
Werbung
NVIDIA präsentierte NVLink zur GPU Technology Conference 2014 im vergangenen Jahr und adressiert damit den vermeintlichen Flaschenhals in der Zusammenarbeit zwischen GPU und GPU in Multi-GPU-Systemen sowie GPU und CPU. In diesem Jahr gab es auf der GTC 2015 wenig neues zu NVLink zu berichten, denn erstmals zum Einsatz kommen soll der schnellere Interconnect mit der "Pascal"-GPU, die 2016 erscheinen soll. Man darf aktuell auch davon ausgehen, dass NVLink zunächst einmal nur im GPU-Computing und der dazugehörigen Hardware eine wichtige Rolle spielen wird. PCI-Express 3.0 ist aktuell im Gaming-Bereich schnell genug und die bereits angekündigte Nachfolgegeneration 4.0 mit doppelter Bandbreite wurde zumindest bereits spezifiziert. Spiele werden in den kommenden GPU-Generationen vor allem durch eine schnellere Anbindung von GPU an den Grafikspeicher profitieren - High Bandwidth Memory ist hier das Stichwort.
Anders sieht es hingegen dort aus, wo GPUs dazu verwendet werden, wissenschaftliche Berechnungen durchzuführen. Je nach Anwendung werden konstant extrem viele Daten an die GPU geliefert, die dann dort berechnet werden. Ebenfalls denkbar sind Szenarien, bei denen die Daten von der GPU auch wieder schnell in einen Speicher außerhalb des GPU-Packages geschrieben werden müssen. NVLink soll hier fünf bis zwölfmal schneller sein als PCI-Express. IBM will ab 2016 in seinen Servern auf NVLink setzen. Dazu hat man die Technologie bei NVIDIA lizensiert und verbaut den Interconnect direkt in seine POWER-Prozessoren. Heute nun geht NVIDIA etwas konkreter auf explizite Anwendungen ein, die von NVLink profitieren sollen.
Fast Fourier Transform (FFT)
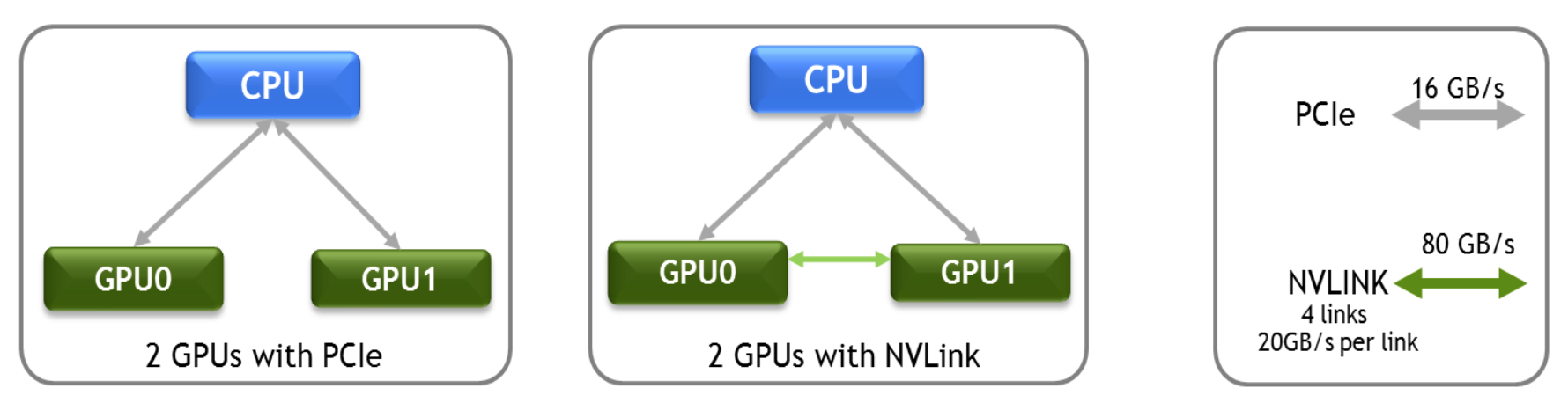
Eine Fourier-Transformation ist eine Methode kontinuierliche, aperiodische Signale in ein kontinuierliches Spektrum zu zerlegen. Verwendet wird dieser in der Signal- und Bildverarbeitung sowie seismischen Analysen und partiellen Differentialgleichungen. Oftmals werden solche FTTs in Servern berechnet, die über zwei GPUs verfügen, die wiederum von einer CPU gefüttert werden. Der Datenaustausch erfolgt über das PCI-Express-Interface mit 16 GB pro Sekunde. Die gleiche Hardware-Konfiguration mit NVLink soll Bandbreiten von bis zu 80 GB pro Sekunde erreichen.

In der Praxis bedeutet diese erhöhte Bandbreite einen Leistungsgewinn um den Faktor zwei - nicht also die rein rechnerische fünffache Leistung. Dennoch ist der Sprung in der Leistung beachtlich.
AMBER
AMBER ist eine Anwendung, die das Verhalten von Molekülen, Atomen und Körperzellen simulieren kann. In der medizinischen Forschung wird damit das Verhalten von Krebszellen auf atomarer Ebene simuliert, um daraus Methoden zu entwickeln, den Krebs besser vorherzusagen oder bekämpfen zu können. Solche Berechnungen sind noch stärker von der Leistung der GPU abhängig, benötigen aber natürlich noch immer einen Prozessor, der die Operationen zuteilt und die Daten für die GPUs aufbereitet. Üblicherweise kommen hier Konfigurationen von vier GPUs mit einer CPU zum Einsatz.

