
P
phlowx
Guest
Am besten postest du mal alle VMDK Dateien, aber der Logik nach müsste folgendes in den Dateien stehen:
Debian Mailserver-000003.vmdk (Stand 11.05.2015):
Debian Mailserver-000002.vmdk (Stand: 15.11.2014):
Debian Mailserver-000001.vmdk (Stand: 17.08.2014):
Debian Mailserver.vmdk (Stand: ????):
Damit der letzte Snapshot (Debian Mailserver-000003.vmdk) funktioniert, müssen alle anderen Snapshots vorhanden sein (auch die Debian Mailserver.vmdk). In die VM muss "Debian Mailserver-000003.vmdk" eingebunden werden.
Debian Mailserver-000003.vmdk (Stand 11.05.2015):
Code:
...
parentCID=CID von Debian Mailserver-000002.vmdk
parentFileNameHint="Debian Mailserver-000002.vmdk"
...
RW .... VMFSSPARSE "Debian Mailserver-000003-delta.vmdk"Debian Mailserver-000002.vmdk (Stand: 15.11.2014):
Code:
...
parentCID=CID von Debian Mailserver-000001.vmdk
parentFileNameHint="Debian Mailserver-000001vmdk"
...
RW .... VMFSSPARSE "Debian Mailserver-000002-delta.vmdk"Debian Mailserver-000001.vmdk (Stand: 17.08.2014):
Code:
...
parentCID=CID von Debian Mailserver.vmdk
parentFileNameHint="Debian Mailserver.vmdk"
...
RW .... VMFSSPARSE "Debian Mailserver-000001-delta.vmdk"Debian Mailserver.vmdk (Stand: ????):
Code:
...
parentCID=ffffffff
...
RW .... VMFSSPARSE "Debian Mailserver-flat.vmdk"Damit der letzte Snapshot (Debian Mailserver-000003.vmdk) funktioniert, müssen alle anderen Snapshots vorhanden sein (auch die Debian Mailserver.vmdk). In die VM muss "Debian Mailserver-000003.vmdk" eingebunden werden.
") super vielen Dank. Jetzt muss ich dich leider gleich noch mal beanspruchen, da ich die andere VM (Webserver) leider nach wie vor nicht zum fliegen bekomme :-( Anbei mal die Daten dazu:
super vielen Dank. Jetzt muss ich dich leider gleich noch mal beanspruchen, da ich die andere VM (Webserver) leider nach wie vor nicht zum fliegen bekomme :-( Anbei mal die Daten dazu: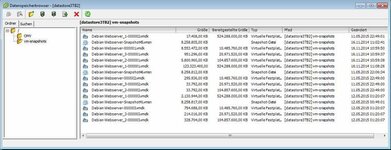




")
