
H100
-
Einblicke in Colossus KI-Supercomputer: NVIDIA und xAI loben gegenseitig Zusammenarbeit
 Diese Sommer stellte xAI den aktuell wohl größten KI-Supercomputer namens Colossus fertig. Mit 100.000 H100-Beschleunigern bestückt stellt eine solche Installation gigantische Voraussetzungen an alle beteiligten Infrastruktur-Komponenten – über die Stromversorgung im Bereich von 155 MW, die Kühlung und auch im Hinblick auf die Netzwerk-Infrastruktur. Aktuell arbeitet xAI sogar schon an einem Ausbau. Doppelt so viele, satte 200.000 Beschleuniger... [mehr]
Diese Sommer stellte xAI den aktuell wohl größten KI-Supercomputer namens Colossus fertig. Mit 100.000 H100-Beschleunigern bestückt stellt eine solche Installation gigantische Voraussetzungen an alle beteiligten Infrastruktur-Komponenten – über die Stromversorgung im Bereich von 155 MW, die Kühlung und auch im Hinblick auf die Netzwerk-Infrastruktur. Aktuell arbeitet xAI sogar schon an einem Ausbau. Doppelt so viele, satte 200.000 Beschleuniger... [mehr] -
100.000 H100-GPUs: X.AI baut riesiges KI-Cluster mit gewaltigem Stromhunger
 Nach eigenen Angaben hat das X.AI eines der bisher größten KI-Cluster in Betrieb genommen, wobei dies nicht ganz stimmt, denn noch scheint der Ausbau mit 100.000 H100-Beschleuniger von NVIDIA nicht ganz abgeschlossen zu sein, auch wenn X.AI-Chef Elon Musk dies auf X behauptet. Bereits seit geraumer Zeit arbeitet X.AI am Aufbau eines größeren KI-Clusters, welches das aktuelle System mit etwa 20.000 dieser Beschleuniger ablösen soll. X.AI... [mehr]
Nach eigenen Angaben hat das X.AI eines der bisher größten KI-Cluster in Betrieb genommen, wobei dies nicht ganz stimmt, denn noch scheint der Ausbau mit 100.000 H100-Beschleuniger von NVIDIA nicht ganz abgeschlossen zu sein, auch wenn X.AI-Chef Elon Musk dies auf X behauptet. Bereits seit geraumer Zeit arbeitet X.AI am Aufbau eines größeren KI-Clusters, welches das aktuelle System mit etwa 20.000 dieser Beschleuniger ablösen soll. X.AI... [mehr] -
Deal mit Oracle geplatzt: Musk plant Supercomputer selbst zu bauen
 Elon Musk hat im aktuellen Rennen um das Thema Künstliche Intelligenz den Sprung an die Spitze verpasst. Mit allen Mitteln versucht der Tech-Milliardär, seinen Rückstand wieder aufzuholen. Ein milliardenschwerer Deal zwischen Oracle und dem KI-Start-up xAI von Musk ist nun allerdings geplatzt, weil es dem Milliardär offenbar nicht schnell genug geht. Das Geschäft mit Oracle sollte eine bereits bestehende Abmachung erweitern, bei der Musks... [mehr]
Elon Musk hat im aktuellen Rennen um das Thema Künstliche Intelligenz den Sprung an die Spitze verpasst. Mit allen Mitteln versucht der Tech-Milliardär, seinen Rückstand wieder aufzuholen. Ein milliardenschwerer Deal zwischen Oracle und dem KI-Start-up xAI von Musk ist nun allerdings geplatzt, weil es dem Milliardär offenbar nicht schnell genug geht. Das Geschäft mit Oracle sollte eine bereits bestehende Abmachung erweitern, bei der Musks... [mehr] -
Sohu-ASIC für Transformer-Modelle: Beschleuniger soll 20mal schneller als NVIDIAs H100 sein
 Ein Startup namens Etched hat einen ASIC namens Sohu vorgestellt, der speziell auf das Inferencing von Transformer-Modellen ausgelegt sein soll. Ausgestattet mit 144 GB an HBM3E sowie bereits reservierten Kapazitäten für die Fertigung bei TSMC will das Startup eine Konkurrenz von NVIDIAs Beschleunigern und dabei um ein Vielfaches schneller sein. Transformer-Modelle sind eine Art von neuronalen Netzwerken, die speziell für die Verarbeitung von... [mehr]
