
Werbung
Auf der aktuell stattfindenden GPU Technology Conference dominiert vor allem ein Thema: Deep Learning. Weniger ist hingegen über zukünftige Technologien zu hören und dabei interessieren uns natürlich vor allem die GPU-Architekturen. Das Update der Roadmap sprach dabei allerdings nur von einem weiteren Feature namens Mixed Precision. Darüber hinaus wiederholt wurden Ankündigungen zu NVLink und 3D Memory. Neben den Informationen aus der Keynote haben wir alles, was bisher zu diesen neuen Technologien bekannt ist, einmal zusammengefasst. Nicht alle Informationen sind dabei neu, doch in den vergangenen Tagen der Konferenz und auch den letzten Monaten sind einige interessante Details dazu gekommen, die eine Zusammenfassung sinnvoll erscheinen lassen.
[h3]Mixed Precision[/h3]

Mit dem Tegra X1 führt NVIDIA innerhalb des "Maxwell"-GPU-Parts des SoC den "Double Speed FP16"-Support ein. Wie die "Fermi"- und "Kepler"-Architektur zuvor auch, bietet "Maxwell" dedizierte FP32- und FP64-CUDA-Kerne. Dies ist auch beim "Maxwell"-Cluster auf dem Tegra X1 so. Allerdings spielen in diesem Segment FP16-Berechnungen eine wesentlich größere Rolle. NVIDIA hat also das Handling dieser FP16-Berechnungen geändert, um von den dedizierten FP32-Kernen profitieren zu können. Dazu werden FP16-Berechnungen zusammengelegt, damit sie auf FP32-Kernen ausgeführt werden können. Damit die FP16-Berechnungen zusammengelegt werden können, müssen sie allerdings die gleichen Operationen ausführen. Zum Beispiel können nur zwei Additionen oder zwei Multiplikationen zusammengeführt werden. FP16-Operationen sind für die Ausführung von Android ebenso entscheidend wie bei Spielen oder der Analyse von Foto- und Videodaten.

Warum ist das für "Pascal" interessant? Mit "Pascal" wird die Mixed Precision eingeführt. Dabei handelt es sich genau um die Funktion, die den Shadereinheiten im Tegra X1 bereits heute ermöglicht wird. Die Überführung von Technologie der GeForce-GPUs in die Tegra-SoCs erfolgt nun also erstmals auch in der anderen Richtung - also von der Tegra-Hardware in eine kommende GPU-Architektur. Innerhalb von Tegra X1 spielen die zusammenfassbaren FP16-Operationen vor allem im Bereich der Bild- und Video-Analyse eine wichtige Rolle. Auch der Android Display Composer verwendet verstärkt FP16-Operationen, insofern macht ein Fokus auf diese Berechnungen für Tegra X1 Sinn. Warum aber implementiert NVIDIA eine solche Technik in "Pascal"? Bisher sehen die Pläne NVIDIAs für FP16 besonders eine Erhöhung der Compute-Performance vor. NVIDIA selbst spricht von einem Faktor vier gegenüber "Maxwell". Ob auch Spieler davon profitieren können, bliebt abzuwarten.
[h3]NVLInk[/h3]
Wirkliche Neuigkeiten zu NVLink gab es auf der diesjährigen GPU Technology Conference nicht. Bisher hält sich NVIDIA auch im professionellen Umfeld noch stark zurück und so ist allenfalls eine Unterstützung von NVLink in IBM-Prozessoren angedacht. Das Lizenzprogramm für NVLink läuft aber weiter und laut NVIDIA befindet man sich weiterhin in Gesprächen mit zahlreichen Partnern. NVIDIA hat sich zu NVLink bekannt und so werden wir NVLink ab 2016 als Teil der "Pascal"-Architektur sehen. Nun aber zu etwas Hintergrund zu NVLink:
3D bzw. Stacked Memory öffnet den Flaschenhals zwischen GPU und Grafikspeicher, NVLink soll die Verbindung zwischen GPU und CPU sowie GPUs untereinander revolutionieren. Dazu sollte man sich zunächst einmal die Bandbreiten vor Augen führen, die aktuell per PCI-Express bereitgestellt werden. 16 PCI-Express-3.0-Lanes erreichen eine Bandbreite von 15,75 GB pro Sekunde bzw. 128 GT/s. NVIDIA hat bereits in die "Maxwell"-Architektur eine Speicherkomprimierung integriert, welche dem zunehmenden Bedarf an Speicherbandbreite entgegenkommen soll.
