ein paar esp32 hab ich hier noch liegen... hmmm...
kann der m4 seinen ganzen ram als vram nehmen, also wäre der m4 / 64gb fähig llama3.3:70b komplett auf gpu laufen zu lassen ?
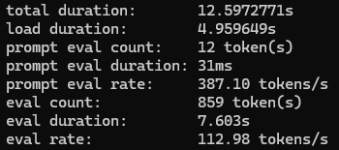
momentan sieht es so aus als könnte ich (wohl aber nicht mit ollama sondern llama.cpp direkt) auf den 10 billigen gpus ~4090 performance aber mit 60gb vram hinbekommen.
eine einzelne P106-90 ist ca. 10%-12% 4090 laut ersten tests hier, also evtl noch schneller ;-)
bin noch am basteln, mal schauen wieviel zeit ich erübrigen kann.
dann hätte ich eine recht günstige und fast brauchbare lösung...
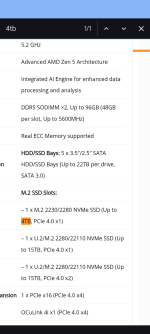
(der server hat 135€ gekostet, die gpus 210€, ok, wir sind im luxx, ich steck nochmal ram rein, server-ecc-ram ist günstig: 2*64gb ~100€)
er ist wohl deutlich lauter wie ein m4, ist halt nen server mit 3*1600W netzteilen für 10 gpus :-(
und er darf nur tagsüber laufen wenn die sonne genug aufs dach scheint, idle=120W ;-)
schon mal ganz grob, aber noch nicht im detail.Hast Du über einen Mac Mini m4 - ggf. als Cluster - nachgedacht?
kann der m4 seinen ganzen ram als vram nehmen, also wäre der m4 / 64gb fähig llama3.3:70b komplett auf gpu laufen zu lassen ?
momentan sieht es so aus als könnte ich (wohl aber nicht mit ollama sondern llama.cpp direkt) auf den 10 billigen gpus ~4090 performance aber mit 60gb vram hinbekommen.
eine einzelne P106-90 ist ca. 10%-12% 4090 laut ersten tests hier, also evtl noch schneller ;-)
bin noch am basteln, mal schauen wieviel zeit ich erübrigen kann.
dann hätte ich eine recht günstige und fast brauchbare lösung...
(der server hat 135€ gekostet, die gpus 210€, ok, wir sind im luxx, ich steck nochmal ram rein, server-ecc-ram ist günstig: 2*64gb ~100€)
er ist wohl deutlich lauter wie ein m4, ist halt nen server mit 3*1600W netzteilen für 10 gpus :-(
und er darf nur tagsüber laufen wenn die sonne genug aufs dach scheint, idle=120W ;-)
Zuletzt bearbeitet: