
Zur offiziellen Vorstellung der Meteor-Lake-Prozessoren Mitte Dezember präsentierte ASUS das Zenbook 14 OLED. Zur CES hatten wir nun die Gelegenheit, uns das Notebook etwas genauer anzuschauen und Benchmarks durchzuführen. Einen großen Unterschied zur Vorserienanalyse erwarten wir nicht. Gibt es Unterschiede, dann sind diese maßgeblich mit dem unterschiedlichen Power-Limit zu begründen.
Insofern haben wir uns auf einige Aspekte konzentriert, die in unseren Tests bisher noch keine große Rolle gespielt haben. So wollen wir die Leistung der integrierten GPU noch einmal beleuchten. Im ersten Vorab-Test drehte sich der Vergleich hauptsächlich um die 13. Core-Generation. Nun wollen wir auch einen Blick auf die Konkurrenz wagen. Die Latenzen der CPU-Kerne haben wir uns zudem noch angeschaut.
Aber zunächst ein paar Worte zum ASUS Zenbook 14 OLED: Wie der Name vermuten lässt, basiert das 14-Zoll-Display auf einem OLED-Panel, das mit 2.880 x 1.800 Bildpunkten ans Werk geht und entsprechend das etwas höhere 16:10-Format nutzt. Maximal soll eine Helligkeit von 600 cd/m² erreicht werden, während eine Wiederholfrequenz von 120 Hz für eine flüssige Darstellung sorgen soll.







Das Alu-Gehäuse ist nur 14,9 mm dick und bringt 1,2 kg auf die Waage. Anschlussseitig werden trotz des kompakten Designs zwei Thunderbolt-4-Ports, HDMI 2.1 und eine Typ-A-Schnittstelle mit USB 3.2 Gen1 geboten.
Maximal verbaut werden kann ein Intel Core Ultra 7 155H. In dieser Variante haben wir das Notebook auch getestet. Kombiniert werden kann der Prozessor mit bis zu 32 GB an Arbeitsspeicher und einer 1 TB fassenden SSD. Der Preis beginnt bei 1.499 Euro.
GPU-Benchmarks
Die integrierten Grafikeinheit auf Basis der Xe-LPG-Architektur bietet acht Xe-Kerne und soll eine doppelt so hohe Leistung wir ihr Vorgänger vorzuweisen haben. Im ASUS Zenbook 14 OLED darf sich der Core Ultra 7 155H 28 W genehmigen. Für die Mobil-Prozessoren ziehen wir einen Core i9-13900HK mit einem PL1 von 115 W heran. Die hier verbaute Iris Xe Graphics mit 96 der alten Xe-Kerne ist aber sicherlich nicht im Verbrauch limitiert. Hier reicht die Rohleistung einfach nicht mehr aus, um mehr als eine 2D-Darstellung oder ein Videodecoding sinnvoll durchführen zu können.
Ein Core i9-14900K verfügt ebenfalls über eine integrierte Grafikeinheit, diese kommt mit 32 Xe-Kernen aber nur auf ein Drittel das GPU-Ausbaus des Core i9-13900HK. Die aktuellen Ryzen-7000-Prozessoren bieten nun immer 2 Compute Units auf Basis der RDNA-3-Architektur.
Der interessante Vergleich aber wird sicherlich gegenüber dem ASUS ROG Ally mit Ryzen Z1 Extreme und dem AYANEO 2S mit Ryzen 7 7840U. Letztgenannter verwendet eine Radeon 780M mit 12 Compute Units. Auch im Ryzen 1 Extreme 12 CUs aktiv. Auch die schnellsten Ryzen-8040U-Prozessoren, die in den kommenden Wochen auf den Markt kommen werden, verwenden die Radeon 780M. Insofern bekommen wir nun einen ganz guten Eindruck, zu was die integrierte Grafik des Core Ultra 7 155H im Stande ist.
Als Treiber kam der aktuelle Arc in der Version 5122 zum Einsatz.
UL 3DMark
Night Raid (Grafikpunkte)
Werbung
UL 3DMark
Fire Strike (Grafikpunkte)
UL 3DMark
Time Spy (Grafikpunkte)
Wie bei allen Benchmarks gilt es immer den Verbrauch bzw. das Power-Limit mit im Auge zu behalten. Auch die Größe und Anbindung des Arbeitsspeichers spielt eine Rolle, denn dieser wird von der GPU als Grafikspeicher verwendet. Das ASUS Zenbook 14 OLED bzw. der Core Ultra 7 155H kommt hier in etwa auf die gleiche Leistung wie die aktuellen integrierten Grafiklösungen von AMD mit 12 CUs.
Intel scheint zumindest auf Niveau dessen zu landen, was AMD schon fast ein Jahr zu bieten hat. Damit kann man zumindest in niedrigen Einstellungen in 1080p-Auflösung spielen. Einen Vorsprung kann sich Intel aber wohl eher nicht erarbeiten.
