
Werbung
Nachdem NVIDIA auf der GPU Technology Conference bereits viele Details zur Pascal-Architektur bzw. der ersten Umsetzung in Form der GP100-GPU veröffentlicht hat, folgt heute das Whitepaper, welches diese Informationen noch einmal in allen Details aufführt – wer möchte kann sich das Whitepaper bei NVIDIA herunterladen. Die meisten technischen Daten sind uns dabei bereits bekannt, einige sind aber auch neu und daher werden wir das Whitepaper erneut aufarbeiten. Wer sich einen ersten Überblick verschaffen möchte, dem legen wir unseren ausführlichen Artikel zur Pascal-Architektur nahe.
Was NVIDIA vor wenigen Wochen vorgestellt hat, darf durchaus als beeindruckend bezeichnet werden. Eine im 16-nm-FinFET-Verfahren gefertigte GPU mit einer Chipfläche von 610 mm2 bei 15,3 Milliarden Transistoren darf vorläufig als Meilenstein der Halbleiterfertigung bezeichnet werden. Zwar ist Intels Xeon Phi Knights Landing mit 700 mm2 noch etwas größer, allerdings kommt dieser auf nur 8 Milliarden Transistoren und die Chipfläche ist wohl maßgeblich dem Mesh-Aufbau sowie den großen Caches geschuldet. Zur Fertigung gehört auch die Interposer-Technologie, die NVIDIA zu TSMC ausgelagert hat (TSMC CoWoS). Auf dem Interposer befinden sich die GPU sowie der HBM2. Welche zukünftigen Möglichkeit NVIDIA hier hat, haben wir ebenfalls bereits analysiert, denn dank eines Spacers ist auch der Einsatz von HBM2 mit doppelter Kapazität denkbar.
[h3]Die Pascal-Architektur[/h3]
Weiterhin ein zentraler Bestandteil der Architektur sind die Streaming Multiprocessors (SM), die NVIDIA allerdings stark umgebaut hat, um eine höhere Effizient zu erreichen. Der Aufbau sieht Graphics Processing Clusters (GPCs), Streaming Multiprocessors (SMs), Thread Processing Cluster (TPCs) und Speichercontroller vor, die in einem bestimmten System organisiert sind.
GP100 besteht aus sechs GPCs, die über jeweils 10 SMs verfügen. Diese wiederum besitzen jeweils 64 Shadereinheiten. Jeweils zwei SMs sind zu einem TPC zusammengefasst. Darin ist unter anderem die PolyMorph-Engine-2.0 untergebracht. Damit kommt GP100 auf insgesamt 3.840 Shadereinheiten (6x10x64). Dies gilt allerdings nur für den Vollausbau von GP100, denn auf der Tesla P100 kommen nur 56 SMs zum Einsatz, was wiederum in 3.584 Shadereinheiten resultiert. Acht Speichercontroller sind um die GPCs organisiert und haben ein 512 Bit breites Speicherinterface. Insgesamt bindet die GP100-GPU den HBM2 also mit 4.096 Bit an. Neben den 64 Shadereinheiten befinden sich in jedem SM auch noch vier Textureinheiten, so dass wir hier insgesamt auf 244 Textureinheiten kommen.
| Die technischen Daten der GP100-GPU im Vergleich | |||
|---|---|---|---|
| GPU | GP100 | GM200 | GK110 |
| Grafikkarten-Modell | Tesla P100 | Tesla M40 | Tesla K40 |
| Fertigung | 16 nm FinFET | 28 nm | 28 nm |
| Transistoren | 15,3 Milliarden | 8 Milliarden | 7,1 Milliarden |
| Chipfläche | 610 mm2 | 601 mm2 | 551 mm2 |
| SMs | 56 (60 im Vollausbau) | 24 | 15 |
| TPCs | 28 (30 im Vollausbau) | 24 | 15 |
| FP32-Recheneinheiten | 3.584 (3.840 im Vollausbau) | 3.072 | 2.880 |
| FP64-Recheneinheiten | 1.792 (1.920 im Vollausbau) | 96 | 960 |
| FP32-Recheneinheiten / SM | 64 | 128 | 192 |
| FP64-Recheneinheiten / SM | 32 | 4 | 64 |
| GPU-Takt (Basis-Tat) | 1.328 MHz | 948 MHz | 745 MHz |
| GPU-Takt (Boost-Takt) | 1.480 MHz | 1.114 MHz | 875 MHz |
| FP32-Rechenleistung | 10.600 GFLOPS | 6.840 GFLOPS | 5.040 GFLOPS |
| FP64-Rechenleistung | 5.300 GFLOPS | 210 GFLOPS | 1.680 GFLOPS |
| Speichertyp | HBM2 | GDDR5 | GDDR5 |
| Speicherkapazität | 16 GB | 24 GB | 12 GB |
| Speicherinterface | 4.096 Bit | 384 Bit | 384 Bit |
| L2-Cache | 4.096 kB | 3.072 kB | 1.536 kB |
| Register-Größe | 14.336 kB | 6.144 kB | 3.840 kB |
| Register-Größe / SM | 256 kB | 256 kB | 256 kB |
| Textureinheiten | 224 | 192 | 240 |
| TDP | 300 W | 250 W | 235 W |
Mit der Pascal-Architektur hat NVIDIA den Fokus wieder mehr in Richtung der FP64-Leistung gerückt. Dazu hat man die Verhältnisse für die FP64 und FP32-Recheneinheiten zueinander geändert. Während dieses bei der Kepler-Architektur noch bei 1/3 lag und in der vorherigen Maxwell-Architektur 1/32 betrug, sieht NVIDIA für die Pascal-Architektur ein Verhältnis von 1/2 vor. Damit liegt NVIDIA beispielsweise auf Niveau der Hawaii-Architektur von AMD.
