
Werbung
In unserer Berichterstattung zu den aktuellen Ryzen-9000-Prozessoren gibt es noch ein paar Lücken, die wir gerne auffüllen würden. Dazu gehört neben dem Test des Ryzen 9 9900X, den wir noch nicht in den Fingern hatten, eine weitergehende Analyse der Zen-5-Architektur sowie der Umsetzung in Form von Granite Ridge mit einem und zwei CCDs. Heute wollen wir uns mit den Themen IPC-Leistung, Latenzen sowie Cache- und Speicherbandbreite beschäftigen.
Bevor wir dazu kommen, noch eine kurze Auflistung der bisherigen Artikel zur Theorie zur Zen-5-Architektur sowie der Tests:
- AMD Tech Day: Alle Details zu Zen 5 und den dazugehörigen Plattformen
- Zen 5: Weitere Details zur Architektur und dem SoC-Aufbau
- Mit Zen 5 auf bewährter Plattform: AMD Ryzen 5 9600X und Ryzen 7 9700X im Test
- AMD Ryzen 9 9950X im Test: Nachzügler für die Spitzenposition
Wir hoffen in Kürze einen Ryzen 9 9900X zu erhalten, so dass wir die erste Welle an Prozessoren mit ihren vier Modellen komplett abschließen können.

Gerne wären wir heute bereits auf die DDR5-Leistung mit mehr als 6.000 MT/s eingegangen, dazu aber sind noch weitere Tests notwendig und etwas mehr Hardware in Form von Speicherkits sowie einem Mainboard steht noch aus. Darauf werden wir also zu einem späteren Zeitpunkt zurückkommen müssen.
Kern-Latenzen
Bereits im Test des Ryzen 9 9950X haben wir kurz unsere Analyse der Kern-Latenzen angesprochen. Der C2C-Test (Kern-zu-Kern) des MicroBenchX misst die Latenzen zwischen den einzelnen Kernen.

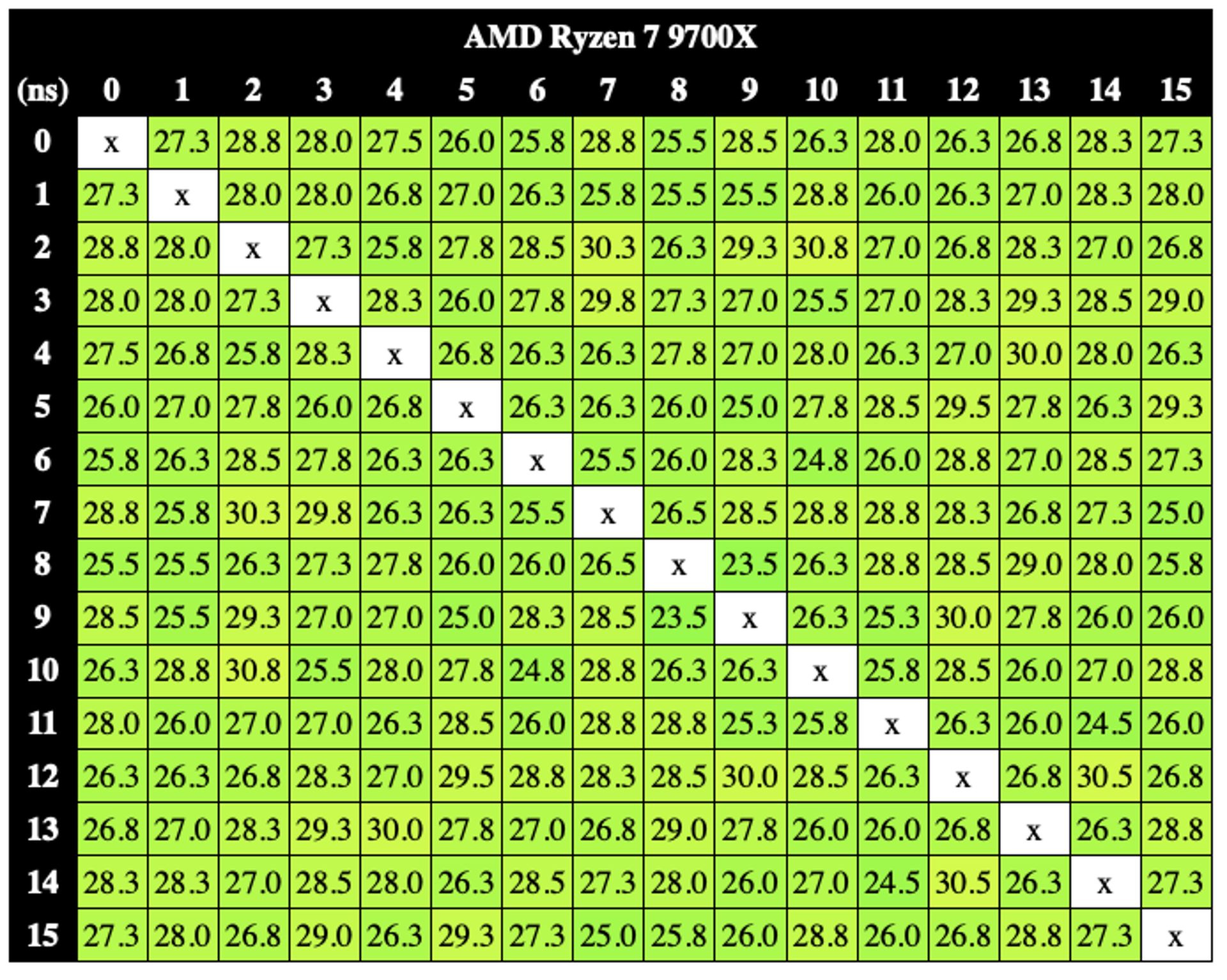

Die oberen beiden Diagrammen zeigen die Kern-Latenzen des Ryzen 5 9600X und Ryzen 7 9700X, bei denen es keinerlei Überraschungen gibt. Zwischen den Kernen (hier wegen SMT mal zwei genommen) bewegen wir uns in einem Latenzbereich von 25 bis 30 ns. Diese beiden Prozessoren besitzen einen CCD und die Kerne kommunizieren auch innerhalb dieses einen CCDs miteinander.
