
LLM
-
AMD und Amuse: Angepasste Modelle für KI-Fotos und -Videos
 Mit einer neuen Version an KI-Modellen sowie einem angepassten Treiber bieten AMD und Amuse nun eine deutlich bessere Leistung in der Ausführung von sogenannter Generative-AI. Dabei handelt es sich um KI-Modelle, die Inhalte kreiert oder umwandelt. Im Rahmen der neuen Version von Amuse 3.0 gibt es unter anderem Modelle für Text zu Video (Video Diffusion), Video zu Video (Video Restyle) und für mehr als 100 neue Bildmodelle der... [mehr]
Mit einer neuen Version an KI-Modellen sowie einem angepassten Treiber bieten AMD und Amuse nun eine deutlich bessere Leistung in der Ausführung von sogenannter Generative-AI. Dabei handelt es sich um KI-Modelle, die Inhalte kreiert oder umwandelt. Im Rahmen der neuen Version von Amuse 3.0 gibt es unter anderem Modelle für Text zu Video (Video Diffusion), Video zu Video (Video Restyle) und für mehr als 100 neue Bildmodelle der... [mehr] -
Llama 4: Metas neue KI-Modelle werden noch komplexer
 Meta hat mit der Llama 4-Serie eine neue Generation multimodaler Sprachmodelle vorgestellt, die sich durch technische Innovationen und hohe Effizienz auszeichnen wollen. Das Einstiegsmodell Llama 4 Scout nutzt dabei 17 Milliarden aktive Parameter, die auf 16 Experten verteilt sind, und kann dank seiner Architektur vollständig auf einer einzigen NVIDIA H100 GPU betrieben werden. Es unterstützt eine kontextuelle Eingabelänge von bis zu 10... [mehr]
Meta hat mit der Llama 4-Serie eine neue Generation multimodaler Sprachmodelle vorgestellt, die sich durch technische Innovationen und hohe Effizienz auszeichnen wollen. Das Einstiegsmodell Llama 4 Scout nutzt dabei 17 Milliarden aktive Parameter, die auf 16 Experten verteilt sind, und kann dank seiner Architektur vollständig auf einer einzigen NVIDIA H100 GPU betrieben werden. Es unterstützt eine kontextuelle Eingabelänge von bis zu 10... [mehr] -
Verbessertes unüberwachtes Lernen: OpenAI stellt GPT-4.5 vor
 OpenAI hat GPT-4.5 vorgestellt, das die neueste Version seiner KI-Sprachmodelle repräsentiert und ab sofort als Forschungsvorschau für ChatGPT-Pro-Nutzer und Entwickler weltweit zur Verfügung steht. Dieses Modell will einen bedeutenden Fortschritt in der Skalierung von unüberwachtem Lernen repräsentieren und umfangreiches Weltwissen mit verbesserter emotionaler Intelligenz kombinieren. GPT-4.5 wurde laut OpenAI entwickelt, um Muster... [mehr]
OpenAI hat GPT-4.5 vorgestellt, das die neueste Version seiner KI-Sprachmodelle repräsentiert und ab sofort als Forschungsvorschau für ChatGPT-Pro-Nutzer und Entwickler weltweit zur Verfügung steht. Dieses Modell will einen bedeutenden Fortschritt in der Skalierung von unüberwachtem Lernen repräsentieren und umfangreiches Weltwissen mit verbesserter emotionaler Intelligenz kombinieren. GPT-4.5 wurde laut OpenAI entwickelt, um Muster... [mehr] -
Grok 3: xAI stellt sein neustes KI-Modell vor
 Elon Musks KI-Unternehmen xAI hat mit Grok 3 die nächste Generation seiner KI-Modelle vorgestellt. Die Modellfamilie Grok 3 umfasst dabei mehrere Varianten, darunter Grok 3 mini, eine optimierte Version mit reduzierter Größe, die laut xAI schnellere Reaktionszeiten bei einer weiterhin hohen Genauigkeit bieten soll. Derzeit ist das Modell noch nicht für die breite Öffentlichkeit verfügbar, die Markteinführung soll jedoch bald erfolgen. Laut... [mehr]
