
Werbung
Auf der Keynote der Computex 2024 gab AMD einen Ausblick die kommenden EPYC-Prozessoren auf Basis der Zen-5-Architektur. Im Rahmen der Präsentation wollte AMD auch einen Ausblick auf die Leistung im Vergleich zu den aktuellen Intel-Prozessoren geben und veröffentlichte ein paar Diagramme, die den Anschein machen sollten, dass AMD seinem Konkurrenten um den Faktor 2,5 bis 5,4 voraus ist.
Aber wie immer bei solchen Benchmarks, die direkt vom Hersteller kommen, mahnen wir zur Vorsicht. Zwar wählen die Hersteller hin und wieder auch faire Vergleiche, aber man sollte immer genau in die Fußnoten schauen. Vor allem im Datacenter-Segment kommt es inzwischen aber stark auf die verwendete Software an. Sowohl bei den Prozessoren wie auch HPC/AI-Beschleunigern gibt es häufig aber auch einen optimierten Software-Stack. Wer Hardware von AMD einsetzt, verwendet auch die dafür optimierte Software und umgekehrt dürfte dies bei Intel- oder NVIDIA-Hardware genauso sein.
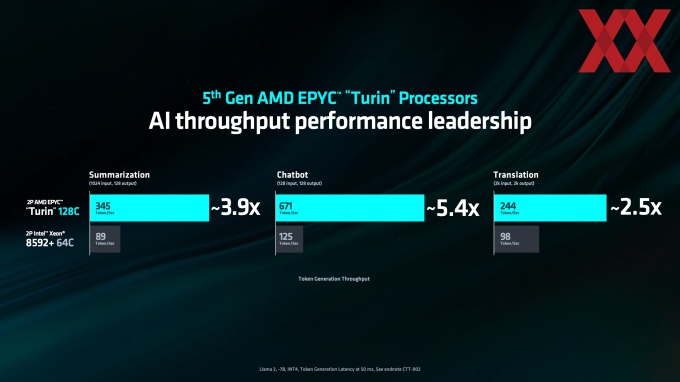
Genau diesen Punkt adressiert Intel in einem Blog-Post und geht darin auf die von AMD ermittelten Leistungswerte für den Verwendeten Xeon Platinum 8592+ ein. Laut Intel hat AMD nicht den optimierten Software-Stack verwendet bzw. es ist nicht ganz klar, welche Software überhaupt zum Einsatz gekommen ist.

Für die Xeon-Prozessoren gibt es eine PyTorch-Optimierung namens Intel Extension for PyTorch (IPEX). Kommt diese zum Einsatz, kommen zwei Xeon Platinum 8592+ mit insgesamt 128 Kernen für das Inferencing in INT4 in einer Chatbot-Anwendung auf Basis von Llama2 7B und vorgegebenen Latenzen von 50 ms auf einen Durchsatz von 686 Anfragen, während es ohne den Einsatz der optimierten Software nur 125 Anfragen waren. AMD nennt für zwei seiner Turin-Prozessoren mit insgesamt 256 Kernen einen Wert von 671 Anfragen. Laut Intel wäre er mittels deaktiviertem SNC sogar möglich gewesen etwa 740 an Durchsatz zu erreichen.
Einmal mehr wird deutlich, wie wichtig die Software für die unterschiedlichen Workloads ist. Die Situation erinnert an AMDs Veröffentlichung erster Benchmarks zum Instinct-MI300X-Beschleuniger im vergangenen Dezember. Hier sah sich AMD weit vor NVIDIAs H100-Beschleuniger, aber auch hier werte sich NVIDIA und verwies darauf, dass AMD ohne das optimiert TensorRT-LLM Framework getestet habe. Kam dies zum Einsatz, sah sich NVIDIA wieder deutlich vor AMD. Damals konterte AMD abermals (siehe Update in der News) und sah sich in seinen Werten bestätigt.
Was den aktuellen Fall betrifft widerspricht Intel seinem Konkurrenten – konkret für einen der Benchmarks. Aber auch die anderen Anwendungsbereiche, wie die Textzusammenfassungen und Übersetzungen in der LLM-Token-Erzeugung fallen laut Intel deutlich besser aus, wenn optimierte Software zum Einsatz kommt. Allerdings hat man sich offenbar dazu entschieden hierzu keine Grafik anzufertigen. Die Leistung soll um den Faktor 2,3 bzw. 1,2 ansteigen, damit reicht man aber nicht an AMDs Turin heran. Zudem sei an dieser Stelle darauf verwiesen, dass AMDs aktuelle EPYC-Plattform 12 Speicherkanäle zu bieten hat, während Emerald Rapids derer nur acht bietet.
Zudem präsentierte AMD eine typische HPC-Anwendung (NAMD), wo man sich ebenfalls vor Intel sieht. Diesem Werten widerspricht Intel nicht:

AMDs EPYC-Generation Turin wird sich aber wohl nicht nur mit Intels letzter Xeon-Generation Emerald Rapids auseinander müssen, sondern mit den gerade erst vorgestellten Xeon-6-Modellen. Diese sind in einem ersten Schritt aber nur in der kleine E-Kern-Version erhältlich. Im dritten Quartal folgen dann die großen Granite Rapids mit bis zu 128 P-Kernen. Hier bietet dann auch Intels Plattform 12 Speicherkanäle.
