
Werbung
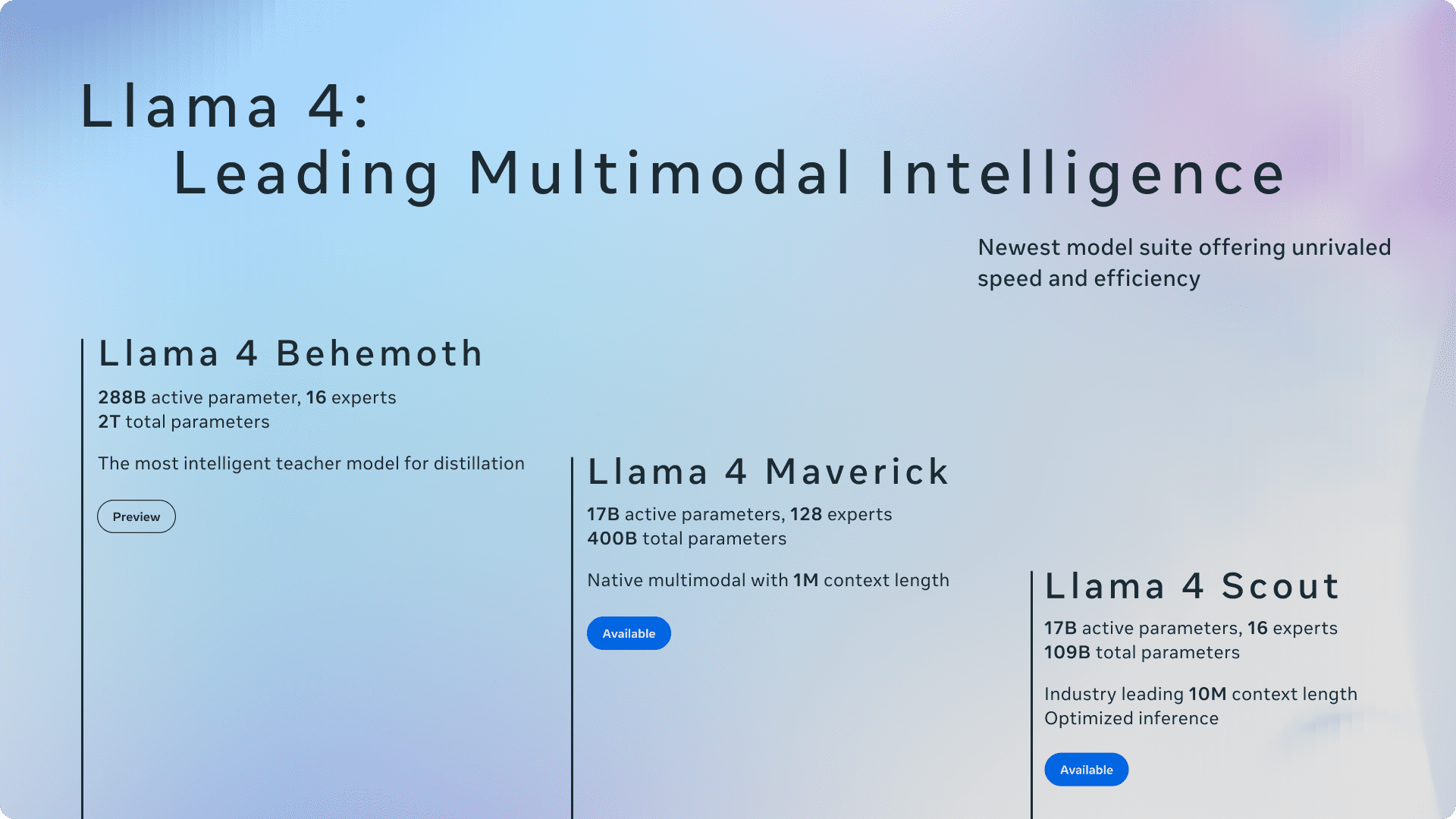
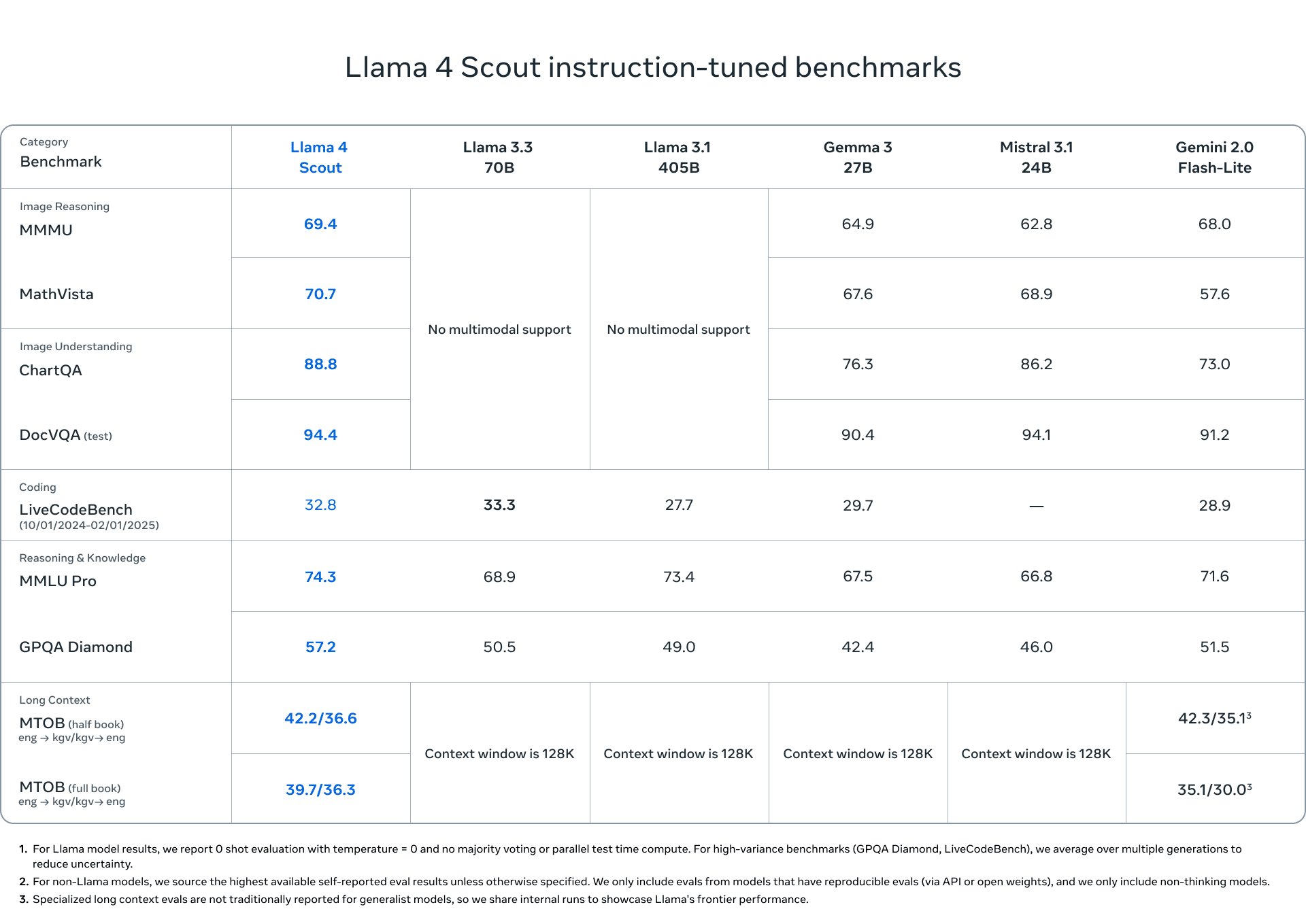
Meta hat mit der Llama 4-Serie eine neue Generation multimodaler Sprachmodelle vorgestellt, die sich durch technische Innovationen und hohe Effizienz auszeichnen wollen. Das Einstiegsmodell Llama 4 Scout nutzt dabei 17 Milliarden aktive Parameter, die auf 16 Experten verteilt sind, und kann dank seiner Architektur vollständig auf einer einzigen NVIDIA H100 GPU betrieben werden. Es unterstützt eine kontextuelle Eingabelänge von bis zu 10 Millionen Tokens, was bisherige Grenzen deutlich übertrifft. Das Modell setzt auf eine Kombination aus dichter und Mixture-of-Experts-Architektur und soll hohe Leistungswerte in Benchmarks gegenüber Gemma 3, Gemini 2.0 Flash-Lite und Mistral 3.1 zeigen.
