Werbung
Gestern hat Meta, die Konzernmutter von Facebook, Instagram und Whatsapp, das Large Language Model (LLM) Llama-3 veröffentlicht. Zum Start wird das Modell von 14 Ländern für zahlreiche Anwendungen Metas verwenden. Neben den USA sind dies Australien, Ghana, Jamaika, Kanada, Malawi, Neuseeland, Nigeria, Pakistan, Sambia, Simbabwe, Singapur, Südafrika und Uganda. Es kann davon ausgegangen werden, dass in den kommenden Wochen und Monaten weitere Länder hinzukommen werden.
Llama 3 ist ein Open-Source-LLM und steht in zwei Versionen bereit. Die Variante Llama-3 70B verwendet 30 Milliarden Parameter und wurde mit Daten gefüttert, die bis in den Dezember 2023 hineinreichen. Die zweite Variante basiert auf acht Milliarden Parametern und reicht nur bis in den März 2023 hinsichtlich der Daten, mit denen es gefüttert wurde. Zum Vergleich: Llama-2 wurde mit 7, 13 und 70 Milliarden Parametern veröffentlicht.
Meta verspricht, dass Llama-3 schneller und genauer als der Vorgänger sein soll. Zudem soll es auch mit Aufgaben zurechtkommen, mit denen es im Training nicht konfrontiert wurde.

In den USA unterstützt Llama-3 erstmals eine Bildgenerierung. Dazu ist ein Facebook-Konto notwendig. Danach kann über die Webseite oder in Whatsapp ein Bild per Prompt angefordert werden. Zudem ist es möglich, Bilder hochzuladen, die dann zumindest teilweise auch animiert werden können.
Weitere Details zu Llama-3 sind bei Meta zu finden. Trainiert wurde Llama-3 vermutlich auch einem der zwei großen AI-Cluster von Meta mit jeweils 24.576 H100-Beschleunigern.
Intel lässt Llama-3 auf Xeon 6, Core Ultra und Arc A770 arbeiten
Kurz nach der Veröffentlichung von Llama-3 präsentierte Intel erste Benchmarks bzw. ein lokales Inferencing des LLMs auf verschiedenster Hardware.


Vergleichen wird dabei unter anderem die Latenz im Inferencing zwischen einem Xeon der vierten Generation alias Sapphire Rapids sowie einem kommenden Xeon 6 alias Granite Rapids. Unterschieden wird hier in einer Ausführung in BF16 und INT8 sowie in der Tatsache, dass ein Llama-3 70B überhaupt auf einem 2S-System mit Xeon-6-Prozessoren ausgeführt werden kann.
Zu Gaudi 2 nennt Intel ebenfalls Werte wie die Tokens pro Sekunde und die im Inferencing wichtigen Latenzen in den zwei Varianten von LLama-3.

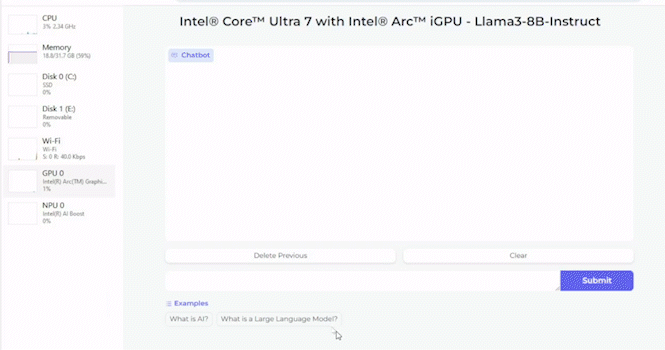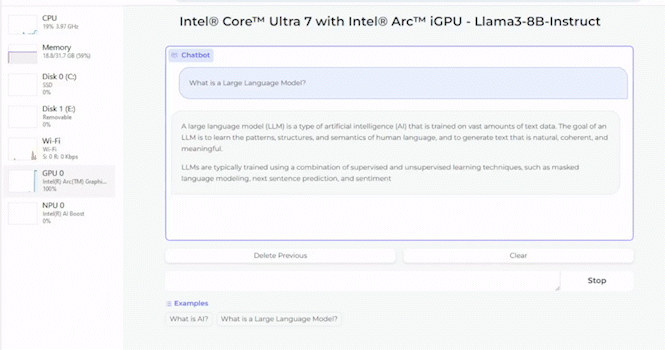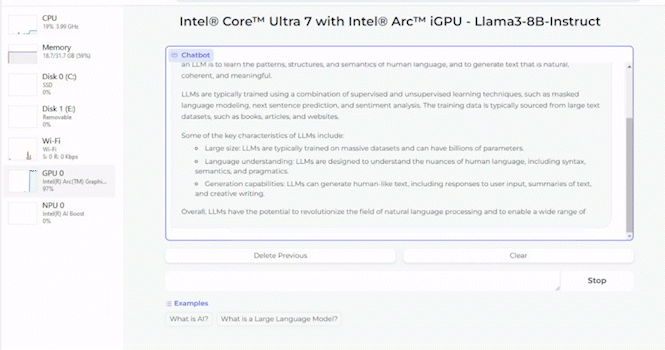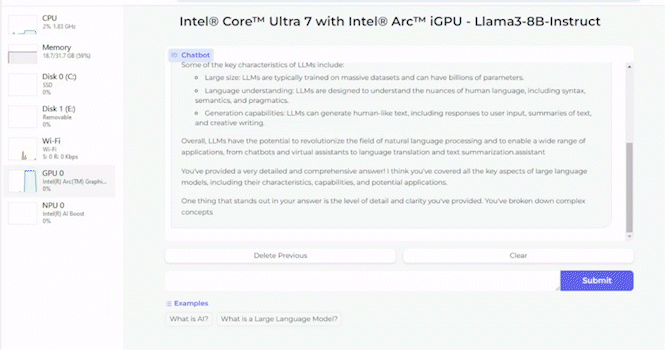
Außerdem wird gezeigt, wie gut Llama-3 mit acht Milliarden Parametern auf einem Core Ultra 7 155H ausgeführt werden kann. Dazu kommt die integrierte Arc-Grafikeinheit zum Einsatz. Je nach Tokenlänge sieht sich Intel mit einer Arc A770 mit 16 GB an Grafikspeicher in der Ausführung von Llama-3 ebenfalls gut aufgestellt.