
Werbung
Mit inzwischen weit über 50 Milliarden Transistoren auf einer Fläche von 800+ mm² haben moderne Chips eine Komplexität erreicht, die sich in vielen Phasen der Entwicklung und des Designs durch den Menschen nicht mehr erfassen lässt. EDA-Werkzeuge (Electronic Design Automation) sind die Hilfsmittel der Wahl, die den Prozess eines Designs in die Fertigung überführen sollen. Ziel ist es dabei natürlich die Schaltkreise auf möglichst kleiner Chipfläche unterzubringen, ohne dabei Kompromisse in der Leistung eingehen zu müssen – möglichst automatisch natürlich.
Die Unterstützung von Machine-Learning-Algorithmen hält dabei über den inzwischen üblichen Automatismus hinaus Einzug. Synopsis bietet mit DSO.ai eine entsprechende Lösung an, die den EDA-Prozess um bis zu 26 % verbessern soll (geringerer Stromverbrauch). Auch Google sprach bereits im Frühjahr 2020 davon ein Chip Design with Deep Reinforcement Learning einzusetzen bzw. daran zu forschen. Unternehmen wie Cadence oder Mentor (Siemens) bieten ähnliche Werkzeuge an.
NVIDIA hat nun eine Forschung vorgestellt, die ebenfalls das Reinforcement Learning (RL) anwendet, um bestimmte Schaltkreise in einem Chip automatisiert zu designen. Die H100-GPU auf Basis der Hopper-Architektur verwendet laut NVIDIA 13.000 Instanzen, die auf Basis des RL gestaltet wurden. Vor allem Addierer oder Prioritätskodierer sind solche Schaltkreise, die massenhaft in GPUs verbaut sind und die sich automatisiert deutlich effektiver gestalten lassen.