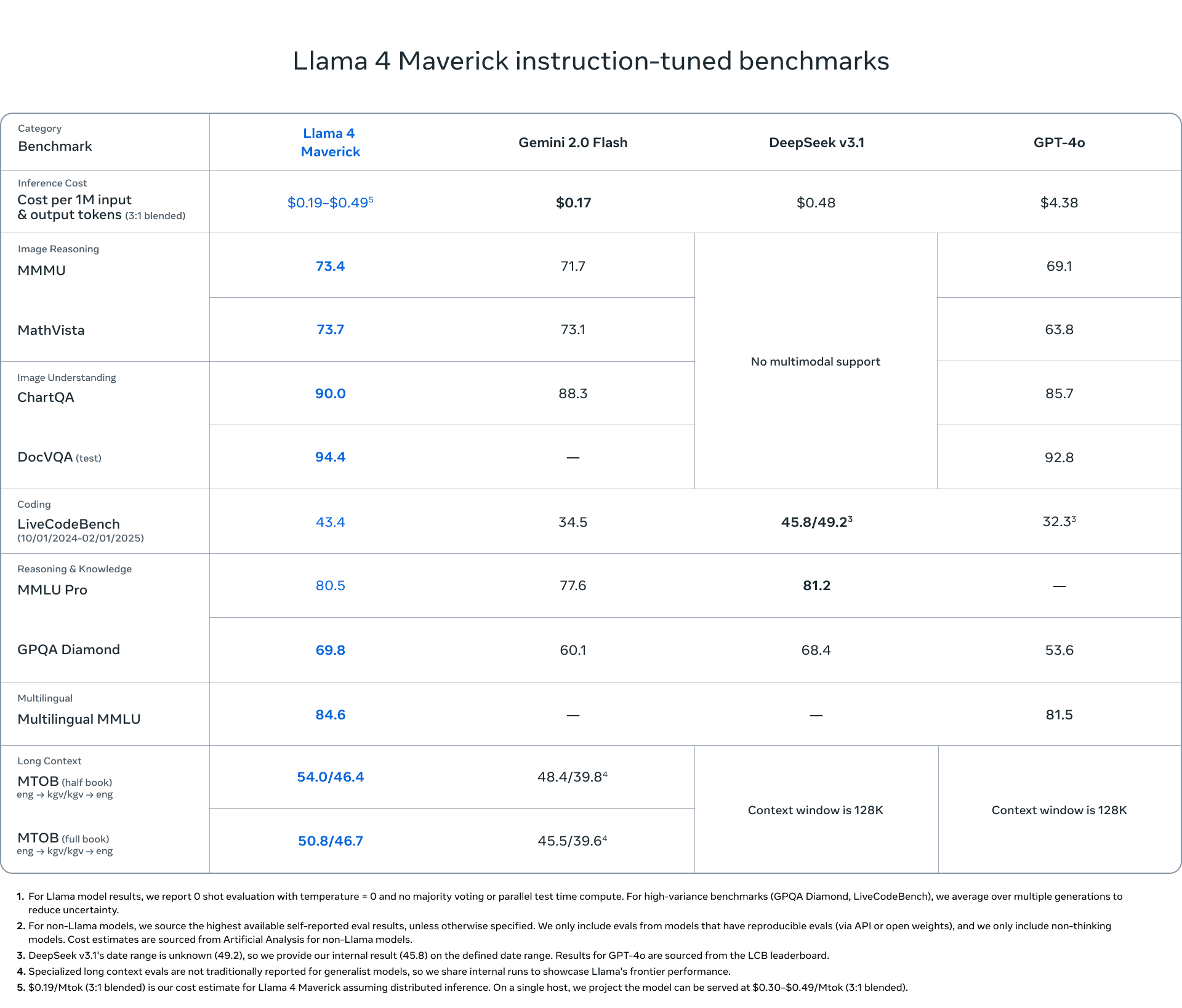
Llama 4 Maverick, ebenfalls mit 17 Milliarden aktiven Parametern, nutzt 128 Experten und erreicht eine Gesamtparameteranzahl von 400 Milliarden. Im Vergleich zu GPT-4o und Gemini 2.0 Flash bietet Maverick bessere Ergebnisse in den Bereichen Codierung, Bildverständnis, Mehrsprachigkeit und logisches Schließen. Bei der Entwicklung wurde laut Meta ein kontinuierliches Online-Reinforcement-Learning-System eingesetzt, bei dem gezielt mittelschwere bis schwere Eingabeaufforderungen für das Training genutzt wurden. Dies soll signifikante Leistungssteigerungen bei gleichzeitiger Reduktion der Rechenkosten ermöglichen.
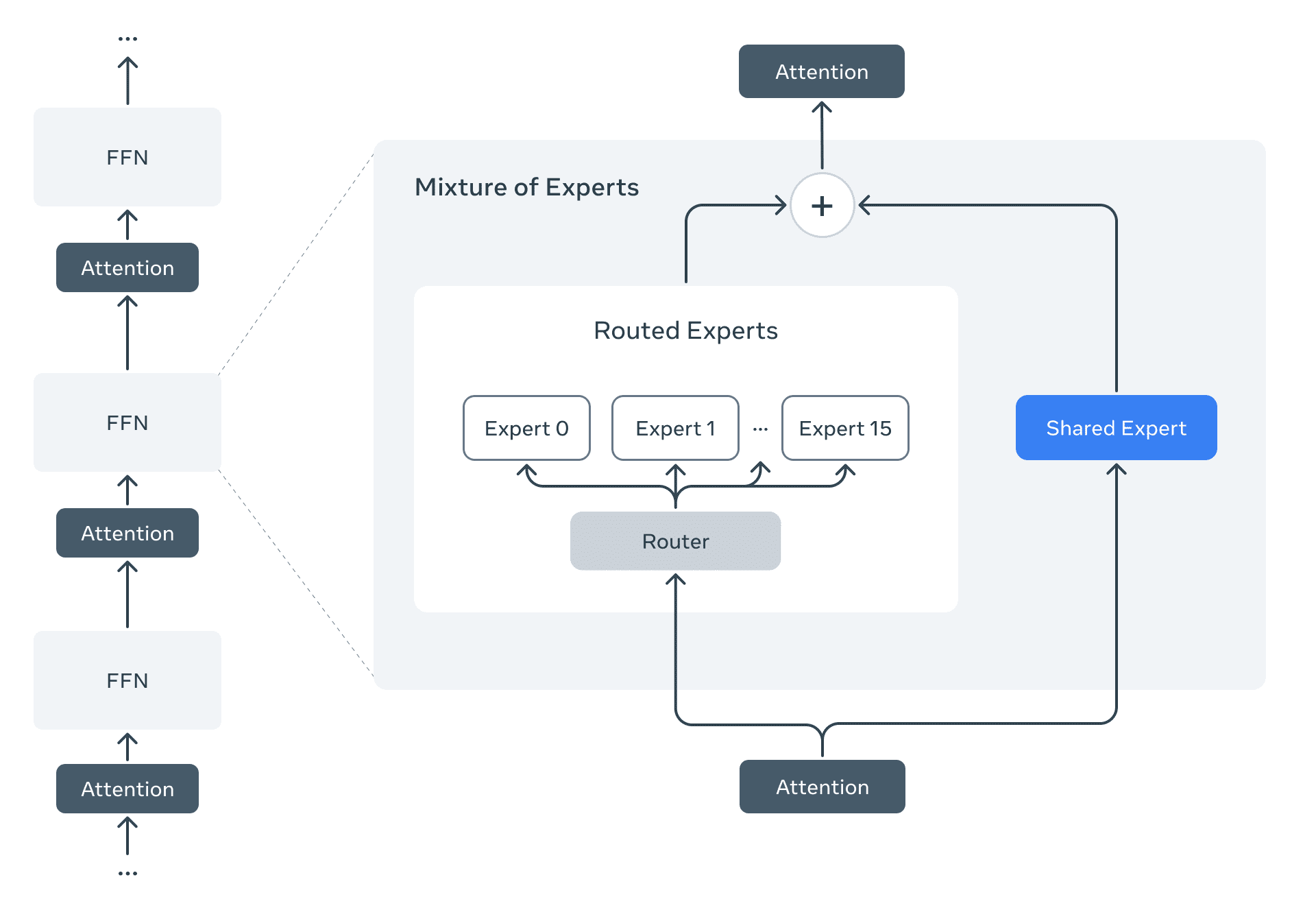