Anders sieht dies beim Ryzen 9 9950X (und auch Ryzen 9 9900X) aus, denn hier arbeiten auf zwei CCDs jeweils acht, bzw. sechs Kerne. Die Latenzen zwischen den Kernen auf dem gleichen CCD sind deutlich geringer (grün) als die zu den Kernen auf dem zweiten CCD (orange und rot). Dies ist unter anderem einer der Gründe, warum Anwendungen im Multi-Threaded-Bereich (und vor allem Spiele) versuchen, auf den Kernen eines CCDs zu laufen und nicht andauernd zu wechseln.
Allerdings sind die fast 250 ns deutlich mehr, als beispielsweise bei einem Ryzen 9 7950X, bei dem die Kerne zwischen zwei CCDs auf eine Latenz von etwa 80 ns kommen. Warum dies so ist, wissen wir nicht. Allerdings dürfte dies einen gewissen Einfluss auf die Leistung haben, wenn Threads von einem auf den anderen Kern und von einem auf das andere CCD übergeben werden. Dies versuchen Anwendungen, bzw. der Scheduler zwar zu vermeiden, es kann jedoch vorkommen. Da das CCD mit den Zen-5-Kernen in einem ähnlichen Aufbau mit deutlich mehr Chiplets für die EPYC-Prozessoren zum Einsatz kommen soll, sollten diese hohen Latenzen eigentlich vermieden werden. Selbst mit vier, acht oder zwölf CCDs – bisher konnte AMD die Latenzen bei 80 ns beibehalten.
Wir sind bereits seit dem Test des Ryzen 9 9950X mit AMD in Kontakt und haben nachgefragt, warum es zu diesen hohen Latenzen kommt und welchen Einfluss diese haben. Spiele, die mehr als acht Kerne verwenden, dürften nachteilige Effekte dadurch haben. Bisher konnte uns AMD, trotz mehrfacher Nachfrage, keine Erklärung liefern.
Cache- und Speicherlatenzen
Änderungen beim Cache gibt es für die Zen-5-Architektur vor allem in der obersten Ebene – nahe der eigentlichen Kerne. Der L1-Data-Cache ist nun 48 kB groß und umfasst bei der Zen-4-Architektur 32 kB. Zwischen dem L1- und L2-Cache wird die Bandbreite von 32 auf 64 Bytes pro Taktzyklus verdoppelt. Keinerlei Änderungen gibt es in der Bandbreite zwischen dem L2- und L3-Cache sowie in der Anbindung zum Speichercontroller.