Elon Musks KI-Unternehmen xAI hat mit Grok 3 die nächste Generation seiner KI-Modelle vorgestellt. Die Modellfamilie Grok 3 umfasst dabei mehrere Varianten, darunter Grok 3 mini, eine optimierte Version mit reduzierter Größe, die laut xAI schnellere Reaktionszeiten bei einer weiterhin hohen Genauigkeit bieten soll. Derzeit ist das Modell noch nicht für die breite Öffentlichkeit verfügbar, die Markteinführung soll jedoch bald erfolgen. Laut... [mehr] -
OpenAI: GPT-4.5 und GPT-5 für die kommenden Wochen und Monate angekündigt
OpenAI bereitet die Einführung neuer Sprachmodelle vor. In den kommenden Wochen soll zunächst GPT-4.5 veröffentlicht werden, bevor später im Jahr GPT-5 folgen wird. GPT-4.5, intern als "Orion" bezeichnet, wird das letzte Modell sein, das ohne explizite Chain-of-Thought-Prozesse arbeitet – eine Technik, die bei komplexen Aufgaben den Denkprozess des Modells besser nachvollziehbar macht. Mit diesem Update möchte OpenAI die bestehende Produktlinie... [mehr] -
OpenAI: Nächstes großes KI-Modell soll im Dezember erscheinen
OpenAI plant aktuell die Veröffentlichung seines nächsten großen KI-Modells. Wie The Verge erfahren haben will, soll OpenAI sein nächstes Frontier-Modell mit dem Namen Orion bereits im Dezember auf den Markt bringen. Im Gegensatz zu den letzten beiden Modellen von OpenAI, GPT-4o und o1, wird Orion aber zunächst nicht über ChatGPT veröffentlicht werden. Stattdessen plant OpenAI, zunächst Unternehmen, mit denen es eng zusammenarbeitet,... [mehr] -
Mecha Break: Erstes Spiel mit LLM für die NPC-Interaktion vorgestellt
NVIDIA nutzt die gamescom um mit Mecha Break ein erstes Spiel anzukündigen, welches die ACE-Technik (Avatar Cloud Engine) nutzt. Bei NVIDIA ACE handelt es sich um eine AI-unterstützte Plattform für Game-Designer, die NeMo- und Omniverse-Komponenten enthält. Dabei geht es nicht nur darum Charaktere oder 3D-Elemente per KI zu generieren, sondern auch darum, die Welt oder Szene zum Leben zu erwecken. In einem Beispiel werden dem NPC... [mehr] -
Wettbewerbsverstöße: Nvidia droht Anzeige in Frankreich
 Die unangemeldete Durchsuchung im September 2023 bei NVIDIA durch die französische Kartellbehörde (Autorité de la concurrence) könnte für den Konzern zum Problem werden. Laut dem veröffentlichten Abschlussbericht plant die Behörde nun eine Anzeige gegen das Unternehmen wegen Wettbewerbsverstößen. Dem Chiphersteller wird unter anderem Preisabsprache und gezielte Verknappung durch Nichtlieferung von Produkten vorgeworfen. Zudem hält die Behörde... [mehr]
Die unangemeldete Durchsuchung im September 2023 bei NVIDIA durch die französische Kartellbehörde (Autorité de la concurrence) könnte für den Konzern zum Problem werden. Laut dem veröffentlichten Abschlussbericht plant die Behörde nun eine Anzeige gegen das Unternehmen wegen Wettbewerbsverstößen. Dem Chiphersteller wird unter anderem Preisabsprache und gezielte Verknappung durch Nichtlieferung von Produkten vorgeworfen. Zudem hält die Behörde... [mehr] -
Sohu-ASIC für Transformer-Modelle: Beschleuniger soll 20mal schneller als NVIDIAs H100 sein
 Ein Startup namens Etched hat einen ASIC namens Sohu vorgestellt, der speziell auf das Inferencing von Transformer-Modellen ausgelegt sein soll. Ausgestattet mit 144 GB an HBM3E sowie bereits reservierten Kapazitäten für die Fertigung bei TSMC will das Startup eine Konkurrenz von NVIDIAs Beschleunigern und dabei um ein Vielfaches schneller sein. Transformer-Modelle sind eine Art von neuronalen Netzwerken, die speziell für die Verarbeitung von... [mehr]