Beide Modelle wurden nativ für multimodale Aufgaben entwickelt. Das bedeutet, dass Text- und Bilddaten früh im Modell zusammengeführt werden. Die Vision-Encoder basieren auf einer angepassten MetaCLIP-Architektur und wollen eine präzise Bildverarbeitung sowie eine robuste Objektverankerung bei visuellen Eingaben ermöglichen. Während des Pretrainings sollen bis zu 48 Bilder gleichzeitig verarbeitet worden sein. In der Post-Trainingsphase zeigte sich das System laut Meta auch bei bis zu acht Bildern stabil. Diese Fähigkeiten sollen auch komplexe visuelle Aufgaben wie Bildbeschreibung, visuelles Frage-Antworten und Verständnis zeitlicher Bildabfolgen erlauben.
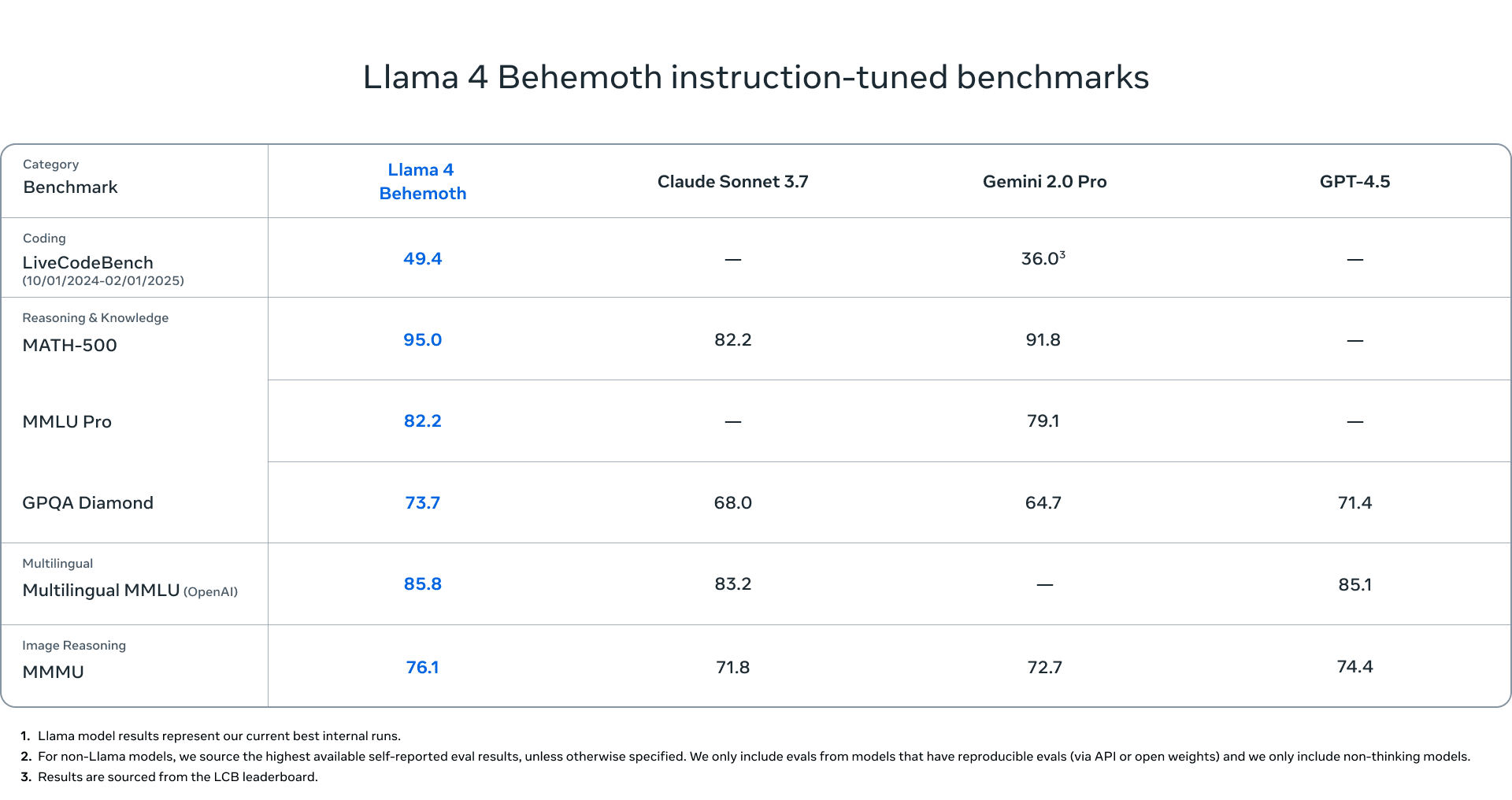