In der Messung der Latenzen sehen wir einen Unterschied für die Testgröße von 32 und 48 kB, was sehr schön den größeren L1-Data-Cache aufzeigt, der nun eben 48 kB aufnimmt und die Daten nicht schon in den L2-Cache schiebt. Ansonsten gibt es hier eine leichte Verschiebung, bzw. leicht höhere Latenzen für die Zen-4-Architektur, da AMD die Bandbreite zwischen dem L1- und L2-Cache erhöht hat, was dann je nach Testgröße und einer Aufteilung der Daten einen Einfluss auf die Latenzen hat.
Am Ende landen wir bei einer Testgröße von mehr als 16 MB im Speicher, was die entsprechenden Latenzen im Bereich von 80 ns nach sich zieht.
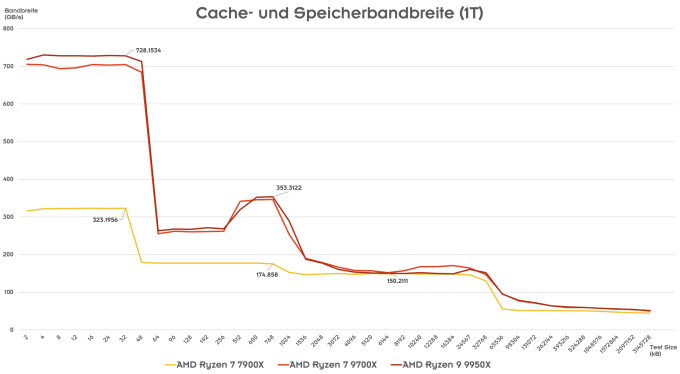
Die Verdopplung der Bandbreite zwischen dem L1- und L2-Cache sowie die Erhöhung der Fetch-, Store und Load-Einheiten im Backend der Zen-5-Architektur zeigt sich bei einem Blick auf die Cache- und Speicherbandbreite. Hier liegen der Ryzen 9 9950X und Ryzen 7 9700X im 1T-Test gleichauf, da nur ein Kern auf einem CCD genutzt wird.
Einen Unterschied gibt es allerdings zwischen einem Ryzen 7 7700X und dem Ryzen 7 9700X sowie dem Ryzen 9 9950X, wenn man sich die Cache- und Speicherbandbreite bei kleineren Testgrößen anschaut. Hier kommt der größere L1-Data-Cache mit 48 kB ebenso zum Tragen wie die höhere Bandbreite zwischen dem L1- und L2-Cache.

Für Granite Ridge findet die Anbindung des CCX/CCD an den IOD per Infinity Fabric statt. Wie auch bei den Ryzen-7000-Prozessoren handelt es sich um eine asymmetrische Anbindung. Der CCD kann mit 32 Byte pro Taktzyklus vom IOS lesen, aber nur mit 16 Bytes pro Taktzyklus schreiben. Dies hat dahingehend Auswirkungen, dass die Ryzen-Prozessoren mit nur einem CCD (Ryzen 7 9700X und Ryzen 5 9600X) im Schreibdurchsatz limitiert sein werden. Dies konnten wir bei den Ryzen-7000-Prozessoren bereits darstellen und das werden wir auch für die Ryzen-9000-Prozesoren noch unter die Lupe nehmen. Dies aber in einem gesonderten Artikel.
Greifen alle Kerne auf die Caches und den Speicher zu, können zwei CCDs (Ryzen 9 9950X) für eine deutlich höhere Bandbreite sorgen, als dies mit einem CCD (Ryzen 7 9700X) der Fall ist. Dies gilt bis zu einer Testgröße von 32 MB, die noch jeweils in den L3-Cache des CCDs passen. Danach müssen die Daten über den IOD in den Arbeitsspeicher ausgelagert werden. Zwei CCDs können mit jeweils 32 Byte pro Taktzyklus lesen und mit 16 Byte pro Taktzyklus schreiben. Ein CCD mit jeweils nur einmal 32, bzw. 16 Byte je Taktzyklus.