Laut NVIDIA soll NVLink fünf bis zwölf mal schneller sein. Die Bandbreite wird demzufolge zwischen 80 und 200 GB pro Sekunde liegen. Bis dahin werden wir vermutlich bereits PCI-Express 4.0 sehen, das die Bandbreite von PCI-Express 3.0 noch einmal verdoppelt und damit auf 31,51 GB pro Sekunde bzw. 256 GT/s kommt.
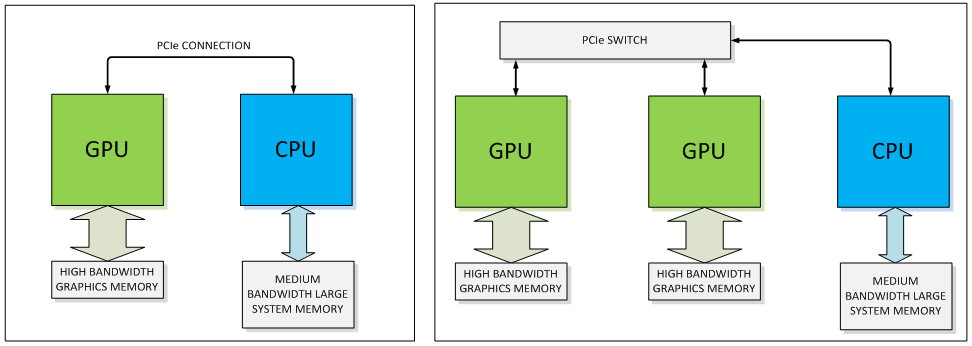
NVIDIA setzt für NVLink eine direkt Punkt-zu-Punkt-Verbindung ein. Diese besteht wiederum aus jeweils acht Lanes pro NVLink-Verbindung. "Pascal" wird zunächst einmal vier NVLinks anbieten können. Laut NVIDIA lässt sich deren Anzahl aber auch abhängig vom gewünschten Zielmarkt anpassen - allerdings wohl zunächst einmal nicht für "Pascal" sondern in Hinblick auf zukünftige GPUs. Die NVLink-Verbindungen können dabei flexibel zusammengefasst, um auch hier wieder dem jeweiligen Anwendungsfall gerecht zu werden. Denkbar ist beispielsweise eine einfache GPU-CPU-Verbindung, aber auch ein Netzwerk aus GPU-CPU- und GPU-GPU-Verbindungen.