AMBER setzt aber auch voraus, dass die GPUs Daten untereinander austauschen können, was bisher ebenfalls nur über das PCI-Express-Interface möglich war. Die Datenpfade waren dabei nicht immer bestmöglich verteilt und so musste der Austausch Umwege über PCI-Express-Switches oder den Prozessor gehen, der die PCI-Express-Lanes zur Verfügung stellt.
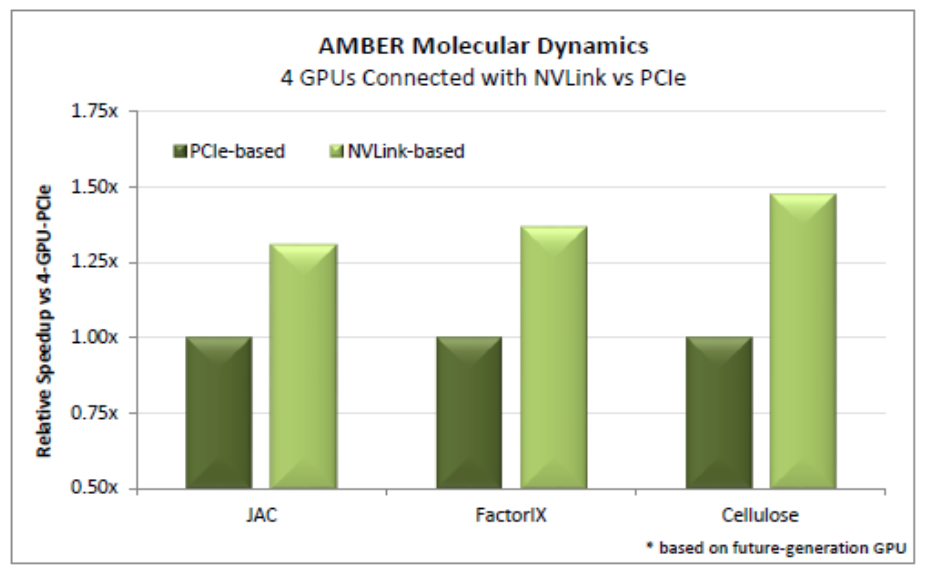
Mit NVLInk ist ein direkter Interconnect zwischen den GPUs möglich, so dass die Daten auch direkter untereinander ausgetauscht werden können. Dies reduziert die Last in der Anbindung des Prozessors und macht zusätzliche Ressourcen frei. Ein Leistungsplus von 30 bis 50 % soll so möglich sein.
NVLink vs. PCI-Express
Einen kleinen Vergleich der Bandbreite zwischen NVLink und PCI-Express wollen wir natürlich auch anstellen, schließlich geht es die ganze Zeit darum, dass NVLink hier deutliche Vorteile besitzt. Laut NVIDIA soll NVLink fünf bis zwölf mal schneller sein. Die Bandbreite wird demzufolge zwischen 80 und 200 GB pro Sekunde liegen. Bis zu Einführung werden wir vermutlich bereits PCI-Express 4.0 sehen, das die Bandbreite von PCI-Express 3.0 noch einmal verdoppelt und damit auf 31,51 GB pro Sekunde bzw. 256 GT/s kommt. NVLink wäre also auch dann noch zweieinhalb bis sechs mal schneller.
Parallelen sind bei der Art und Weise der Implementierung zu finden. NVIDIA setzt für NVLink eine direkte Punkt-zu-Punkt-Verbindung ein - ähnlich wie dies bei PCI-Express der Fall ist. Diese besteht wiederum aus jeweils acht Lanes pro NVLink-Verbindung. "Pascal" wird zunächst einmal vier NVLinks anbieten können. Laut NVIDIA lässt sich deren Anzahl aber auch abhängig vom gewünschten Zielmarkt anpassen - allerdings wohl zunächst einmal nicht für "Pascal", sondern in Hinblick auf zukünftige GPUs. Die NVLink-Verbindungen können dabei flexibel zusammengefasst, um auch hier wieder dem jeweiligen Anwendungsfall gerecht zu werden. Denkbar ist beispielsweise eine einfache GPU-CPU-Verbindung, aber auch ein Netzwerk aus GPU-CPU- und GPU-GPU-Verbindungen.
Auch andere Hersteller arbeiten an schnelleren Interconnects. So verwendet Intel bei seinen Xeon-Phi-Beschleunigern "Knights Landing" Omni-Path der ersten Generation, dass die Latenzen der Anbindung verkürzen und eine Bandbreite von 100 GB pro Sekunde aufweisen soll. Intel positioniert Omni-Path direkt gegen die etablierte InfiniBand-Technik, die aktuell in den meisten derartigen Systemen zum Einsatz kommt. Für die nachfolgenden Xeon-Phi-Generationen ist eine zweite Generation geplant.
NVLink wird also vermutlich zunächst einmal eine Technik bleiben, die sich auf den professionellen Bereich beschränkt. Für Spieler und zukünftige Anforderungen in dieser Hinsicht bietet NVLink aber sicherlich ebenfalls ein gewisses Potenzial, dass wir aber erst ab dem kommenden Jahr werden abschätzen können. Bis dahin haben sich die Bedürfnisse an die Anbindung von GPU, CPU und Grafikspeicher noch einmal maßgeblich geändert.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen