Sind meine Results zu gut um Tipps zu geben, oder mag der gute Herr einfach nicht auf mich reagieren?
Womöglich gab es wohl nichts zu kommentieren, oder einen Grund weswegen ich dir nicht auf die Nerven gehen wollte
Entweder machst du alles richtig, oder es war Hoffnungslos

Ich weiß es nicht
")
Gerade eben versucht bei deinem Profil auf "ältere Nachrichten anzeigen" zu gehen
Aber ich musste 9x darauf drücken um zu dem letzten Ryzen DDR5 post zu gelangen, worin die rede von
"Msi Tomahawk läuft & ich habe nicht besonders viel getestet, 7800 müsste gehen"
war
Diese Nachricht liegt 9-10 Seiten zurück
Zu postest einfach viel , haha.
Selbst wenn ich versuchen würde nachzuschauen was deine letzte Aktivität war ~ es ist hoffnungslos etwas zu finden
Positiv dass du soo sehr auf LUXX aktiv bist, aber für mich ~ ich weiß nicht, es gab bis jetzt keinen Grund "nachzuforschen".
auf einen meiner Posts reagiert, obwohl ich mir auch gerne Hilfe gewünscht hätte...
Kann eine Mischung aus "habe ich einfach nicht bemerkt" oder "überlesen" sein.
Ich bekomme @ mention pings selten.
Quotes kommen , pings eher selten. Aber ich denke das hat man schon bemerkt, worin/wenn ich meistens nur im Intel Thread aktiv bin
Bzw hier und da mal für eine Woche abseits des Forums bin
")
Erstes Bild auf maximale Bandwith gegangen,
Hiermit habe ich ein Problem,
Aber , wenn es für dich läuft ~ wieso sollte ich dir auf die Nerven gehen
Ich denke du könntest womöglich übersehen dass die potential Bandwidth andersseitig kommt und nicht durch timings hinuntersetzen.
Sondern eher dass die Distanz zwischen manchen Timings niedriger wurde. Nicht dass die fokussierten Timings selbst den Zugewinn bringen.
zb:
~ mit einem FAW unter 32 machst du dir die "amount of bits per transfer" hinüber. Typisches 4+4 IC UDIMM (per Seite), läuft auf 1KB pagefile size.
1KB Pagefile size ist immer FAW 32. Die RRD_X *4 regel gibt es nicht mehr, den der Ram wurde in 2 geteilt und die Rückseite von der Vorderseite isoliert.
~ Das selbe mit RRD_S++ , zwar haben wir 2x 32bit links pro channel (AMD müsste es genau so rennen wie Intel oder sie Teilen den Link irgendwo in der mitte /2)
Jedoch gehen Reads durch eine synchronization der Differentiellen Leitungen, sprich wie Ebbe und Flut zeigt sich durch das leichte bewegen nach vorne und hinten ~ die Datentransfer.
Bei dem Ebbe & Flut Beispiel, zeigt es die Gravitation bzw distanz zu dem Mond.
Durch das leichte hin und her bewegen der gebildeten VREF im DQ (Data Line) und DQS (Data Strobe Line) , werden Daten hin und her gesendet.
Weswegen das genaue trainieren auch so wichtig ist. Es sind 60 Rails welche synchronisiert werden müssen.
Zu dem Thema nochmal ~ den man sollte den Hintergrund verstehen.
Innerhalb des RAMs werden diese Signal Strobes im 16er Tackt ausgeführt (als Roundtrip)
Read BurstLength & Write Burstlength sind 16nCK (auf der DIMM Seite).
Burst chop, also der einseitige command, ist 8 nCK lang.
D.h, dass jeder Read nur ab 8 nCK geschehen kann.
Gleichgültig wie man den RAM Stick anspricht. Er kann nur im 8er Tackt arbeiten.
Somit es wenig Sinn macht wenn zwischen den Bankgroups, aka der Rd to Rd_Short jump, nur 4 clock lang ist.
Er wird immer in einer "pause" condition bleiben, oder er wird dadurch writes ignorieren, welche zwischen den Reads geschehen.
// natürlich würde es gehen, aber du hast bei jeder Aktion eine Reaktion ~ "you trade in something for this silly/spec-breaking change"
~ WTR_ (S)
Writes,
Writes geschehen immer zwischen den 8nCK reads.
Der erste write ist genau die hälfte davon bei 4nCK (genau mittig während ein read läuft) ~ da writes jederzeit geschehen dürfen und Zellen keine Spannung dadurch verlieren.
Jedoch der zweite aufeinanderfolgende write, geschieht dann nach 8nCK pause.
Sollte es kein RD (+WR), pause, RD ~ sein
Sondern ein Rd (+WR), pause, + WR
werden zwei aufeinanderfolgende Writes immer 12nCK brauchen, 4+8nCK.
Um sich kurz zu fassen,
Wr To Rd_Short (WTR_S) braucht 4nCK , aber _L absolutes minimum 12.
Im optimierten fall , 24.
Desweiteren gehen Writes nur auf 4nCK , da diese von der CPU gesteuert werden und ausgehen.
AMDs tBURST minimum liegt auf 3nCk , weswegen auch immer. Es kann sein dass das WTR_S minimum 3 ist (hier)
Reads jedoch können das nicht. Sie unterliegen dem RAM Stick limit , welches bei UDIMM 8nCK ist.
Wenn man sich die tRd 2 Wr (tRDWR) Formel anschaut, bleibt es
CAS-CWL+BL/2+OdtOnLat+WrPRE
2+8+1+2 (2 bis 4) ~ sprich 13 bis 15.
Mehr , verlangsamt wann Writes ausgeführt werden können und "kann" stabilität bringen.
Aber zuu viel , über 19-20 , wird zu einem Problem mit zu tiefen WTR_
Fast alle Timings können überlappen, und alle timings gehen in paaren von 2 oder 3.
Niemals ändert man nur einen Wert.
Memtest ist jedenfalls ohne Fehler durch. y-cruncher ebenfalls...
Y-cruncher component stress tester
Key 1 enter, 7 enter (all tests), 0 enter (start)
5 loops minimum aka 70min. 6 sind besser, 84min.
Y-cruncher (v0.8.2 old)
Wormhole lets you share files with end-to-end encryption and a link that automatically expires.

wormhole.app
^ 24h link
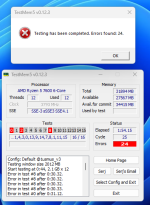
Weiß nicht warum das TM5 nicht richtig läuft... lief nur 10 Min., zwar ohne Error aber zu kurz. Was soll dieses Fenster? ich habe TM5 doch als Admin gestartet...
Anhang anzeigen 980260
Wenn ich Ok drücke, erscheint es sofort wieder. Nach dem xten klick kommt eine Fehlermeldung und TM5 schließt sich. Ich starte jetzt mal Memtest...
Du hast dir die configs genommen, jedoch nicht das TM5 frisch entpackt.
Das gesendete ist eine andere EXE mit einer anderen config.
Das Fenster muss pro kern auf "ok" bestätigt werden.
Bei dem nächsten Neustart erkennt es windows und läuft dann normal.
Sollte der TM5 timer laufen ohne dass die Tests fertigwerden (über 2min ohne Fortschritt)
Dann ist einer der Threads gecrasht.

.png")

.png")
")