
Werbung

Bereits erwähnt haben wir die Einführung einer neuen GPU-Architektur mit der Radeon-HD-7000-Serie. Die Entwicklung zur „Graphics-Core-Next“-Architektur (GCN) hat bereits vor fünf Jahren, kurz nach dem Launch der R600-GPU, die auf der Radeon-HD-2000 und 3000-Serie zum Einsatz kam, begonnen. GNC wird laut Aussage von AMD in den kommenden Jahren die Basis in der GPU-Architektur bilden und löst die alten VLIW4- und VLIW5-Architekturen ab. GCN soll sowohl in High-End-GPUs wie auch in Strom sparenden integrierten Lösungen zum Einsatz kommen. Um die Beweggründe für die Entwicklung von GCN zu verstehen, muss VLIW vielleicht noch einmal erklärt werden.

VLIW steht für „Very Long instruction Word“ und bezeichnet eine Befehlsstruktur, bei der ein sequentieller Programmablauf durch eine Aufteilung in kleinere Instruktionen parallelisiert werden kann. Dazu ist es aber nötig, dass der Compiler diese parallelisierbaren Instruktionen in eine bestimmte Gruppengröße zerlegt und später wieder zusammenfasst. Diese Aufteilung wird innerhalb der Hardware durchgeführt, erfolgt allerdings in der Praxis nicht immer ideal, sodass es zu Leerinstruktionen kommen kann. Diese versuchte AMD mit dem Wechsel von VLIW5 (Radeon-HD-6800-Serie) auf VLIW4 (Radeon-HD-6900-Serie) zu reduzieren, doch war bereits damals klar, dass eine effiziente Nutzung dieser Architektur zukünftig nicht mehr möglich sein wird. Zudem ist die VLIW-Architektur nicht weit genug auf das GPU-Computing ausgelegt - ein Bereich, der für AMD und NVIDIA sehr wichtig geworden ist. Grund hierfür ist die Tatsache, dass die Daten durch mehrere Stufen hindurchgeführt werden mussten, was zur Verzögerungen und Konflikten in den Registern (Caches, etc.) geführt hat.
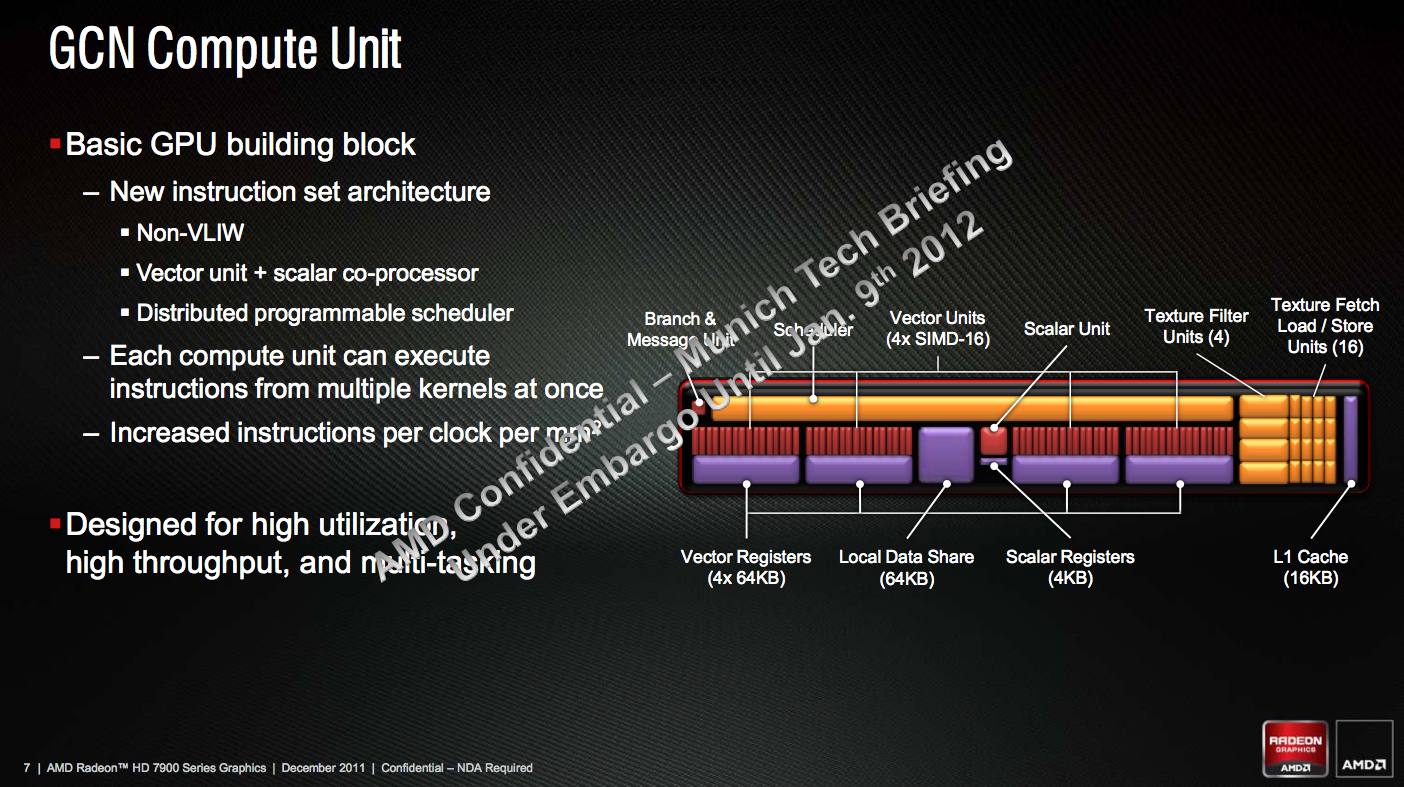
GNC verfolgt einen völlig anderen Ansatz. Die kleinste Einheit innerhalb der GCN-Architektur bildet die „Compute Unit“ (CU). Jede CU wiederum besteht auf vier Vektor-Prozessoren. Diese Vektor-Prozessoren bauen sich aus vier SIMDs (Single instruction, multiple data) zusammen, die jeweils 16 ALUs beinhalten. Aus diesen Zusammenhängen lassen sich nun die 2048 Shader-Prozessoren der Radeon HD 7970 (32 CUs x 4 SIMDs x 16 ALUs) ableiten.
Für die vier Vektor-Prozessoren innerhalb einer CU stehen viermal 64 kB Vektor-Register zur Verfügung. Hinzu kommen 64 kB Local-Data-Share-Cache, was der doppelten Menge gegenüber der alten Architektur entspricht. Dieser Cache ist in der Mitte zwischen den Vektor-Prozessoren platziert worden, um Latenzen durch die Verbindungen so gering wie möglich zu halten. Ebenfalls pro CU eingesetzt wird eine „Scalar Unit“ mit 4 kB Register. Bei der „Scalar Unit“ handelt es sich um eine Art Co-Prozessor. Ein „Scheduler“ sorgt dafür die Aufgaben gleichmäßig an die 16 SIMDs zu verteilen. Eine zusätzliche „Branche Unit“ kann priorisierte Prozesse an diesem „Scheduler“ vorbei an die Vektor-Prozessoren und damit die SIMDs bringen.