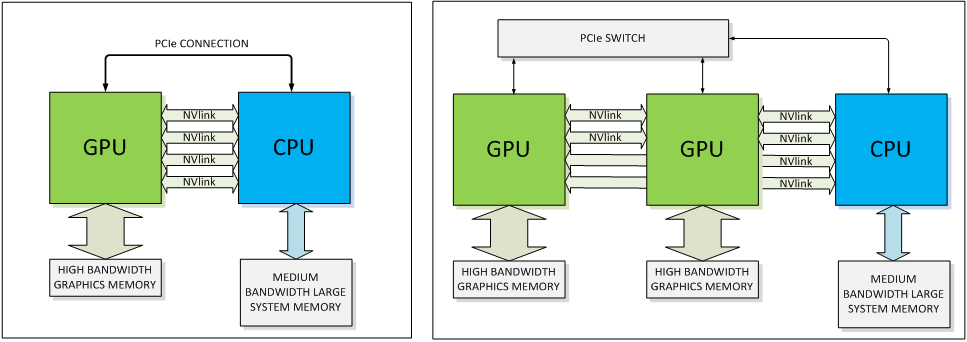
Natürlich muss neben der GPU auch die CPU den Support von NVLink anbieten. Bisher hat nur IBM mit seinen PowerPC-Prozessoren einen Support von NVLink angekündigt. NVIDIA ist laut eigener Aussage aber auch mit Herstellern von ARM-Prozessoren in Gesprächen, um entsprechende Hardware für den Server-Bereich mit dem Release von "Pascal" anbieten zu können. Mit dem eigenen "Projekt Denver" hat man natürlich auch eine CPU-Architektur in der Pipeline, die mit einer Version des Tegra K1 auch schon implementiert wurde. Noch einmal sollte an dieser Stelle betont werden, dass NVLink zunächst einmal nur im professionellen Bereich eine Rolle spielen wird. Für den Desktop wird es eine Version des "Pascal"-Boards geben, das ohne NVLink und mit PCI-Express (dann vermutlich bereits PCI-Express 4.0) daherkommt. NVLink wird im professionellen Umfeld PCI-Express auch nicht vollständig ersetzen. Die bisher über das PCI-Express-Interface übertragenen Kontroll- und Konfigurations-Daten werden weiterhin auch dort verbleiben - NVLink wird sich dann nur um die für die GPU relevanten Daten kümmern.

Soweit etwas Hintergrund zu NVLink in der "Pascal"-GPU. Derzeit hat NVIDIA noch keine konkreten Pläne, wie ein solches "Pascal"-Modul zu einem klassischen Desktop-PC mit seinen ATX-Norman passen soll. Wir sind gespannt, ob es dazu in nächster Zeit noch weitere Informationen gibt oder ob NVIDIA am Ende wieder auf das klassische Design setzt und das "Pascal"-Modul nur ein Schritt in der Entwicklung dorthin war.
[h3]3D Memory[/h3]
NVLink wird im kommenden Jahr mit "Pascal" wohl allenfalls für die Tesla-Karten eine Rolle spielen. PCI-Express wird auf absehbare Zeit für Spieler die Schnittstelle der Wahl bleiben. Wohl den größten Sprung in der Performance wird NVIDIA mit dem Speicher machen. Nicht zufällig fand sich auf der GPU Technology Conference 2015 daher wohl auch ein Stand von SK Hynix, die als heißer Anwärter für die Lieferung von High Bandwidth Memory (HBM) an AMD und NVIDIA gelten. Während die Zusammenarbeit zwischen AMD und SK Hynix als gesichert gilt und schon dieses Jahr ein Erscheinen erster Grafikkarten aus dieser Zusammenarbeit erwartet wird, äußerte sich NVIDIA bisher nicht zu seinem 3D-Memory-Konzept.
Spätestens jetzt sollte klar sein, dass NVIDIA ebenfalls mit SK Hynix zusammenarbeitet und auch zum 3D Memory wollen wir noch ein paar Worte verlieren, welche die Vorteile aufzeigen. NVIDIA wird HBM wie AMD auch im sogenannten 2,5D-Verfahren verwenden. Dies bedeutet, dass der mehrlagige Speicher nicht auf der GPU sitzt, sondern daneben auf dem Substrat aufgebracht wird.

Die Geschwindigkeit eines Speichers wird maßgeblich durch dessen Interface bestimmt. AMD legte bei der "Hawaii"-GPU einen großen Wert darauf und wendete für das 512 Bit breite Interface auch einigen Entwicklungsaufwand und letztendlich auch Die-Fläche auf. Die Interconnects eines Speichers bzw. dessen Anbindung sind also entscheidend. NVIDIA machte bisher keine Anstalten das Speicherinterface auszubauen, jeweils bei 384 Bit war bei "Kepler" und "Maxwell" Schluss. Stattdessen implementierte NVIDIA eine Speicherkomprimierung, welche die eventuell fehlende Speicherbandbreite eventuell auffangen sollte.