Die nächste Frage ist nun, ob nun AMD oder Intel den nächsten Schritt machen und die Leistung der integrierten GPU verbessern.
Leistungsskalierung
Spannend ist sicherlich auch, wie sich die Meteor-Lake-Prozessoren verhalten, wenn sie mit unterschiedlichen Power-Limits betrieben werden. Auch hier können wir einen ersten Vergleich versuchen, wenngleich wir zudem auch von unterschiedlichen Kühlungen in den Notebooks sprechen.
Cinebench R23
Multi-Threaded
Im Acer Predator Triton Neo 16 mit Core Ultra 7 155H kommt dieser mit seinen 6P+8E-Kernen und 64 W Power-Limit auf 17.465 Punkte. Im MSI Prestige 16 mit 55 W sind es 15.535 Punkte. Hier kam zwar ein Core Ultra 7 165H zum Einsatz, dieser besitzt aber nur etwas schnellere Kerne, die Anzahl ist identisch.
Durch das auf 28 W beschränkte Power-Limit kommt der Core Ultra 7 155H im ASUS Zenbook 14 OLED auf 7.878 Punkte – also nicht einmal die Hälfte. Die Punkte skalieren aber ganz gut mit dem deutlich niedrigeren Verbrauch.
Kernlatenzen
Der Meteor-Lake-Prozessoren besteht aus vier aktiven Tiles: Im Compute-Tile sitzt der Compute Complex mit den CPU-Kernen – Sechs Performance-Kernen und acht Efficiency-Kernen. Im SoC-Tile finden sich zwei weitere Low-Power-Efficiency-Kerne. Die LP-E-Kerne sollen sämtliche Hintergrundaufgaben übernehmen. Der Windows Thread Director versucht alle Threads auf den LP E-Cores des SoC-Tiles zu belassen, es sei denn die Prioritäten werden anders zugeordnet.
Im SoC-Tile ist ein NOC (Network on a Chip Fabric) vorhanden, der die LP E-Cores mit den weiteren Komponenten des SoC-Tiles verbindet. Die Tiles kommunizieren über ein Tile2Tile-Interface miteinander.
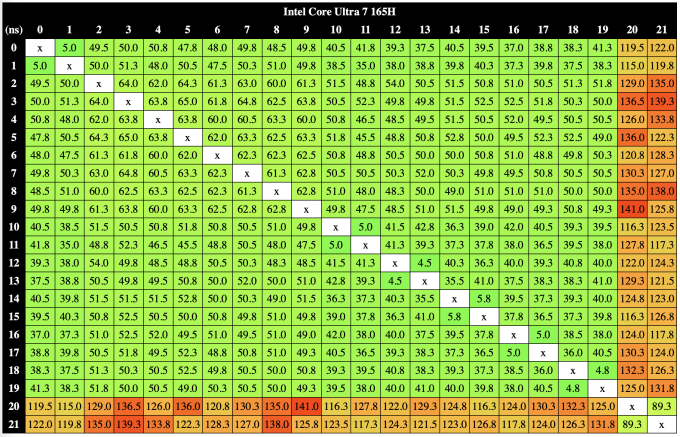
Die Kerne im Compute-Tile haben eine Latenz von etwa 50 ns zueinander. Die Latenzen bewegen sich von Kern zu Kern zwischen minimal etwa 35 ns und maximal etwa 50 ns. Dies kommt darauf an, wie weit die jeweils miteinander kommunizierenden Kerne auseinanderliegen. Unterschiede zwischen den Performance- und Efficiency-Kernen sehen wir nicht.
Wohl aber zu den LP-E-Kernen. Diese kommen untereinander schon auf eine Latenz von etwa 90 ns, was vergleichsweise viel ist. Die LP-E- zu den P-oder E-Kernen kommen auf eine Latenz von 120 bis 140 ns. Dies erklärt auch, warum der Thread Director bemüht ist, die Threads so lange wie möglich auf den LP-E-Kernen zu belassen. Ein Wechsel zwischen den Kern-Instanzen kostet Zeit und damit Ressourcen – ist also ineffizient.
Die Auswirkungen in der Praxis kennen wir nicht. Die Messungen geben den Aufbau des Meteor-Lake-Prozessors aber ganz schön wieder.
Effizienz ist der Fokus
Die Meteor-Lake-Prozessoren stellen keine neuen Leistungsrekorde auf – so viel war schon in der Theorie klar und zeigte sich auch schnell nach den ersten Benchmarks. Aber die Effizienz scheint die Domäne zu sein. Hinsichtlich der GPU-Leistung kann Intel mit seiner integrierten Lösung mit dem Angebot von AMD aufschließen. Im Zweifel könnte sie sogar etwas schneller sein. Aber das werden die ersten ausführlichen Tests zeigen müssen.
Interessant sind die Aspekte wie die Leistungsskalierung und die Messungen zu den Latenzen. Sie geben einen Einblick in die Auslegung von Meteor Lake und auch die Kompromisse, die Intel dabei eingehen muss.