Für Deep-Learning-Netzwerke sind Half-Precision-Berechnungen bzw. FP16-Berechnungen besonders wichtig und daher sieht hier NVIDIA auch ein Verhältnis von 1/2 zu den FP32-Berechnungen vor. NVIDIA hat das Handling dieser FP16-Berechnungen geändert, um von den dedizierten FP32-Kernen profitieren zu können. Dazu werden FP16-Berechnungen zusammengelegt, damit sie auf FP32-Kernen ausgeführt werden können. Damit die FP16-Berechnungen zusammengelegt werden können, müssen sie allerdings die gleichen Operationen ausführen. Zum Beispiel können nur zwei Additionen oder zwei Multiplikationen zusammengeführt werden. FP16-Operationen sind für Spielen bzw. dort die Verarbeitung von Texturen wichtig oder aber bei der Analyse von Foto- und Videodaten relevant.

Änderungen gab es nicht nur in der Organisation der Shadereinheiten innerhalb der SMs, TPCs und GPCs, sondern auch bei der Größe der Caches und Register. So verfügt die GP100-GPU über 4.096 kB an L2-Cache, während es zuvor 3.072 bzw. 1.536 kB waren. Entscheidender für die Compute-Rechenleistung ist aber die Größe der Register, die nun insgesamt 14.336 kB beträgt. Die Gesamtkapazität ist hier das eine, wichtig ist aber auch, dass NVIDIA weiterhin 256 kB an Register-Files pro SM bereitstellen kann.
Erstaunlich sind sicherlich die Taktraten der GP100-GPU auf der Tesla P100. Diese gibt NVIDIA mit einem Basis-Takt von 1.328 und einem Boost-Takt von 1.480 MHz an. Natürlich sind durch die kleinere Fertigung höhere Taktraten möglich. Für eine GPU auf einer Tesla-Beschleunigerkarte sind die 1.480 MHz aber doch recht erstaunlich.

In der Folge schauen wir uns den Aufbau einer Streaming Multiprocessors noch einmal etwas genauer an. Bereits angesprochen haben wir die 64 Shadereinheiten pro SM. Dabei handelt es sich um FP32-Recheneinheiten. Maxwell und Kepler hatten 128 bzw. 192 FP32-Rechenheiten pro SM und legten den Fokus daher klar auf die Single-Precision-Performance. Jeder SM in der GP100-GPU ist in zwei Processing Blocks aufgeteilt. Jeder davon hat 32 Shadereinheiten, einen Instruction Buffer, einen Warp Scheduler und zwei Dispatch Units. Während die SMs in Pascal also die Hälfte an Shadereinheiten im Vergleich zu Maxwell tragen, sind die Größe der Register, Warps und Thread Blocks identisch geblieben.
NVIDIA hat auch den Datenpfad bzw. dessen Organisation optimiert. Letztendlich konnte NVIDIA die Die-Fläche reduzieren und auch die Leistungsaufnahme in diesem Bereich ist deutlich geringer. Dies ist einer der Bereiche, der zur Effizienzsteigerung geführt hat. Die neue Scheduler-Architektur sorgt für eine bessere Auslastung der Pipelines und jeder Warp Schedular kann zwei Warp Instructions pro Takt zuteilen.
[h3]Komplizierter Aufbau des GPU-Package[/h3]
Welche Herausforderung das Zusammenbringen von GPU und Speicher auf einem Interposer ist, konnten wir uns schon bei AMD genauer anschauen. Das komplette Packet aus GPU, HBM2 und Interposer befindet sich in einem 55 x 55 mm großen BGA-Package.