Ein Startup namens Etched hat einen ASIC namens Sohu vorgestellt, der speziell auf das Inferencing von Transformer-Modellen ausgelegt sein soll. Ausgestattet mit 144 GB an HBM3E sowie bereits reservierten Kapazitäten für die Fertigung bei TSMC will das Startup eine Konkurrenz von NVIDIAs Beschleunigern und dabei um ein Vielfaches schneller sein. Transformer-Modelle sind eine Art von neuronalen Netzwerken, die speziell für die Verarbeitung von... [mehr] -
Intel Vision 2024: Gaudi 3 soll NVIDIAs H100 und H200 starke Konkurrenz machen
 Zuletzt präsentierte sich Intel mit seinem Gaudi-2-Beschleuniger als preisliche und vor allem verfügbare Alternative zu NVIDIAs allgegenwärtigen KI-Beschleunigern. Geht es jedoch um die Rohleistung, so dürfte kaum ein Weg an NVIDIA vorbeiführen und am schnellen Markt der KI-Beschleuniger wirkt Intels Lösung schon recht überholt – ohne dabei überhaupt auf AMDs Instinct MI300X/A einzugehen, die sich hinsichtlich ihrer Leistung zwischen NVIDIA und... [mehr]
Zuletzt präsentierte sich Intel mit seinem Gaudi-2-Beschleuniger als preisliche und vor allem verfügbare Alternative zu NVIDIAs allgegenwärtigen KI-Beschleunigern. Geht es jedoch um die Rohleistung, so dürfte kaum ein Weg an NVIDIA vorbeiführen und am schnellen Markt der KI-Beschleuniger wirkt Intels Lösung schon recht überholt – ohne dabei überhaupt auf AMDs Instinct MI300X/A einzugehen, die sich hinsichtlich ihrer Leistung zwischen NVIDIA und... [mehr] -
MLPerf Inference 4.0: Das Debüt der H200 von NVIDIA gelingt
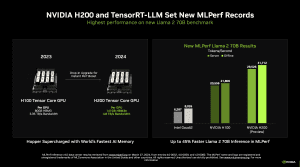 Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr]
Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr] -
Zweimal 24.576 H100: Meta erklärt zwei seiner AI-Cluster
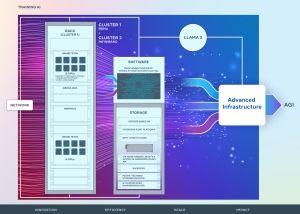 In seinem Engineering-Blog erklärt Meta, wie man seine Infrastruktur für AI-Cluster aufbaut, betreibt und optimiert. Meta verwendet KI-Systeme in fast all seinen Services. Das letztendliche Ziel ist eine allgemeine künstliche Intelligenz (AGI), die nicht mehr auf eine spezielle Aufgabe ausgelegt ist, sondern über alle Bereiche hinweg arbeiten kann. Für das Training seiner Large Language Models (LLMs) verwendet Meta große Cluster mit jeweils... [mehr]
In seinem Engineering-Blog erklärt Meta, wie man seine Infrastruktur für AI-Cluster aufbaut, betreibt und optimiert. Meta verwendet KI-Systeme in fast all seinen Services. Das letztendliche Ziel ist eine allgemeine künstliche Intelligenz (AGI), die nicht mehr auf eine spezielle Aufgabe ausgelegt ist, sondern über alle Bereiche hinweg arbeiten kann. Für das Training seiner Large Language Models (LLMs) verwendet Meta große Cluster mit jeweils... [mehr] -
Dell zu NVIDIAs KI-Beschleunigern: B200 und bis zu 1.000 W pro Chip
 Im Rahmen der Bekanntgabe der Quartalszahlen (PDF) hat Dells Chief Operating Officer Jeff Clarke einige interessante Aussagen zu zukünftigen KI-Beschleunigern von NVIDIA gemacht. Diese passen ganz gut in das, was NVIDIA höchstselbst Mitte Oktober veröffentlicht hat. Die Kadenz zwischen den einzelnen Beschleuniger-Generationen wird sich erhöhen, teilweise sprechen wir nicht von komplett neuen Chips, sondern beispielsweise von einem Update auf... [mehr]
