
corsa630
Neuling
- Mitglied seit
- 26.04.2023
- Beiträge
- 17
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 7800X3D
- Mainboard
- Asrock Taichi B650E
- Kühler
- Phanteks Glacier One T30 Gen2
- Speicher
- Team Group 8000 CL36
- Grafikprozessor
- Asrock Taichi RX 7900XT-X
- Display
- 2x 27GP850P-B, 1x 34GN850P-B
- SSD
- Samsung 990Pro 1TB, Kingston NV1 1TB
- Gehäuse
- O11 Dynamic Evo
- Netzteil
- BeQuiet! Straight Power 11 1000W
- Keyboard
- Logitech G Pro Tastatur
- Mouse
- Logitech G Pro Maus
- Betriebssystem
- Windows 10
- Webbrowser
- Google Chrome
- Sonstiges
- Headset Logitech G Pro X
- Internet
- ▼1000 Mbit ▲50 Mbit
Hallo zusammen,
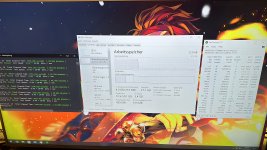
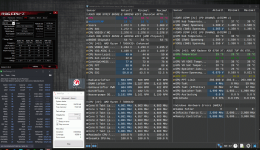
ich bin aktuell ein bisschen am rumprobieren und soweit läuft jetzt 8000 auf dem Taichi bei mir.
Allerdings bin ich was RAM_OC bei Ryzen angeht ein kompletter Neuling und aktuell auf Schnuppertour.
Die meiste performance aus dem Setup mit dem Takt werde ich ja vermutlich bekommen wenn der fclk bei 2000mhz laufen würde seh ich das falsch?
Ich mein die Leistungsunterschiede sollen wohl minimal sein, allerdings möchte das gerne probieren.
Hier ein paar Daten von mir. (Sorry ist nur abfotografiert von gestern Abend beim probieren, war ein spontaner Einfall jetzt hier zu schreiben.)
Falls ihr mehr infos braucht, einfach Bescheid geben, dann mach ich das heute nach der Arbeit.
EDIT: und was hat es mit dem Power Down Mode auf sich?
Danke euch und VG
Nico
ich bin aktuell ein bisschen am rumprobieren und soweit läuft jetzt 8000 auf dem Taichi bei mir.
Allerdings bin ich was RAM_OC bei Ryzen angeht ein kompletter Neuling und aktuell auf Schnuppertour.
Die meiste performance aus dem Setup mit dem Takt werde ich ja vermutlich bekommen wenn der fclk bei 2000mhz laufen würde seh ich das falsch?
Ich mein die Leistungsunterschiede sollen wohl minimal sein, allerdings möchte das gerne probieren.
Hier ein paar Daten von mir. (Sorry ist nur abfotografiert von gestern Abend beim probieren, war ein spontaner Einfall jetzt hier zu schreiben.)
Falls ihr mehr infos braucht, einfach Bescheid geben, dann mach ich das heute nach der Arbeit.
EDIT: und was hat es mit dem Power Down Mode auf sich?
Danke euch und VG
Nico


")
