
Werbung
Die Einführung zahlreicher Grafik-APIs in den vergangenen Monaten hat gezeigt, dass gerade bei der Softwareschnittstelle zwischen Hard- und Software noch einiges Potenzial vorhanden ist. AMD macht mit Mantle den Anfang, DirectX 12 steht im Sommer mit Windows 10 auf dem Plan, bei OpenGL arbeitet man an Vulkan und Apple brachte den Denkanstoß mit Metal in den mobilen Bereich. Bisher war bei diesen Optimierungen meist nur von den sogenannten Draw Calls die Rede, deren Overhead in den Berechnungen des Prozessors reduziert wurde. Der API Overhead Test als neuer Feature-Test des Futuremark 3DMark zeigte an dieser Hinsicht wieder das Potenzial auf.
Es bedarf also nicht immer neuer Hardware, um deutlich mehr Leistung aus bestehenden Produkten zu kitzeln - so die Botschaft hinter den Erwartungen an DirectX 12. AMD spricht nun erstmals über ein Feature, welches sich eigentlich schon seit Einführung der "Graphics Core Next"-Architektur in den aktuellen GPUs befindet. Die sogenannten Asynchronous Shader sollen die Art und Weise wie Engine, Treiber und Hardware miteinander sprechen und die Aufgaben verteilen, verbessern. Mit dem Launch der ersten Grafikkarten auf Basis der "Hawaii"-GPU sprach AMD aber noch von Verbesserungen beim GPU-Computing für die asynchrone Compute Engines. Jede GPU mit GCN-Architektur verfügt aber diese speziellen Hardware-Einheiten. Was damals noch als ein reines Compute-Feature angesehen wurde, soll nun DirectX 12 bei Spielen auf die Sprünge helfen.

Bei den Betrachtung einer GPU-Architektur erwähnen wir auch immer die einzelnen Funktionsblöcke, deren Funktionsweise und Verwendungszweck. Dabei zeigt sich, dass viele dieser Funktionseinheiten unabhängig voneinander arbeiten können, aufgrund des Rendering-Prozesses aber nicht in der Lage sind, so zu arbeiten, sondern meist linear nur eine sogenannte Queue abgearbeitet wird. Dieses schrittweise Abarbeiten versuchen die in allen Architekturen vorhandenen Scheduler zu optimieren, in dem sie die Aufgaben möglichst gleichmäßig verteilen, dies gelingt allerdings nur bis zu einem gewissen Grad.

Mit DirectX 12 verändert sich die Art und Weise der Zugriffe auf die API durch die Programmierer. Sie haben viel mehr Einfluss auf die Arbeitsschritte, sodass sich bestimmte Arbeitsprozesse besser organisieren lassen. Eine bessere Multi-Thread-Skalierung, Pipelines States und Work Submissions sind dabei die drei wichtigsten Werkzeuge, um den Rendering-Prozess entsprechend zu optimieren. In einer recht frühen Vorstellung von DirectX 12 durch Microsoft sind wir bereits darauf eingegangen.
Obiges Bild stellt die Abarbeitung der verschiedenen Rendering-Prozesse in DirectX 12 dar, während im Bild darüber die Arbeitsweise von DirectX 11 zu sehen ist. Die verkürzte Renderzeit äußert sich natürlich in höheren Frames pro Sekunde und reduziert auch die Latenzen, was in einigen Bereichen wie den VR-Brillen ebenfalls einen positiven Aspekt darstellt.

Nun können Entwickler die Aufgaben nicht beliebig verteilen, sondern müssen sich an gewisse Vorgaben der APIs halten. Moderne Spiele-Engines erlauben dazu eine Aufteilung in vordefinierte Queues, die unabhängig voneinander abgearbeitet werden können. In diesem Beispiel werden die Aufgaben in eine Grafik-, Compute- und Copy-Quere verteilt. Die API, hier DirectX 12, verteilt die Queues auf die zur Verfügung stehenden Ressourcen der GPU.
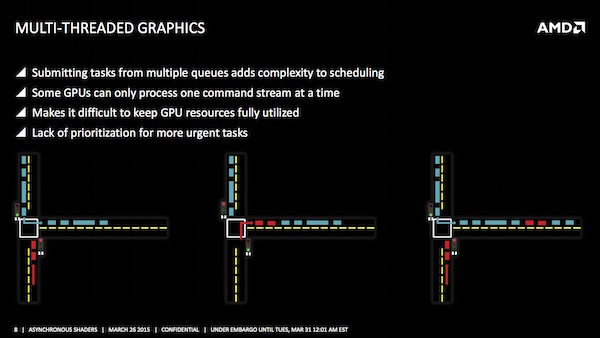
Was im Ansatz einfach klingt, ist in der Praxis aber weitaus komplizierter, denn auch diese verteilten Queues müssen auf die freien Ressourcen der GPU verteilt werden. AMD erklärt einen Rendering-Prozess anhand eines Beispiels aus dem Autoverkehr. Die Kreuzung und Zusammenführung zweier Fahrspuren auf eine mithilfe einer Ampel entspricht dabei der zu bewältigenden Aufgabe. Die Ampel ist dabei der Scheduler, der entscheiden muss, wann welcher Prozess in die Rendering-Pipeline eingeführt wird. Alle Schritte besitzen dabei die gleiche Priorität. Das Warten auf freie Ressourcen sowie das Umschalten benötigen so Zeit, die nicht sinnvoll genutzt wird.

Eine Möglichkeit diesen Prozess zu verbessern, sind die Pre-Emptions. Dabei werden einige Aufgaben priorisiert. Wieder am Beispiel des Autoverkehrs wird die blaue Queue angehalten, der höher priorisierte Prozess (lila) kann dann in den Rendering Prozess eingefügt werden. Allerdings findet auch hier ein Umschalten zwischen den verschiedenen Queues statt und auch die Effizienz wird nicht wesentlich erhöht.

Bei AMD kommen nun die asynchronen Compute Engines (ACE) ins Spiel. Diese mehrfachen Command Queues können gleichzeitig abgearbeitet und daher effizienter in die Rendering-Pipelines zusammengeführt werden. Damit das Beispiel des Autoverkehrs funktioniert, muss man vielleicht noch einfügen, dass es sich um einen getakteten Autoverkehr handelt, bei dem die Fahrzeuge einer bestimmten Reihenfolge und bestimmten Abständen folgen. Arbeiten die Command Queues alle mit dem gleichen Takt, kommt es eventuell zu Kollisionen. Die ACEs sollen dies verhindern, in dem sie die Commands unabhängig von einem Takt in die Queue einfügen. So lassen sich freie Lücken und damit brachliegendes Leistungspotenzial besser nutzen. Weiterhin möglich ist aber auch die Priorisierung bestimmter Prozesse.