Im Rahmen der Bekanntgabe der Quartalszahlen (PDF) hat Dells Chief Operating Officer Jeff Clarke einige interessante Aussagen zu zukünftigen KI-Beschleunigern von NVIDIA gemacht. Diese passen ganz gut in das, was NVIDIA höchstselbst Mitte Oktober veröffentlicht hat. Die Kadenz zwischen den einzelnen Beschleuniger-Generationen wird sich erhöhen, teilweise sprechen wir nicht von komplett neuen Chips, sondern beispielsweise von einem Update auf... [mehr] -
Video: NVIDIA gewährt Einblick in Eos-Supercomputer
 In einem Video gibt NVIDIA einen Einblick in seinen eigenen Supercomputer Eos, der aktuell den neunten Platz unter den schnellsten Systemen belegt. Eos wird von NVIDIA in der Entwicklung neuer KI-Technologien, womöglich auch im Design neuer GPUs und vielem mehr genutzt. Eos kann als eine Art Blaupause für Supercomputer gesehen werden. Er besteht aus 576 NVIDIA-DGX-H100-Servern. Diese wiederum besitzen acht H100-Beschleuniger. Somit kommt Eos... [mehr]
In einem Video gibt NVIDIA einen Einblick in seinen eigenen Supercomputer Eos, der aktuell den neunten Platz unter den schnellsten Systemen belegt. Eos wird von NVIDIA in der Entwicklung neuer KI-Technologien, womöglich auch im Design neuer GPUs und vielem mehr genutzt. Eos kann als eine Art Blaupause für Supercomputer gesehen werden. Er besteht aus 576 NVIDIA-DGX-H100-Servern. Diese wiederum besitzen acht H100-Beschleuniger. Somit kommt Eos... [mehr] -
NVIDIA kontert: H100 soll deutlich schneller als Instinct MI300X sein
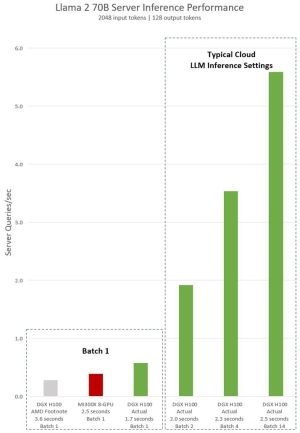 Zusammen mit der Vorstellung der Instinct MI300A und Instinct MI300X präsentierte AMD in der vergangenen Woche auch beeindruckende Leistungsdaten. Laut dieser ist der Instinct-MI300X-Beschleuniger mindestens auf Augenhöhe mit dem H100-Beschleuniger von NVIDIA. Nun aber kontert NVIDIA die von AMD gemachten Aussagen und veröffentlicht in einem Blogpost neue Zahlen, die auch Bezug auf den Instinct-MI300X-Beschleuniger nehmen. Was dabei... [mehr]
Zusammen mit der Vorstellung der Instinct MI300A und Instinct MI300X präsentierte AMD in der vergangenen Woche auch beeindruckende Leistungsdaten. Laut dieser ist der Instinct-MI300X-Beschleuniger mindestens auf Augenhöhe mit dem H100-Beschleuniger von NVIDIA. Nun aber kontert NVIDIA die von AMD gemachten Aussagen und veröffentlicht in einem Blogpost neue Zahlen, die auch Bezug auf den Instinct-MI300X-Beschleuniger nehmen. Was dabei... [mehr] -
KI-Chips: Meta und Microsoft planen Großeinkauf von AMDs Instinct MI300X
 Der Hype um artifizieller Intelligenz hat eine enorme Nachfrage nach entsprechender Hardware geschaffen. Vor allem NVIDIA konnte davon bisher in außerordentlichem Umfang profitieren – mit sensationellen Umsatz- und Gewinnzahlen. Aber nicht nur NVIDIA stellt die begehrten Beschleuniger her. Auch AMD bietet mit dem Instinct MI300X ein konkurrierendes Produkte an. Microsoft hat sich nun dazu entschlossen, an AMD eine großen Auftrag zu vergeben und... [mehr]
