ESX 3.5 ist alte Kamelle
")
Und nein, ich werfe die Begriffe nicht durcheinander. Das machst schon du selbst
Memorysharing hat grundsätzlich nichts mit überbuchen ansich zu tun.
Es sind grundverschiedenen Sachen. Du erwähntest aber, mit dem einen, kann man auch gleichsam das andere machen. -> was potentiell zwar geht, aber eben nicht so gewollt sein muss.
Auch sprichst du von Anfang an von irgendwelchen riesen Hosts mit xx VMs um deine Aussagen zu untermauern. Wärend LaMagra-X von einem Host mit genau Zwei! VMs sprach. Somit bist du fernab der Fragestellung.
Beide VMs sind dazu noch mehr oder weniger Grundverschieden. 2012 Server + Exchange sowie Windows 7 mit Datev irgendwas...
Das eine hat mit dem anderen also vllt ein paar wenige hundert MB am reinen RAM Bedarf gemein. Wenn überhaupt.
Memorysharing fällt zu einem Großteil also gänzlich flach. Womit sich deine ganze Aussage in Luft auflöst
Weil hat einfach nichts mit der Frage mehr zu tun.
Übrigens, hast du deine Links überhaupt gelesen?
Im "Memory overcommit in production? YES YES YES" Link steht ähnliches beschrieben, wie ich schon sagte.
"ESX will start some memory optimization and reclaim techniques,
but in the end it will swap host memory to disk, which is bad. It is essential to carefully monitor your hosts to see if you’re moving from good memory overcommit to bad memory overcommit."
Genau das sagte ich oben, mehrfach...
Im Beispiel aus dem Link waren 48GB im Host. = 12 x 4GB pro VM im simplen Fall.
Realverbrauch im Beispiel von ~2,5GB = 19 VMs in 48GB parkbar.
Im Beispiel genutzt = 17 VMs zu ~2,5GB = 42,5GB am Host.
Das Problem an diesem Beispiel ist aber, es sind alle samt VMs mit scheinbar vorhersagbarem RAM Verbrauch. Sprich ohne beispielsweise dem Filecachingmöglichkeiten von aktuellen Windows/*nix Sytemen.
Wie ich eingangs erwähnt habe, hängt es vom Gast-OS ab, wie der Verbrauch sich in der VM zusammensetzt. Ein Windows 2003 Server oder älter hat so in der Art keinen riesigen Filecache. Der RAM Verbrauch hält sich extrem übersichlich. Und ist weitestgehend vorhersagbar bzw. einschränkbar.
Neuere Windows OSen hingegen haben vollkommen unvorhersagbar einen Filecache per default, der dir binnen Minuten den RAM vollständig wegfressen kann.
Um beim konkreten Beispiel zu bleiben, der Realverbrauch der VMs liegt somit nicht bei ~2,5GB, sondern schlechtestenfalls im Schnitt bei ~4GB (eben das, was zugewiesen ist).
Betreibt man damit eben 17 oder 19 VMs am Host, sind ~20GB RAM, die die VMs wollen schlicht nicht vorhanden. So bleibt nur Platz für 12 VMs in 48GB. Oder man lebt mit extremen Leistungseinbußen.
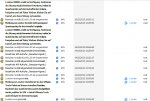
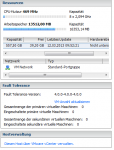
Siehe dazu das von mir gepostete Bild über mehrere 2008/2008R2 VMs bei mir auf der Arbeit. Realverbrauch zu 99% = zugewiesenem RAM.
Um das noch weiter auszubauen. Ich kenne auch das Verhalten von überbuchtem RAM bzw. zu knapp bemessenem RAM. Seinerzeit lagen unsere Hosts mit 4x64GB bei nem Realverbrauch von ~55-60GB pro Host. Inkl. greifender Sharing/Swapping/Balloningmechanismen. -> und inkl. teils grottig schlechter Performance.
Nun sind wir auf 4x144GB RAM. Der reine RAM Verbrauch selbst ist weit gestiegen, teils 10-15GB pro Host. Der Speed hat sich merklich gesteigert. Auch das Ansprechverhalten. Die HDD Last ist teils massiv gefallen. Ballooning/Swappingwerte nun = Null -> voller Speed, wie man es erwartet.
Wie ich eingangs schon erwähnte, virtualsierung ist nicht dafür da, den Host gnadenlos zu überbuchen, auch wenn es gehen würde. Sondern soll Ressourcen möglichst effizient ausnutzen. Beim RAM und auch beim Storage gibts aber eben einige Einschränkungen. Verbrauch = Verbrauch. Kann nichts verbraucht werden, weil nicht vorhanden -> schlechte Performance.
Und ja, das SIND! Prasixerfahrungen... Die man eben haben muss und erst bekommt, wenn man sowohl die eine, als auch die andere Theorieseite mal überhaupt gesehen hat.

")
 Denn sie gehen an jeglicher Praxis, ja sogar jeglicher Theorie vorbei.
Denn sie gehen an jeglicher Praxis, ja sogar jeglicher Theorie vorbei.