Offenbar konnte AMD den Takt des Infinity Fabric nicht groß steigern. Dies ist vor allem dann entscheidend, wenn schnellere Speicher in einem möglichst effektiven Taktverhältnis zwischen Speicher, Speichercontroller und dem Infinity Fabric zum Einsatz kommen soll. Standardmäßig erlaubt AMD bei den Ryzen-Desktop-Prozessoren einen maximalen Takt von 2.000 MHz für den Infinity Fabric. Mit EXPO liegen bis zu 2.100 MHz an. Aber das Thema Speicherbandbreite und Limitierung durch das CCD-Design schauen wir uns wie gesagt noch einmal genauer an.
IPC-Tests
Bereits in den Tests des Ryzen 9 7950X und auch Ryzen 9 5950X haben wir Sondertests in Form eines IPC-Tests bei einem fixen Takt von 4 GHz vorgenommen, damit eben die Instruktionen pro Taktzyklus, abgebildet werden können.
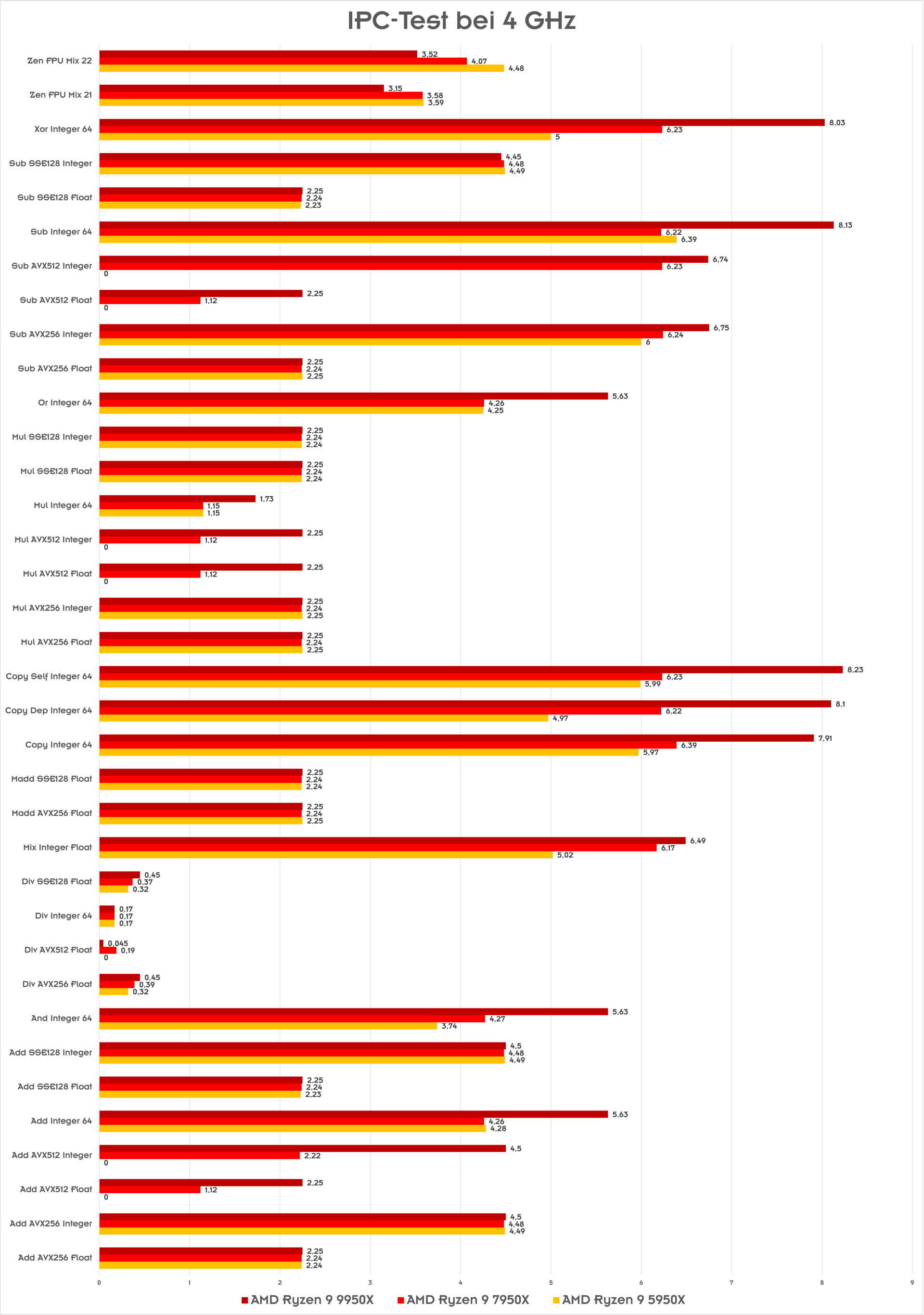
Der breitere Aufbau der Zen-5-Architektur wird hier dahingehend sichtbar, dass allen voran 33 % mehr Integer-Operationen ausgeführt werden können. Keinerlei Veränderungen gibt es hingegen bei den Fließkomma-Operationen. Schaut man ausschließlich auf Operationen mit AVX512-Befehlssätzen, konnten diese auf dem Ryzen 9 5950X (Zen 3) noch gar nicht ausgeführt werden, müssten beim Ryzen 9 7950X (Zen 4) in 2x 256 Bit aufgeteilt werden und können nun durch den Ryzen 9 9950X (Zen 5) in einem Taktzyklus abgearbeitet werden, was die IPC-Leistung in diesem Aspekt verdoppelt.