Der Hype um artifizieller Intelligenz hat eine enorme Nachfrage nach entsprechender Hardware geschaffen. Vor allem NVIDIA konnte davon bisher in außerordentlichem Umfang profitieren – mit sensationellen Umsatz- und Gewinnzahlen. Aber nicht nur NVIDIA stellt die begehrten Beschleuniger her. Auch AMD bietet mit dem Instinct MI300X ein konkurrierendes Produkte an. Microsoft hat sich nun dazu entschlossen, an AMD eine großen Auftrag zu vergeben und... [mehr] -
Top500 Supercomputer: Intel und NVIDIA bringen Schwung in die Top 10
 Im Rahmen der Supercomputing 2023 wurde die Liste der Top500-Systeme aktualisiert. Hier gab es erstmals seit Jahren große Verschiebungen in den Top 10, wenngleich die Spitzenposition unverändert bleibt. Prozessoren von Intel, kombiniert mit eigenen GPUs, vor allem aber die H100-Beschleuniger von NVIDIA dominieren die Liste. Aurora, die neue Nummer zwei der Supercomputer, steigt mit etwa der Hälfte der installierten Nodes mit einer... [mehr]
Im Rahmen der Supercomputing 2023 wurde die Liste der Top500-Systeme aktualisiert. Hier gab es erstmals seit Jahren große Verschiebungen in den Top 10, wenngleich die Spitzenposition unverändert bleibt. Prozessoren von Intel, kombiniert mit eigenen GPUs, vor allem aber die H100-Beschleuniger von NVIDIA dominieren die Liste. Aurora, die neue Nummer zwei der Supercomputer, steigt mit etwa der Hälfte der installierten Nodes mit einer... [mehr] -
H20, L20 und L2: NVIDIA will mit neuen GPUs die Sanktionen umgehen
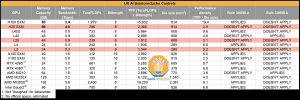 Die immer wieder verschärften US-Handelsrestriktionen sorgen dafür, dass sich Hersteller wie NVIDIA nach alternativen Auslegungen ihrer Produkte umsehen, um nicht von den Beschränkungen betroffen zu sein. Aus einem A100- wurde ein A800-Beschleuniger und der H100- war schlussendlich nur noch als H800-Beschleuniger für China vorgesehen. Ein Limit in der Bandbreite des Interconnects (NVLink) diente den Behörden damals noch als Schranke was... [mehr]
Die immer wieder verschärften US-Handelsrestriktionen sorgen dafür, dass sich Hersteller wie NVIDIA nach alternativen Auslegungen ihrer Produkte umsehen, um nicht von den Beschränkungen betroffen zu sein. Aus einem A100- wurde ein A800-Beschleuniger und der H100- war schlussendlich nur noch als H800-Beschleuniger für China vorgesehen. Ein Limit in der Bandbreite des Interconnects (NVLink) diente den Behörden damals noch als Schranke was... [mehr] -
MLPerf-Benchmarks: NVIDIA mit über 10.000 GPUs, Google TPU-v5e und Gaudi2 mit guten Ergebnissen
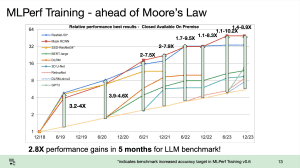 Die MLCommons hat eine weitere Runde Ergebnisse im Bereich Datacenter-Training und HPC vorgestellt. Interessant sind dabei die Trainings-Ergebnisse, denn hier taucht einiges an Hardware erstmals auf bzw. skaliert mit deutlich mehr Beschleunigern, als dies bei den bisherigen Ergebnissen der Fall war. NVIDIA und Azure präsentieren Ergebnisse mit 1.344 Knoten. In seiner Cloud-Instanz setzt Azure dazu pro Knoten auf jeweils zwei Intel Xeon... [mehr]
Die MLCommons hat eine weitere Runde Ergebnisse im Bereich Datacenter-Training und HPC vorgestellt. Interessant sind dabei die Trainings-Ergebnisse, denn hier taucht einiges an Hardware erstmals auf bzw. skaliert mit deutlich mehr Beschleunigern, als dies bei den bisherigen Ergebnissen der Fall war. NVIDIA und Azure präsentieren Ergebnisse mit 1.344 Knoten. In seiner Cloud-Instanz setzt Azure dazu pro Knoten auf jeweils zwei Intel Xeon... [mehr] -
KI-Rechenzentrum auf hoher See: Del Complex will Regulierungsbehörden zuvorkommen