Der verwendete Software-Stack, eventuell optimierte Datensätze und die vielen weiteren Umgebungsbedingungen einzuordnen ist nicht ganz einfach. Vieles hängt davon ab, welche Software und welche Datensätze zum Einsatz kommen. Hier werden potentielle Kunden ganz genau hinschauen und eigene Tests durchführen.
Ebenso fragwürdige Ryzen-Vergleiche
Die Keynote zur Computex von AMD war auch für andere Produkte und deren Leistungsvergleiche eher fragwürdig einzuschätzen. So wurden mit dem Ryzen 7 5800XT und Ryzen 9 5900XT zwei neue Prozessoren für den Sockel AM4 vorgestellt und auch hier lieferte AMD ein paar Benchmarks, in denen man sich in Spielen auf Augenhöhe mit dem Core i7-13700K und Core i5-13600KF sah.
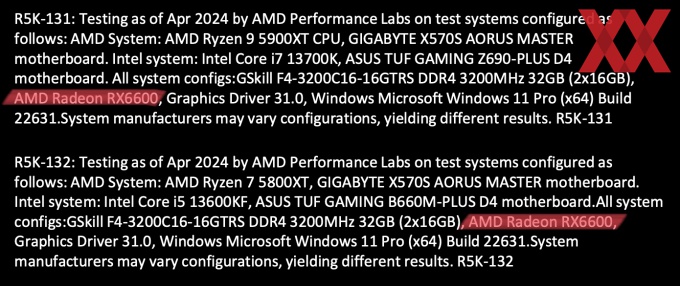
Schaut man aber auch hier in die Fußnoten, dann fällt auf, dass AMD einerseits eine Radeon RX 6600 als Grafikkarte verwendete und man sich so höchstwahrscheinlich im GPU-Limit bewegt hat und andererseits wurde auch für die Intel-Prozessoren DDR4-Speicher verwendet. Wer sich zum aktuellen Zeitpunkt aber ein Intel-System zulegt, wird kaum mehr auf DDR4 setzen.
Der Einfluss der viel zu leistungsschwachen Grafikkarte aber dürfte für den Leistungsvergleich eine wesentlich größere Rolle gespielt haben. Warum AMD sich für eine Radeon RX 6600 entschieden hat, erschließt sich uns nicht. Man kann hier durchaus davon ausgehen, dass dies sehr bewusst geschehen ist, um die Leistungswerte in der gewünschten Form darstellen zu können.
1. Update: Statement von AMD
AMD hat auf die Korrektur seitens Intel reagiert und folgendes zu Protokoll gegeben:
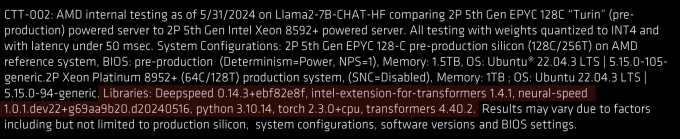
Laut AMD hat man also sehr wohl Software verwendet, die damals den aktuellen Stand widerspiegelte. Gegenteilig spricht AMD davon, dass die von Intel hier in dieser Meldung gezeigte Leistung nur mit einem Software-Stack erreicht werden konnte, der ab dem 7. Juni, also weit nach der Keynote, zur Verfügung stand. Man hat die Keynote-Präsentation um die entsprechenden Fußnoten ergänzt, die nun auch die Informationen über die installierte Software enthalten:
- Deepspeed 0.14.3+ebf82e8f
- intel-extension-for-transformers 1.4.1
- neural-speed 1.0.1.dev22+g69aa9b20.d20240516
- python 3.10.14, torch 2.3.0+cpu
- transformers 4.40.2.
Uns ist es kaum möglich genau zu überprüfen, wer nun recht hat – also ob AMD seinen Konkurrenten Intel mit fairen Mitteln vergleicht oder nicht. Hier steht nun Aussage gegen Aussage.
2. Update: Weitere Erläuterungen
Wir hatten bei AMD noch einmal nachgehakt, denn die Frage war zudem, warum AMD den Kernel 5.15 verwendet, wo doch ab 5.16 die Intel Advanced Matrix Extensions (AMX) unterstützt werden. Die Antwort auf die Unterstützung der AMX-Einheiten für die Xeon-Prozessoren lautet:
- Die Bibliotheken die AMD verwendet hat (ITEX und Neural Speed) unterstützen beide AMX
- auch Intel verwendet den Kernel 5.15 in den eigenen Benchmarks zu den Xeon-Prozessoren der 5. Generation (Emerald Rapids) und verweist dazu auf den Performance Index bei Intel.
Was die Verwendung des Kernel 5.15 in den aktuellen Benchmarks betrifft, so sei dies nur die Version, die AMD im Moment verwende. Da der Kernel so oft aktualisiert würde tue man sein Bestes, diesen zu aktualisieren, wenn man könne.
Das alte Problem bleibt bestehen: Es braucht unabhängige Benchmarks, aufgrund der Komplexität solcher Systeme und der notwendigen Software-Komponenten ist dies aber nicht einfach umzusetzen – auch für uns nicht.