Ein Startup namens Etched hat einen ASIC namens Sohu vorgestellt, der speziell auf das Inferencing von Transformer-Modellen ausgelegt sein soll. Ausgestattet mit 144 GB an HBM3E sowie bereits reservierten Kapazitäten für die Fertigung bei TSMC will das Startup eine Konkurrenz von NVIDIAs Beschleunigern und dabei um ein Vielfaches schneller sein. Transformer-Modelle sind eine Art von neuronalen Netzwerken, die speziell für die Verarbeitung von... [mehr] -
Google TPU Trillium: Auslegung für größere KI-Modelle
 Auf der gestrigen Google I/O stand alles im Fokus der Gemini-KI-Modelle, die auf den Android-Geräten ausgeführt werden sollen, die aber auch ein gewisses Rückgrat in den Rechenzentren benötigen. Dazu nutzt Google in weiten Teilen die eigens entwickelten TPUs. Nun hat man mit dem Trillium die nächste Generation vorgestellt. Sie soll die aktuellen TPU v5e ersetzen bzw. erweitert die Hardware um die aktuellen... [mehr]
Auf der gestrigen Google I/O stand alles im Fokus der Gemini-KI-Modelle, die auf den Android-Geräten ausgeführt werden sollen, die aber auch ein gewisses Rückgrat in den Rechenzentren benötigen. Dazu nutzt Google in weiten Teilen die eigens entwickelten TPUs. Nun hat man mit dem Trillium die nächste Generation vorgestellt. Sie soll die aktuellen TPU v5e ersetzen bzw. erweitert die Hardware um die aktuellen... [mehr] -
OpenAI Spring-Update-Event: GPT-4o für Echtzeitgespräche, GPT-4 für alle und neue Apps
 In einem per YouTube ausgestrahlten Spring-Update-Event hat OpenAI einige Neuerungen verkündet. Die Zusammenarbeit mit Apple für iOS 18 oder die Vorstellung eines neuen Large Language Models namens GPT-5 waren allerdings nicht dabei. Nicht weniger interessant ist allerdings das, was man vorgestellt hat. Die wichtigste Neuerung ist sicherlich die Vorstellung von GPT-4o. Das kleine "o" steht bei für "omni" – Sprache, Text und Bild... [mehr]
In einem per YouTube ausgestrahlten Spring-Update-Event hat OpenAI einige Neuerungen verkündet. Die Zusammenarbeit mit Apple für iOS 18 oder die Vorstellung eines neuen Large Language Models namens GPT-5 waren allerdings nicht dabei. Nicht weniger interessant ist allerdings das, was man vorgestellt hat. Die wichtigste Neuerung ist sicherlich die Vorstellung von GPT-4o. Das kleine "o" steht bei für "omni" – Sprache, Text und Bild... [mehr] -
Eigene Bilder durchsuchbar: Mit ChatRTX hören die LLMs aufs Wort
NVIDIA hat mit Chat with RTX bereits ein Werkzeug veröffentlicht, welches LLMs lokal ausführen kann und den Einstieg dazu einfach soll. Nun hat man ChatRTX veröffentlicht, welches eine Sprachkomponente bekommen hat und um die Large-Language-Modelle Gemma und ChatGLM3 erweitert wurde. Letztgenanntes LLM arbeitet bilingual und kann in Englisch und Chinesisch angesprochen werden. NVIDIA hatte in der Vergangenheit bereits angekündigt, dass... [mehr] -
DeepL Write Pro: Textverbesserung nun in Echtzeit möglich
 Die Kölner KI-Spezialisten von DeepL haben ihren eigenen Schreibassistenten DeepL Write um eine neue Pro-Version erweitert. Das Upgrade steht dabei Unternehmen wie auch Einzelpersonen gleichermaßen zur Verfügung. Bei DeepL Write handelt es sich um einen Schreibassistenten, welcher alternative Formulierungen für bereits bestehende Texte vorschlägt. Die Pro-Variante des Assistenten beherrscht diese Funktion nun auch, während der Text gerade... [mehr]
Die Kölner KI-Spezialisten von DeepL haben ihren eigenen Schreibassistenten DeepL Write um eine neue Pro-Version erweitert. Das Upgrade steht dabei Unternehmen wie auch Einzelpersonen gleichermaßen zur Verfügung. Bei DeepL Write handelt es sich um einen Schreibassistenten, welcher alternative Formulierungen für bereits bestehende Texte vorschlägt. Die Pro-Variante des Assistenten beherrscht diese Funktion nun auch, während der Text gerade... [mehr] -