 Die Idee, komplette Rechenzentren zu versenken, bzw. mit Meerwasser zu kühlen ist nicht neu. Microsoft testet dies mit dem Projekt Natick. Das Unternehmen Del Complex will KI-Rechenzentren auf hoher See einsetzen. Die Idee hinter dem BlueSea Frontier Compute Cluster (BSFCC) ist einerseits die Kühlung der Hardware, auf der anderen Seite will man die schwimmenden Pontons auf internationalen Gewässern einsetzen, was Einschränkungen durch... [mehr]
Die Idee, komplette Rechenzentren zu versenken, bzw. mit Meerwasser zu kühlen ist nicht neu. Microsoft testet dies mit dem Projekt Natick. Das Unternehmen Del Complex will KI-Rechenzentren auf hoher See einsetzen. Die Idee hinter dem BlueSea Frontier Compute Cluster (BSFCC) ist einerseits die Kühlung der Hardware, auf der anderen Seite will man die schwimmenden Pontons auf internationalen Gewässern einsetzen, was Einschränkungen durch... [mehr] -
Gaudi2 vor NVIDIA: Ein erster Benchmark zu Granite Rapids
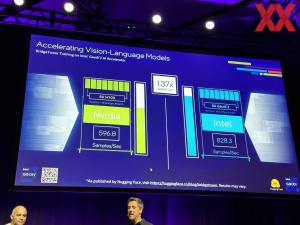 Im Rahmen der Innovation 2023 hat Intel einige interessante Benchmarks veröffentlicht, denn keinesfalls will man sich NVIDIA im Feld der Generative-AI-Anwendungen und Large Language Modelle geschlagen geben. So wurde das Training des BridgeTower Modells von Huggingface demonstriert und dabei traten acht H100-Beschleuniger von NVIDIA gegen ebenfalls acht Gaudi2-Beschleuniger von Intel an. Der Vorteil für Intel soll hier bei 37 % gelegen haben... [mehr].
Im Rahmen der Innovation 2023 hat Intel einige interessante Benchmarks veröffentlicht, denn keinesfalls will man sich NVIDIA im Feld der Generative-AI-Anwendungen und Large Language Modelle geschlagen geben. So wurde das Training des BridgeTower Modells von Huggingface demonstriert und dabei traten acht H100-Beschleuniger von NVIDIA gegen ebenfalls acht Gaudi2-Beschleuniger von Intel an. Der Vorteil für Intel soll hier bei 37 % gelegen haben... [mehr]. -
Mit dem notwendigen Kleingeld: Wasserkühler für NVIDIAs H100-Karte
 NVIDIAs Verkaufsschlager dürften aktuell weniger die GeForce-Karten sein, sondern vielmehr die Datacenter-Beschleuniger der H100-Serie. Comino ist ein Hersteller für Workstations und Server mit aufwändiger Wasserkühlung und entsprechend bietet man diese Wasserkühler einzeln zum Verkauf an. "Klasse statt Masse" soll offenbar das Motto sein. Der Markt für Wasserkühler in diesem Segment dürfte klein sein und entsprechend ist es eine Erwähnung... [mehr]
NVIDIAs Verkaufsschlager dürften aktuell weniger die GeForce-Karten sein, sondern vielmehr die Datacenter-Beschleuniger der H100-Serie. Comino ist ein Hersteller für Workstations und Server mit aufwändiger Wasserkühlung und entsprechend bietet man diese Wasserkühler einzeln zum Verkauf an. "Klasse statt Masse" soll offenbar das Motto sein. Der Markt für Wasserkühler in diesem Segment dürfte klein sein und entsprechend ist es eine Erwähnung... [mehr] -
Inflection AI: Startup baut Supercomputer mit 22.000 H100-GPUs
 Ob Meta, Google, Microsoft oder anderen Cloud-Anbieter – NVIDIA wird sich vor Nachfrage nach den H100-Beschleunigern wohl kaum retten können. In welchen Mengen die Hardware hier an den Mann gebraucht wird, zeigt sich deutlich in einer Ankündigung eines engen Partners von NVIDIA: Dem AI-Startup Inflection AI, welches inzwischen mit 1,5 Milliarden US-Dollar bewertet wird und in das Personen wie Bill Gates und Eric Schmidt sowie eben NVIDIA... [mehr]