Weiterer wichtiger Bestandteil der GPUs sind die Textureinheiten. Von diesen besitzen die „Tahiti“-GPUs jeweils vier pro CU, sodass die Radeon HD 7970 auf deren 128 kommt. Pro Textureinheit stehen wiederum vier „Textur Fetch Load / Store Units“ bereit, die der übergeordneten Einheit zuarbeiten. Eine weitere Komponente sind die „Render Output Units“ oder „Raster Operations Pipelines“ kurz ROPs. Von diesen besitzen die Karten der Radeon-HD-7900-Serie mit „Tahiti“-GPU pro CU eine. Der erste Cache in der Hierachie ist der L1-Cache der CU mit einer Größe von 16 kB. Er kann Daten mit bis zu 16 GB/Sek. in die CUs laden.

Geht man in der Cache-Hierarchie eine Stufe höher, werden hier für vier CUs 16 kByte „Instruction Cache“ und 32 kB „Scalar Data Cache“ sichtbar. Diese sogenannten „GCN-Quad-SIMDs“ wiederum tauschen ihre Daten über den L2-Cache aus. Der L1-Cache schreibt seine Daten mit 64 Byte pro Takt in den L2-Cache. Der L2-Cache setzt sich aus mehreren Blöcken zusammen und ist im Falle von „Tahiti“ bis zu 786 kB groß. Ein Block ist jeweils über ein 64 Bit breites Interface mit dem Grafikspeicher angebunden. Der Grafikspeicher spielt eine besonders wichtige Rolle bei der Compute-Performance, aber natürlich auch beim alltäglichen Gaming-Einsatz. Über ein 384 Bit breites Speicherinterface kann AMD bis zu 264 GB/Sek. an Daten übertragen, was eine deutliche Steigerung gegenüber dem Vorgänger (bis zu 176 GB/Sek. bei der AMD Radeon HD 6970) und auch der Konkurrenz ist. NVIDIAs GeForce GTX 580 kann aufgrund geringerer GDDR5-Taktraten, bei im Vergleich zur AMD Radeon HD 7970 identischen Speicherinterface, mit maximal 192 GB/Sek. Speicherbandbreite aufwarten.
