 Tensor GPU sind es bis zu zwölf, die dann untereinander mit bis zu 600 GB/s Daten austauschen können. Mit diesen 600 GB/s ist die Datenrate deutlich höher, als dies ein PCIe 4.0 x16 mit 31,5 GB/s ermöglichen kann. Der verbaute Speicher der GPUs kann zudem als ein großer Gesamtspeicher angesehen werden, auf den alle angebundenen GPUs zugreifen können. Im Falle des Einsatzes zweier GeForce RTX 3090 mit jeweils 24 GB stehen demnach also 48 GB insgesamt zur Verfügung.
Im Datacenter kommen hier noch einmal ganz andere Zahlen zusammen. 16 A100 Tensor GPUs mit jeweils 80 GB stellen 1,28 TB an schnellem Speicher bereit, der untereinander mit 600 GB/s gelesen und geschrieben werden kann. Ein NVLink Switch kümmert sich um die Anbindung aller GPUs und erreicht eine kumulierte Bandbreite von 9,6 TB/s.
In Kooperation mit NVIDIA