Ob Meta, Google, Microsoft oder anderen Cloud-Anbieter – NVIDIA wird sich vor Nachfrage nach den H100-Beschleunigern wohl kaum retten können. In welchen Mengen die Hardware hier an den Mann gebraucht wird, zeigt sich deutlich in einer Ankündigung eines engen Partners von NVIDIA: Dem AI-Startup Inflection AI, welches inzwischen mit 1,5 Milliarden US-Dollar bewertet wird und in das Personen wie Bill Gates und Eric Schmidt sowie eben NVIDIA... [mehr] -
MLPerf Training 3.0: Mehr Gaudi und vor allem mehr H100
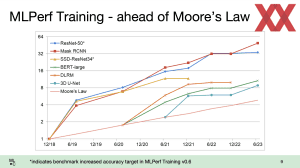 Die ML Commons haben neue Ergebnisse der MLPerf-Training-Benchmarks veröffentlicht. Im Trainingsbereich gibt es einen Versionssprung auf die Version 3.0 inklusive neuer LLM-Benchmarks. Auch die im Edge-Segment wichtigen Tiny-Benchmarks, die auf ein besonders energieeffizientes Inferencing ausgelegt sind, wurden aktualisiert. Die Benchmarksergebnisse sind für eine eventuelle Auswertung direkt bei der ML Commons verfügbar (MLPerf Training... [mehr]
Die ML Commons haben neue Ergebnisse der MLPerf-Training-Benchmarks veröffentlicht. Im Trainingsbereich gibt es einen Versionssprung auf die Version 3.0 inklusive neuer LLM-Benchmarks. Auch die im Edge-Segment wichtigen Tiny-Benchmarks, die auf ein besonders energieeffizientes Inferencing ausgelegt sind, wurden aktualisiert. Die Benchmarksergebnisse sind für eine eventuelle Auswertung direkt bei der ML Commons verfügbar (MLPerf Training... [mehr] -
TSMC: Erhöhte Produktion für NVIDIA macht Kapazitätsausbau notwendig
 Entgegen dem Trend waren bis zuletzt in den Auftragsbüchern von TSMC kaum Auftragslücken zu finden. Das Unternehmen ist derzeit noch gut ausgelastet und der derzeitige Boom von Künstlicher Intelligenz und High-Performance-Computing lässt sogar die Kapazitäten von TSMC an ihre Grenzen kommen. Die Nachfrage nach fortschrittlichen Prozesstechnologien führender Chiphersteller – allen voran nach Grafikprozessoren wie dem A100 und dem H100 von... [mehr]
Entgegen dem Trend waren bis zuletzt in den Auftragsbüchern von TSMC kaum Auftragslücken zu finden. Das Unternehmen ist derzeit noch gut ausgelastet und der derzeitige Boom von Künstlicher Intelligenz und High-Performance-Computing lässt sogar die Kapazitäten von TSMC an ihre Grenzen kommen. Die Nachfrage nach fortschrittlichen Prozesstechnologien führender Chiphersteller – allen voran nach Grafikprozessoren wie dem A100 und dem H100 von... [mehr] -
A3 Supercomputer: Google verwendet 26.000 H100-GPUs
Auf der Google I/O hat der Suchmaschinen-Gigant nicht nur ein erstes faltbares Pixel-Smartphone, neue Mittelklasse-Geräte sowie ein Tablet vorgestellt, sondern außerdem ein paar Details zu seiner AI-Hardware verraten, welche für die eigenen Suchmaschine zum Einsatz kommen soll. Das Compute Engine A3 getaufte System ist nicht ein einzelner Supercomputer, der sich in einem der vielen Rechenzentren von Google befindet. Es handelt sich vielmehr um... [mehr] -
H100 NVL: Weitere Hopper-GPU mit mehr HBM3-Speicher