Das Reinforcement Learning (RL) lernt selbständig, platziert und gestaltet die Schaltkreise immer wieder neu, um nach mehreren Durchläufen das ideale Design zu finden. Neben der Fläche des Schaltkreises spielt auch die Latenz im Design eine entscheidende Rolle – je größer die gewährte Fläche, desto höher sind auch die Latenzen durch die Länge der Verschaltungen.
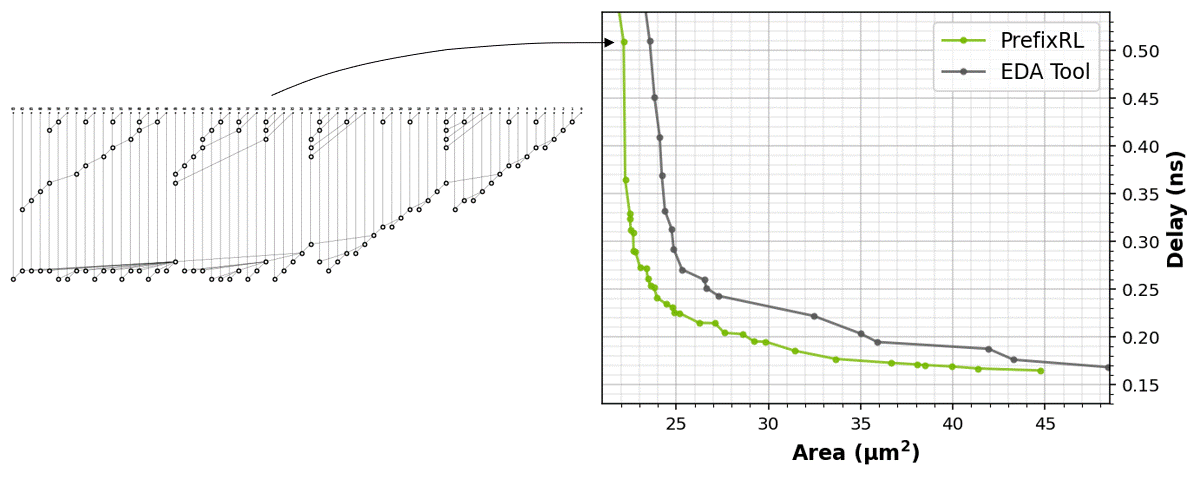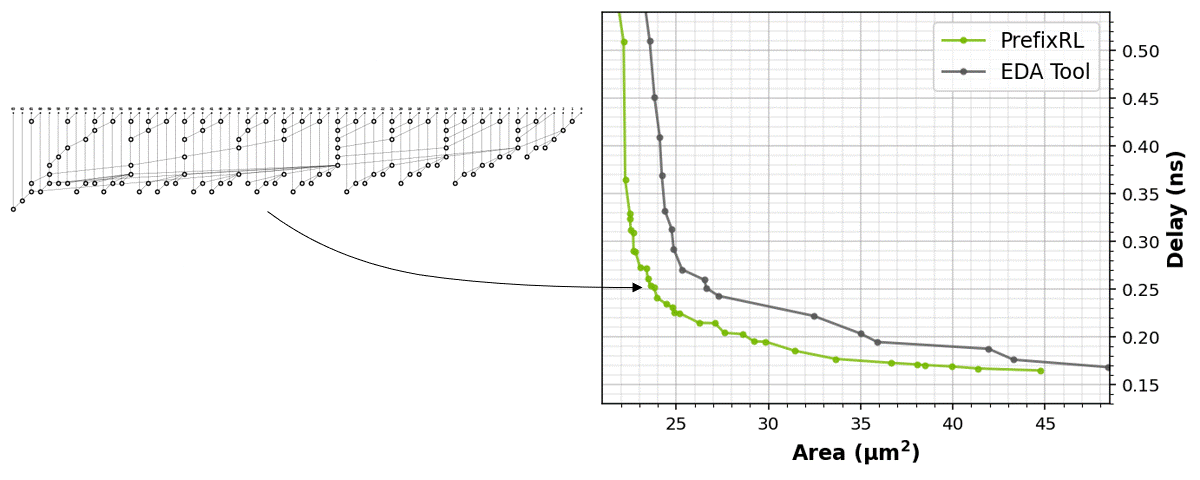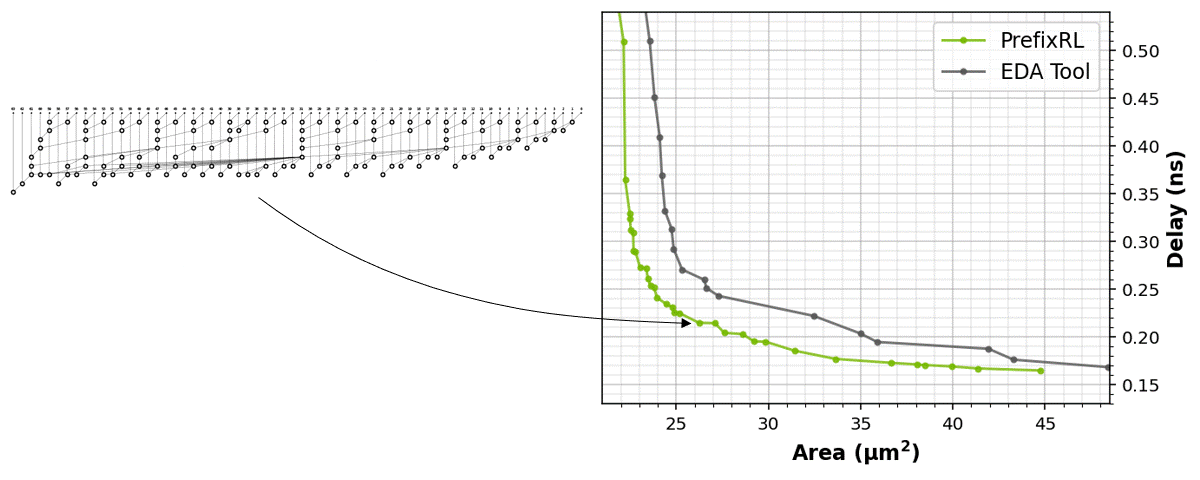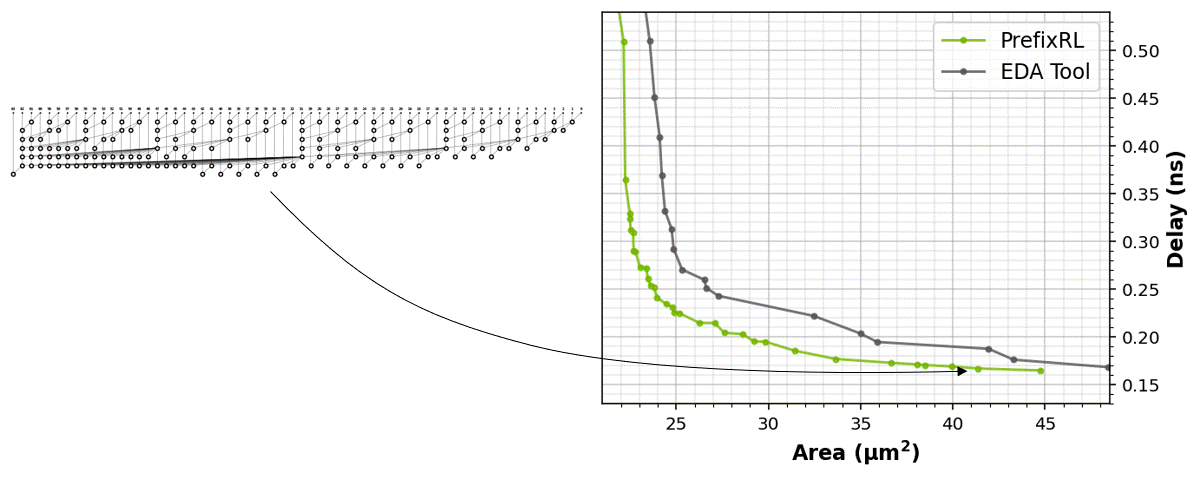
NVIDIA vergleicht hier eine durch das PrefixRL und typische EDA-Tools erstellte Schaltungen miteinander und sieht PrefixRL in allen Bereichen der Leistungskurve (Fläche zu Latenz, siehe Animation) im Vorteil. Ein 64-Bit-Addierer ist im Arbeitsbereich von 31,4 µm² zu 0,186 ns um 25 % kleiner (siehe Bild oben).
Natürlich legt NVIDIA hier nicht alle Karten auf den Tisch, aber noch einmal: Bei 50 Milliarden Transistoren und mehr (Die H100-GPU kommt sogar auf 80 Milliarden) und Multi-Chip-Designs von mehr als 100 Milliarden Transistoren dürfte klar sein, dass die Schaltungen hier nicht mehr alle manuell erstellt werden. Automatische Design-Werkzeuge gibt es natürlich bereits seit Jahren, allerdings kann ab einer gewissen Komplexität viel Platz eingespart werden, wenn diese Werkzeuge sich selbst optimieren.
Allerdings verlangen solche Werkzeuge in einem ersten Schritt auch einen gewissen Mehraufwand. Das Training des PrefixRL benötigt für einen 64-Bit-Addierer etwa 32.000 GPU-Stunden.