KI-Modelle: Massenhaft YouTube-Videos zum Training benutzt
 Unternehmen wie OpenAI und Google sind ständig auf der Suche nach neuen Datenquellen für ihre KI-Modelle, insbesondere für das Training ihrer Large Language Models (LLMs). Doch diese Daten sind nicht unbegrenzt verfügbar. Dazu gibt es zunehmend Bedenken hinsichtlich der Quellen, die genutzt aktuell werden. OpenAI, verantwortlich für GPT-4, stand bereits im Jahr 2021 vor dem Problem, dass ihnen die Daten knapp wurden. Um diesem Engpass... [mehr]
Unternehmen wie OpenAI und Google sind ständig auf der Suche nach neuen Datenquellen für ihre KI-Modelle, insbesondere für das Training ihrer Large Language Models (LLMs). Doch diese Daten sind nicht unbegrenzt verfügbar. Dazu gibt es zunehmend Bedenken hinsichtlich der Quellen, die genutzt aktuell werden. OpenAI, verantwortlich für GPT-4, stand bereits im Jahr 2021 vor dem Problem, dass ihnen die Daten knapp wurden. Um diesem Engpass... [mehr] -
MLPerf Inference 4.0: Das Debüt der H200 von NVIDIA gelingt
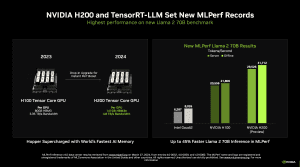 Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr]
Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr] -
Chat With RTX: Ab sofort in einer frühen Beta verfügbar
 NVIDIA hat soeben Chat With RTX, eine Demo für das lokale Ausführen von KI-Anwendungen in einer frühen Beta freigegeben. Damit lässt sich ein Sprachmodell nicht nur lokal ausführen, sondern theoretisch auch mit eigenen Daten füttern. Man könnte hier von einer Art Technologie-Demo sprechen, denn Chat With RTX greift natürlich auf viele von NVIDIA entwickelte Hard- und Software-Techniken zurück. Zu diesen gehört retrieval-augmented... [mehr]
NVIDIA hat soeben Chat With RTX, eine Demo für das lokale Ausführen von KI-Anwendungen in einer frühen Beta freigegeben. Damit lässt sich ein Sprachmodell nicht nur lokal ausführen, sondern theoretisch auch mit eigenen Daten füttern. Man könnte hier von einer Art Technologie-Demo sprechen, denn Chat With RTX greift natürlich auf viele von NVIDIA entwickelte Hard- und Software-Techniken zurück. Zu diesen gehört retrieval-augmented... [mehr] -
NVIDIA kontert: H100 soll deutlich schneller als Instinct MI300X sein
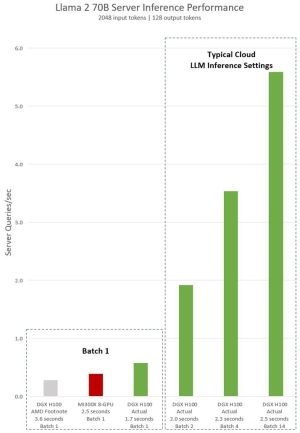 Zusammen mit der Vorstellung der Instinct MI300A und Instinct MI300X präsentierte AMD in der vergangenen Woche auch beeindruckende Leistungsdaten. Laut dieser ist der Instinct-MI300X-Beschleuniger mindestens auf Augenhöhe mit dem H100-Beschleuniger von NVIDIA. Nun aber kontert NVIDIA die von AMD gemachten Aussagen und veröffentlicht in einem Blogpost neue Zahlen, die auch Bezug auf den Instinct-MI300X-Beschleuniger nehmen. Was dabei... [mehr]
Zusammen mit der Vorstellung der Instinct MI300A und Instinct MI300X präsentierte AMD in der vergangenen Woche auch beeindruckende Leistungsdaten. Laut dieser ist der Instinct-MI300X-Beschleuniger mindestens auf Augenhöhe mit dem H100-Beschleuniger von NVIDIA. Nun aber kontert NVIDIA die von AMD gemachten Aussagen und veröffentlicht in einem Blogpost neue Zahlen, die auch Bezug auf den Instinct-MI300X-Beschleuniger nehmen. Was dabei... [mehr] -
Forschungspapier: Schnelllebige Supercomputer für LLM-Modelle
 Mit der heutigen Veröffentlichung von Llama 2 sowie der bereits erfolgten Veröffentlichung einiger vortrainierter Large Language Modelle soll die Abhängigkeit von kleineren Entwicklern und Firmen verringert und der Zugang zu solchen Modellen vereinfacht werden. Das Training solcher Modelle kostet je nach Größe mehreren Millionen US-Dollar, stellenweise sollen es schon hunderte Millionen sein. NVIDIA verdient gut daran, denn vermutlich geht... [mehr]