 Der aktuelle AI-Trend rund um GPT-4 dürfte vor allem die Unternehmen freuen, die Hard- oder Software dazu anbieten. NVIDIA ist einer der Hardwarehersteller hinter den Systemen des Large Language Modells (LLM). Noch laufen die Systeme größtenteils auf Beschleuniger der A100-Serie – zumindest alles, was GPT-4 bei OpenAI, bzw. Microsoft umfasst. Aber die noch einmal leistungsstärkeren H100-Beschleuniger kommen zunehmend zum Einsatz und... [mehr]
Der aktuelle AI-Trend rund um GPT-4 dürfte vor allem die Unternehmen freuen, die Hard- oder Software dazu anbieten. NVIDIA ist einer der Hardwarehersteller hinter den Systemen des Large Language Modells (LLM). Noch laufen die Systeme größtenteils auf Beschleuniger der A100-Serie – zumindest alles, was GPT-4 bei OpenAI, bzw. Microsoft umfasst. Aber die noch einmal leistungsstärkeren H100-Beschleuniger kommen zunehmend zum Einsatz und... [mehr] -
MLPerf Inference 2.1: H100 mit erstem Auftritt und mehr Diversität
 Es gibt eine neue Runde unabhängiger, bzw. gegenseitig geprüfter Benchmark-Ergebnisse aus dem Server-Bereich. Genauer gesagt geht es um die Inferencing-Ergebnisse in der Version 2.1. Diese sollen eine unabhängige Beurteilung der Server-Systeme in den verschiedenen Anwendungsbereichen ermöglichen. Große Unternehmen werden natürlich weiterhin eine eigene Evaluierung vornehmen, aber in der Außendarstellung konnten die Hersteller meist nur mit... [mehr]
Es gibt eine neue Runde unabhängiger, bzw. gegenseitig geprüfter Benchmark-Ergebnisse aus dem Server-Bereich. Genauer gesagt geht es um die Inferencing-Ergebnisse in der Version 2.1. Diese sollen eine unabhängige Beurteilung der Server-Systeme in den verschiedenen Anwendungsbereichen ermöglichen. Große Unternehmen werden natürlich weiterhin eine eigene Evaluierung vornehmen, aber in der Außendarstellung konnten die Hersteller meist nur mit... [mehr] -
AMD und NVIDIA dürfen GPU-Beschleuniger nicht mehr nach China exportieren
Von der US-Regierung sind neue Einschränkungen für den Handel mit China erlassen worden – dies berichtet Reuters unter Berufung auf Unternehmenskreise bei NVIDIA. Da die Export-Beschränkungen allerdings eine ganze Produktgruppe betreffen, ist von auszugehen, dass auch andere Hersteller ihre Produkte nicht mehr nach China exportieren dürfen. Dies beträfe dann sogar AMD und Intel. Betroffen seien aber nicht sämtliche GPU-Beschleuniger,... [mehr] -
Neue Tensor Cores, FP8 und mehr Takt: NVIDIAs Verbesserungen der GH100-GPU
 Zur GPU Technology Conference im Frühjahr stellte NVIDIA die GH100-GPU auf Basis der Hopper-Architektur, bzw. den H100-Beschleuniger vor. Zur Hotchips 34 sprach NVIDIA über die Herausforderungen eines solches Designs und wie eine GPU mit 16.896 FP32-Recheneinheiten, 528 Tensor Cores, 50 MB an L2-Cache und 80 GB an HBM3 auszulasten ist – ganz zu schweigen davon, mehrere hundert oder gar tausend GPUs zusammenarbeiten zu lassen. Die... [mehr]
Zur GPU Technology Conference im Frühjahr stellte NVIDIA die GH100-GPU auf Basis der Hopper-Architektur, bzw. den H100-Beschleuniger vor. Zur Hotchips 34 sprach NVIDIA über die Herausforderungen eines solches Designs und wie eine GPU mit 16.896 FP32-Recheneinheiten, 528 Tensor Cores, 50 MB an L2-Cache und 80 GB an HBM3 auszulasten ist – ganz zu schweigen davon, mehrere hundert oder gar tausend GPUs zusammenarbeiten zu lassen. Die... [mehr] -
H100-GPU: NVIDIA spart Zeit und Platz durch AI-gestütztes Chip-Design