HBM verwendet in der ersten und zweiten Generation vier bzw. acht Lagen von Speichermodulen. Diese sind untereinander mit Through Silicon Vias (TSV) verbunden. Mit den beiden HBM-Generationen bzw. den unterschiedlich hohen Stacks an Speicher-Layern hat SK Hynix einige Stellschrauben, an denen gedreht werden kann. Dies lässt den GPU-Herstellern wie AMD und NVIDIA auch einige Auswahlmöglichkeit.
| Vergleich von HBM | ||
|---|---|---|
| Generation | HBM1 | HBM2 |
| Speicherkapazität pro Chip | 2 GB (4 Layer) 4 GB (8 Layer) | 4 GB (4 Layer) 8 GB (8 Layer) |
| Speicherbandbreite | 128 GB/s | 256 GB/s |
| tRC | 48 ns | 48 ns |
| tCCD | 2 ns | 2 ns |
| VDD | 1,2 Volt | 1,2 Volt |
Sowohl bei der Geschwindigkeit als auch der Kapazität wird sich einiges tun. NVIDIA untermauert diese Ansprüche an der eigenen Keynote wie folgt:

Die höhere Speicherkapazität erreicht HBM durch die vier oder acht Layer. Aktuell erreicht GDDR5-Speicher in unterschiedlichen Geschwindigkeiten eine Kapazität von 512 MB pro Chip. HBM der ersten Generation kommt bereits auf 2 bzw. 4 GB. In der zweiten Generation von High Bandwidth Memory von SK Hynix sind es sogar 4 oder 8 GB. Dies vorausgesetzt und das Bild von NVIDIA zum "Pascal"-Modul als Grundlage nehmend kommen wir auf einen Speicherausbau von bis zu 8 GB, was auch ziemlich genau dem in der Keynote zur GTC angegebenen Faktor von 2,7 entspricht. Die GeForce GTX Titan X (Hardwareluxx-Artikel) kommt auf 12 GB x 2,7 ergeben ungefähr 32 GB. NVIDIA wird mit "Pascal" also ziemlich sicher auf einen 8-lagigen HBM der zweiten Generation setzen.

Im Bereich der Speicherbandbreite geht NVIDIA von einem Wachstum um den Faktor drei für "Pascal" im Vergleich zu "Maxwell" aus. Vier Module auf dem "Pascal"-Board kommen bei HBM der ersten Generation auf 512 GB pro Sekunde, bei HBM der zweiten Generation sind es 1.024 GB pro Sekunde. Auch hier kann die GM200-GPU der "Maxwell"-Generation mit einem 384 Bit breiten Speicherinterface als Basis genommen werden und bei dem Faktor drei landen wir auch hier ziemlich genau auf den 1.024 GB pro Sekunde für HBM der zweiten Generation.
Für den Speicherausbau und die Speicherbandbreite von "Pascal" lässt sich also festhalten, dass High Bandwidth Memory der zweiten Generation die Wahl von NVIDIA sein wird. Anders sind die Werte für die wachsende Speicherkapazität und Speicherbandbreite nicht zu erreichen. Einige weitere Details zur HBM der zweiten Generation sind im News-Beitrag zum Stand von SK Hynix auf der GTC 2015 zu finden.