Mit der heutigen Veröffentlichung von Llama 2 sowie der bereits erfolgten Veröffentlichung einiger vortrainierter Large Language Modelle soll die Abhängigkeit von kleineren Entwicklern und Firmen verringert und der Zugang zu solchen Modellen vereinfacht werden. Das Training solcher Modelle kostet je nach Größe mehreren Millionen US-Dollar, stellenweise sollen es schon hunderte Millionen sein. NVIDIA verdient gut daran, denn vermutlich geht... [mehr] -
Meta veröffentlicht Llama 2: Open-Source-LLM soll Entwicklung vorantreiben
 Nachdem das erste Large Language Model Llama von Meta mehr oder weniger offiziell seinen Weg in die Weiten des Internets gefunden hat, wurde die zweite Generation Llama 2 direkt als Open-Source-Modell vorgestellt. Die freie Nutzung ist für Forschungszwecke und die kommerzielle Nutzung möglich. Damit folgt Meta in dieser Hinsicht dem Software- und AI-Spezialisten MosaicML, die ähnliche Sprachmodelle bereits vor einiger Zeit veröffentlicht... [mehr]
Nachdem das erste Large Language Model Llama von Meta mehr oder weniger offiziell seinen Weg in die Weiten des Internets gefunden hat, wurde die zweite Generation Llama 2 direkt als Open-Source-Modell vorgestellt. Die freie Nutzung ist für Forschungszwecke und die kommerzielle Nutzung möglich. Damit folgt Meta in dieser Hinsicht dem Software- und AI-Spezialisten MosaicML, die ähnliche Sprachmodelle bereits vor einiger Zeit veröffentlicht... [mehr] -
MI250 gegen A100: MosaicML zeigt Konkurrenten fast auf Augenhöhe
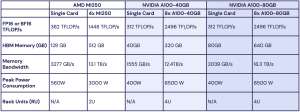 Vor einigen Wochen machte das Unternehmen MosaicML auf sich aufmerksam, da man vortrainierte MPT-7B-Modelle als Open-Source veröffentlichte und somit der LLM-Forschung (Large Language Model) einen gewissen Vortrieb geben wollte. Bei MosaicML hat man sich darauf spezialisiert, das Software-Ökosystem für AI-Systeme zu optimieren, denn über eine optimierte Software lassen sich große Leistungssprünge im Training erreichen – ein um 30 %... [mehr]
Vor einigen Wochen machte das Unternehmen MosaicML auf sich aufmerksam, da man vortrainierte MPT-7B-Modelle als Open-Source veröffentlichte und somit der LLM-Forschung (Large Language Model) einen gewissen Vortrieb geben wollte. Bei MosaicML hat man sich darauf spezialisiert, das Software-Ökosystem für AI-Systeme zu optimieren, denn über eine optimierte Software lassen sich große Leistungssprünge im Training erreichen – ein um 30 %... [mehr] -
Sprachmodell für kommerzielle Nutzung: MosaicML veröffentlicht MPT-7B als Open-Source
 Große Sprachmodelle (Large Language Model oder kurz LLM) sind aktuell in aller Munde. Bei MosaicML hat man sich darauf spezialisiert, das Software-Ökosystem für AI-Systeme zu optimieren, denn über eine optimierte Software lassen sich große Leistungssprünge im Training erreichen – ein um 30 % beschleunigtes Training bei gleicher Hardware ist bei einer solchen Optimierung keine Seltenheit. Eines der Probleme der Sprachmodelle ist aktuell,... [mehr]
Große Sprachmodelle (Large Language Model oder kurz LLM) sind aktuell in aller Munde. Bei MosaicML hat man sich darauf spezialisiert, das Software-Ökosystem für AI-Systeme zu optimieren, denn über eine optimierte Software lassen sich große Leistungssprünge im Training erreichen – ein um 30 % beschleunigtes Training bei gleicher Hardware ist bei einer solchen Optimierung keine Seltenheit. Eines der Probleme der Sprachmodelle ist aktuell,... [mehr]
