
Inference
-
MLPerf Inference 4.0: Das Debüt der H200 von NVIDIA gelingt
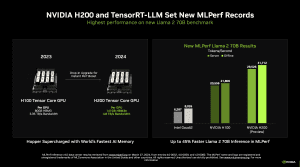 Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr]
Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr] -
Artemis: Meta bringt eigenen Inference-Chip in die Rechenzentren
 Eigentlich bereits für 2022 geplant, hat Meta nun damit begonnen, eine eigene Inferencing-Hardware in den Rechenzentren zu verbauen. Der Artemis getaufte Chip stellt die zweite Generation der Eigenentwicklung dar, die erste Generation MTIA (Meta Training and Inference Accelerator) konnte 2022 die Erwartungen nicht erfüllen. Wie genau Artemis aufgebaut ist, ist nicht bekannt. Zu MTIA wissen wir hingegen, dass Meta einen ASIC mit einer... [mehr]
Eigentlich bereits für 2022 geplant, hat Meta nun damit begonnen, eine eigene Inferencing-Hardware in den Rechenzentren zu verbauen. Der Artemis getaufte Chip stellt die zweite Generation der Eigenentwicklung dar, die erste Generation MTIA (Meta Training and Inference Accelerator) konnte 2022 die Erwartungen nicht erfüllen. Wie genau Artemis aufgebaut ist, ist nicht bekannt. Zu MTIA wissen wir hingegen, dass Meta einen ASIC mit einer... [mehr]