[h3]Ausblick[/h3]
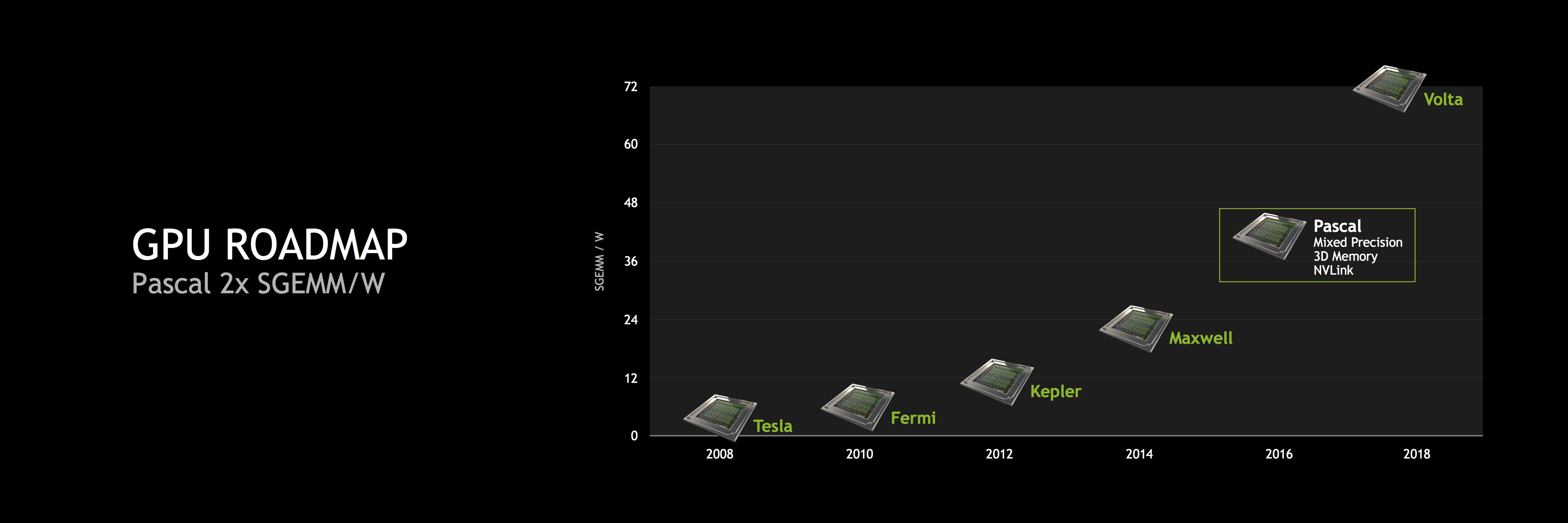
Auf der Keynote der GTC 2015 präsentierte Jen-Hsun Huang zahlreiche Performance-Einschätzungen für "Pacsal". Einige davon bezogen sich auf den Speicher, andere wiederum auf FP16-Rechenoperationen oder die Compute-Performance allgemein. Mit "Maxwell" wurde in der Theorie das Performance/Watt-Verhältnis verdoppelt. Gleiches soll mit "Pascal" gegenüber "Maxwell" erneut gelingen. NVIDIA führt dazu eine Verdopplung von SGEMM pro Watt an. SGEMM beschreibt die Performance einfacher Matrix-Operationen.
NVIDIA ist kein reines Unternehmen für Spiele-Hardware. Das wurde bereits aus den Besuchen der vergangenen GPU Technology Konferenzen ersichtlich. Deutlicher als in diesem Jahr trat es aber wohl selten in Erscheinung. Die GeForce-Produkte sind sicherlich noch immer das Aushängeschild für NVIDIA, doch im Hintergrund wird die Umstrukturierung seit Jahren vollzogen. NVIDIA legt sein Engineering in der GPU-Architektur klar hinsichtlich des GPU-Computings aus. Die GeForce-Produkte als Nebenprodukt dieser Entwicklung abzustempeln, wäre sicherlich etwas zu weit gegriffen, denn GPU-Computing und Gaming schließen sich nicht zwangsläufig aus.
"Pascal" wird im kommenden Jahr zeigen wohin der Weg geht. Mixed Precision, NVLink und 3D Memory klingen zunächst einmal nicht danach, als könne der Spieler davon profitieren. Zumindest für NVLink mag dies auch zutreffen. Gerade der 3D Memory dürfte im Zusammenspiel mit der beschleunigten Architektur aber auch Spielerherzen wohlstimmen können. Für abschließende Einschätzungen der Performance ist es aber noch zu früh. NVIDIA beschreibt seine Zahlen selbst als "grobe Schätzwerte". Ob die GM200-GPU das komplette restliche Jahr wird bedienen können oder ob NVIDIA noch eine GM210 hinterherschieben kann, wird wohl ebenfalls deren Geheimnis bleiben.