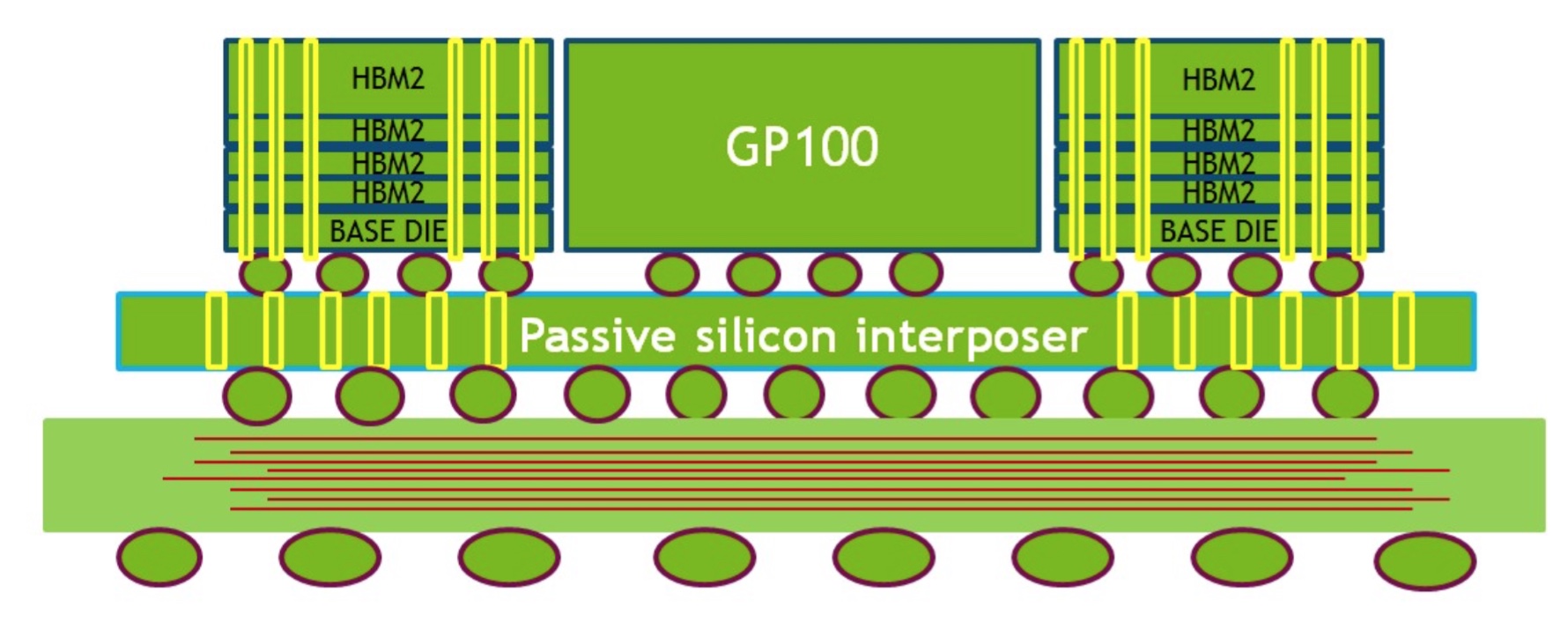
Das obige Bild zeigt das komplette Package mit den BGAs zwischen den unterschiedlichen Schichten. Der passive Interposer dient dabei primär der direkten Verbindung zwischen GPU und HBM2. Hier im Bild zu sehen ist HBM2 mit 4 GB pro Chip. Samsung hat aber bereits angekündigt, auch HBM2 mit 8 GB pro Chip fertigen zu können. NVIDIA sieht einen Spacer vor, um den Höhenunterschied zwischen GPU und den Speicherchips auszugleichen.
Neben der schieren Speicherbandbreite von aktuell 720 GB/s für die Tesla P100 mit GP100-GPU hat NVIDIA aber auch die Kommunikation zwischen GPU und HBM2 optimiert. Dies betrifft vor allem das Handling von Atomic Speicheroperationen. Dabei handelt es sich um Schreib- und Lesezugriffe auf den Speicher. Bereits Kepler sah hier ein großes Optimierungspotenzial vor und mit Fermi machte NVIDIA einen weiteren Schritt zur Implementierung dieser Atomic Speicheroperationen. Mit Maxwell führte NVIDIA die native Hardware-Unterstützung für Shared Memory Atomic Operations in 32 Bit Integer sowie 32- und 64-Bit Compare-and-Swap (CAS) ein. Mit GP100 fügt NVIDIA nun noch FP64 Atomic Adds hinzu. Bei vorherigen Architekturen musste dies noch durch Compare-and-Swap Loop durchgeführt werden, was natürlich nicht so schnell sein konnte wie eine native Lösung.
Das Whitepaper von NVIDIA deckt aber noch viele weitere Bereich der Architektur ab, auf die wir nicht noch einmal eingehen wollen. Stattdessen verweisen wir noch einmal auf unseren ausführlichen Artikel zur Pascal-Architektur, der auch die Themen NVLink, Unified Memory und einige weitere Punkte umfasst.