 Mit inzwischen weit über 50 Milliarden Transistoren auf einer Fläche von 800+ mm² haben moderne Chips eine Komplexität erreicht, die sich in vielen Phasen der Entwicklung und des Designs durch den Menschen nicht mehr erfassen lässt. EDA-Werkzeuge (Electronic Design Automation) sind die Hilfsmittel der Wahl, die den Prozess eines Designs in die Fertigung überführen sollen. Ziel ist es dabei natürlich die Schaltkreise auf möglichst... [mehr]
Mit inzwischen weit über 50 Milliarden Transistoren auf einer Fläche von 800+ mm² haben moderne Chips eine Komplexität erreicht, die sich in vielen Phasen der Entwicklung und des Designs durch den Menschen nicht mehr erfassen lässt. EDA-Werkzeuge (Electronic Design Automation) sind die Hilfsmittel der Wahl, die den Prozess eines Designs in die Fertigung überführen sollen. Ziel ist es dabei natürlich die Schaltkreise auf möglichst... [mehr] -
SK hynix liefert ersten HBM3 an NVIDIA
Bereits bekannt ist, dass NVIDIA für seinen H100-Beschleuniger auf Basis der Hopper-Architektur HBM3-Speicher verwenden will. Nun hat SK hynix bestätigt, dass der Speicher vom südkoreanischen Hersteller stammen wird und dass man gemeinsam mit NVIDIA die Validierung abgeschlossen habe. Ab dem dritten Quartal 2022 sollen die ersten H100-Beschleuniger ausgeliefert werden. Dies deckt sich mit den Ankündigungen von NVIDIA. "NVIDIA has recently... [mehr] -
NVIDIA: Referenzdesigns für HGX Grace (Hopper) und wassergekühlte A100- und H100-Karten
 Zur Computex 2022 stellt NVIDIA, genauer gesagt die Datacenter-Sparte, unter anderem die ersten Referenzdesigns für zukünftige HGX-Systeme vor und will mit wassergekühlten A100- und H100-PCIe-Karten die Effizienz der dazugehörigen Server steigern. Auf der diesjährigen GPU Technology Conference gab NVIDIA weitere Details zum Grace-CPU-Superchip bestehend aus zwei ARM-Chips mit jeweils 72 Kernen und dem Grace-Hopper-Superchip als Kombination aus... [mehr]
Zur Computex 2022 stellt NVIDIA, genauer gesagt die Datacenter-Sparte, unter anderem die ersten Referenzdesigns für zukünftige HGX-Systeme vor und will mit wassergekühlten A100- und H100-PCIe-Karten die Effizienz der dazugehörigen Server steigern. Auf der diesjährigen GPU Technology Conference gab NVIDIA weitere Details zum Grace-CPU-Superchip bestehend aus zwei ARM-Chips mit jeweils 72 Kernen und dem Grace-Hopper-Superchip als Kombination aus... [mehr] -
GH100 abgelichtet: NVIDIAs Hopper-Chip zeigt sich erstmals vor der Kamera
 Auf der GPU Technologies Conference 2022 Mitte März präsentierte NVIDIA die ersten Details zur Hopper-Architektur und dem dazugehörigen GPU-Beschleuniger H100. Patrick Kennedy von ServeTheHome hatte bereits die Gelegenheit, sich das dazugehörige SMX4-Modul genauer anzuschauen. Die GH100-GPU kommt in 4 nm gefertigt auf Abmessungen von 814 mm². Von den sechs sichtbaren HBM3-Chips sind nur fünf aktiv und ermöglichen einen... [mehr]
Auf der GPU Technologies Conference 2022 Mitte März präsentierte NVIDIA die ersten Details zur Hopper-Architektur und dem dazugehörigen GPU-Beschleuniger H100. Patrick Kennedy von ServeTheHome hatte bereits die Gelegenheit, sich das dazugehörige SMX4-Modul genauer anzuschauen. Die GH100-GPU kommt in 4 nm gefertigt auf Abmessungen von 814 mm². Von den sechs sichtbaren HBM3-Chips sind nur fünf aktiv und ermöglichen einen... [mehr]
