Trambahner
Urgestein
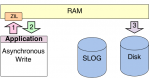
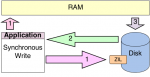
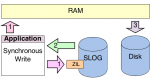
ZFS funktioniert vom Grundsatz mit Spindown. Das Wiederanlaufen sollte halt schnell genug passieren, damit der Pool nicht degraded weil ZFS Platte") als "nicht verfügbar" markiert.
als "nicht verfügbar" markiert.
Z.B. Nas4free (also FreeBSD) kann das out-of-the-Box mit Sata-HBAs+Platten, bei SAS-HBAs braucht man ein Script, da der SAS-Chip+Treiber das nicht selbst veranlasst (auch bei Sata-Platten nicht).
als "nicht verfügbar" markiert.Z.B. Nas4free (also FreeBSD) kann das out-of-the-Box mit Sata-HBAs+Platten, bei SAS-HBAs braucht man ein Script, da der SAS-Chip+Treiber das nicht selbst veranlasst (auch bei Sata-Platten nicht).
Zuletzt bearbeitet:








")
")