Zen 5 ist gut, aber die Umsetzung nicht immer perfekt
Es ist schon erstaunlich, in welchen Schritten AMD in der Lage ist, seine Zen-Architektur weiterzuentwickeln. Zen 5 soll nun die Basis dessen sein, was wir vermutlich auch für Zen 6 und Zen 7 sehen werden – mit kleineren Weiterentwicklungen eben. Ähnlich ging AMD mit der Zen-3-Architektur vor, die einen größeren Schritt gegenüber Zen 2 darstellte und die Basis für Zen 4 war.
AMD hat vor allem das Front- und Backend deutlich aufgewertet und sorgt damit für das IPC-Plus im Integer-Bereich. Die Möglichkeit, AVX512-Befehlssätze in voller Breite auszuführen, hebt die Zen-5-Architektur in der Compute-Leistung ebenfalls deutlich an. Dabei hat AMD die Flexibilität für die mobile Umsetzung nicht aus den Augen verloren und kann dennoch Zen-5- und -5c-Kerne liefern, die weiterhin ISA-kompatibel sind.
Die Vergrößerung des L1-Data-Cache, die Verdopplung der Bandbreite zwischen L1- und L2-Cache sowie vergleichsweise große DTLB (Data Translation Lookaside Buffer) für den L1- und L2-Cache spielen für die Sprungvorhersage eine wichtige Rolle. Deren Vorteile haben wir noch gar nicht sehen können, da AMD erst die spezifischen Optimierungen in Windows 24H2 nachliefert. Aktuell testen wir die Ryzen-9000-Prozessoren mit Windows 11 24H2 und werden in Kürze erste Ergebnisse liefern.
AMD muss jedoch einige Kompromissen eingehen, die deutlich erkennbar sind. So hat man zwar zwei Decoder-Cluster je Kern, diese können jedoch nur dann voll ausgeschöpft werden, wenn SMT aktiv ist. Es ist nicht möglich, dass beide Cluster an einem Thread arbeiten. Ein 4-Wide Decoding ist für einen einzigen Thread nur sehr selten der limitierende Faktor – ein Kompromiss eben, der für 99 % der Anwendungen aufgeht.

AMD hat noch einige Baustellen. Das Core Parking funktionierte beim Wechsel auf einem Prozessor mit zwei CCDs (Ryzen 9 9900X und Ryzen 9 9950X) auf einen solchen mit einem CCD (Ryzen 5 9600X und Ryzen 7 9700X) noch nicht immer, bzw. setzt im schlimmsten Fall eine Neuinstallation von Windows voraus. Die spezifischen Optimierungen in Windows 24H2 sollen ebenfalls noch geliefert werden und schlussendlich ist uns AMD noch eine Antwort schuldig, was nun mit den zu hohen Latenzen ist.
Das Versprechen, nun höhere Speichertaktraten zu unterstützen, schauen wir uns in den kommenden Tagen genauer an. Hier dürfte der Infinity Fabric zum limitierenden Faktor werden. Aber dazu dann zu gegebener Zeit mehr.