Eine zentrale Rolle bei der Entwicklung spielt das Lehrermodell Llama 4 Behemoth. Dieses basiert auf derselben multimodalen Mixture-of-Experts-Architektur, skaliert jedoch auf 288 Milliarden aktive Parameter mit insgesamt fast zwei Billionen Parametern. Behemoth übertrifft GPT-4.5, Claude Sonnet 3.7 und Gemini 2.0 Pro in verschiedenen STEM-Benchmarks wie MATH-500 und GPQA Diamond. Es dient als Codistillationsquelle für Scout und Maverick, wobei eine dynamisch gewichtete Distillationsverlustfunktion zum Einsatz kommt, die sowohl harte als auch weiche Zielvorgaben berücksichtigt. Der Trainingsprozess wurde dabei von Meta vollständig überarbeitet, einschließlich eines skalierbaren Reinforcement-Learning-Ansatzes mit promptbasierter Schwierigkeitsanpassung, um optimale Leistung in Bereichen wie Mathematik, Codierung und logisches Denken zu erzielen. Die zugrundeliegende RL-Infrastruktur wurde asynchron konzipiert und erlaubt flexible GPU-Zuweisung, was eine rund zehnfache Effizienzsteigerung im Vergleich zu früheren Generationen bedeutet.
Die Modelle veröffentlicht Meta unter der Llama-Lizenz, einem eingeschränkten Open-Source-Ansatz. Beispielsweise gibt es eine Obergrenze von 700 Millionen Nutzern, die ein Dienst haben darf, damit die Modelle eingesetzt werden dürfen. Andernfalls muss Meta aktiv einwilligen. Zudem schauen Unternehmen und Nutzer mit einem Standort innerhalb der EU vorerst in die Röhre, denn auch ihnen wird die Nutzung der Modelle verweigert.
