Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Gute Idee, zumindest innerhalb von CPUs mit nur einem CCD, mit zwei CCDs biste wohl leider ausgeschlossen aus dem Game.. Wäre zumindest interessant weshalb das so ist, ich kann es technisch nicht nachvollziehen..
Wäre nicht Geekbench noch eine Alternative? Das schreit ja auch nach RAM-Performance!
Wenn Du diese Anzeige nicht sehen willst, registriere Dich und/oder logge Dich ein.
Muss man irgendwas spezielles beachten/einstellen für MaxxMem²? Irgendwie bekomme ich da nur unterirdische Werte raus, besonders bei Write?
Hab es auch auf zwei unterschiedlichen Windows 11 probiert.
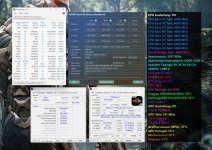
Ich fang mal an mit Geekbench 6, aber blende die Multicorewerte mal bewusst aus, da es ja garnix bringt.. Singlecore ist natürlich ebenso bescheiden, aber zumindest könnten sich die ganzen User mit einem 9800X3D etwas vergleichen.
Lest mal was Kelutrel dazu schreibt. Sehr Unwahrscheinlich daß sich die latezen ähnlich verhalten. Außer echte Werte mit Microbench Vergleichen.
Beitrag automatisch zusammengeführt:
DeepL:
Wenn der „Uncached RAM latency“-Wert, der vom RopBench angezeigt wird, nicht variiert, können Sie ziemlich sicher sein, dass die RAM-Leistung die gleiche ist und der AIDA64-Anstieg entweder auf eine AIDA64-Softwareänderung oder auf eine Änderung im Cache-Prädiktoren-Mikrocode zurückzuführen ist (Sicherheits-Mikrocode-Patches werden hier ignoriert). Da es mit einem neuen BIOS erschienen ist, tippe ich auf Letzteres.
Die normale RAM-Latenzzeit wird berechnet, indem man Millionen von zufälligen Bytes in einem ausreichend großen Speicherpuffer liest und dann den Durchschnitt der benötigten Zeit bildet. Früher ging man davon aus, dass die Auswirkungen der Zwischenspeicherung keine oder nur minimale Auswirkungen haben würden, wenn die Daten in zufälliger Reihenfolge und nur ein einziges Mal gelesen würden. Während das Tool dies tut, versuchen die internen Cache-Look-Ahead-Prädiktoren der CPU, die zu erwartenden folgenden Lesevorgänge vorherzusehen und zwischenzuspeichern, um die Latenzzeit zu verringern, und diese Prädiktoren basieren heutzutage auf neuronalen Netzen, so dass sie ziemlich schlau darin sind, Muster zu finden (ich hatte einige Kämpfe gegen sie, sie sind unglaublich schlau). Die Qualität des Zufallszahlengenerators, der den nächsten Leseort festlegt, hat also einen Einfluss, ebenso wie die Fähigkeit der Prädiktoren, das vage Muster abzuleiten, das der Zufallszahlengenerator möglicherweise verwendet, indem er sich seine Lesevorgänge ansieht. Ich vermute, dass mit dem neuen BIOS eine Änderung im Mikrocode in Bezug auf die Prädiktoren diese intelligenter gemacht hat und in der Lage ist, ein zufällig generiertes Muster zu erkennen und zu vermeiden, es zwischenzuspeichern, um eine Vergiftung des Cache mit nicht benötigte Daten, und dies kann wahrscheinlich die Leistung insgesamt verbessern, aber nicht in AIDA64, wo die sorgfältige Balance, die die Entwickler zwischen Puffergröße/rng/Prädiktoren gehalten haben, durch diese Änderung beeinträchtigt wurde und die Latenz als Folge davon stieg. Die „Uncached RAM latency“ in RopBench wird berechnet, indem der Cache und die Prädiktoren deaktiviert und aus der Gleichung entfernt werden, so dass sie einen stabileren Wert darstellt, der sich auf die IMC/Wartestate/Traces-Leistungen beschränkt.
Hab mal wieder 2h investiert und Geekbench 6 Singlecore 6400MT/s vs. 8000MT/s verglichen. Die Konditionen waren die selben wie bei meinem anderen Test die Tage:
Ich hab es mal nochmals probiert:
VDDIM Variation von 1,5-1,65V --> TM5 instant #6
VDDQ Variation von 1,35-145V --> ''
VDDG Variation bis 1,1V (VMISC auf 1,2V angehoben) --> ''
VDDIO war immer synchron zu VDDQ. Hab auch mal VDDIO bei 1,4V belassen, aber es scheint tRCD 36 ist bei mir nicht möglich. Alles unter 37 bekomme ich nicht stabil (Brickwall)
Was erfreulich ist das die 5600B ICs deutlich weniger Spannung benötigen als meine anderen Kits, die ich bisher getestet habe.
Ich versuche mich mal an 8000+ ob es mit dem diesem Kit gelingt, mal sehen...
Ja im Endeffekt machen RCD 36, 37 oder 38 kaum einen Unterschied, auch CL 28 oder 30 machen kaum was an Leistung aus, benötigen aber deutlich mehr Spannung.
Was ich aber gemerkt habe, das mein DR Setup mit CL32 leistungsstärker ist. Muss ich mal im Benchmark miteinander vergleichen.
Hi, kannst du eigentlich so lassen. Könntest tCL auf 30 & tRCD auf 38 probieren und tRFC auf 532 runter.
Sonst würde ich nix mehr ändern. Stabilität ist wichtiger als die letzten 0,005%
Ja im Endeffekt machen RCD 36, 37 oder 38 kaum einen Unterschied, auch CL 28 oder 30 machen kaum was an Leistung aus, benötigen aber deutlich mehr Spannung.
Was ich aber gemerkt habe, das mein DR Setup mit CL32 leistungsstärker ist. Muss ich mal im Benchmark miteinander vergleichen.
Hi, kannst du eigentlich so lassen. Könntest tCL auf 30 & tRCD auf 38 probieren und tRFC auf 532 runter.
Sonst würde ich nix mehr ändern. Stabilität ist wichtiger als die letzten 0,005%
Sind die Spannungen korrekt? Wenn ja, dann wird das mit CL28 nicht laufen in Verbindung mit RCD braucht man ~1,65V.
--> Probier doch mal CL30 & RCD+RP 38 (RAS+RC +2tCk höher) , das könnte funktionieren & am besten GDM off.
Ok, teste ich gleich. Muss mich mit dem MSI BIOS noch auseinander setzten. Habe bisher (seit ca Anfang 2000 mit dem ASUS A7V) immer auf ASUS Mainboards gesetzt. Jetzt wollte ich mal was anderes ausprobieren.
Check auch mal die im sheet die vdd vddq Spannungen vddq kann z.b min 60 mv lower als vdd. Bringt noch mehr stabi. Auch ist 1.35 v kein echter controller wert. 1.365 V ist zb. wo der controller z.b nicht intern korrigieren muss
Der Controller hat einen StepSize von 5mV im "normal" Mode & 10mV im "HVM".
Für den normal Mode lautet doch dann 5mV Step (+-5mV Correct Margin) für den Controller. Das wären dann 15mV Steps (15mV->30mV->...->1305mV->1320mV->1335mV->1350mV->1365mv->...1425mV)
Für den HV Mode sind es dann 10mV (+-10mV CM) also in Summe 30er Schritte. (->ab 1430->1460->1490->...->2070mV).
Dann wäre 1350mV ein echter Wert, der 1400mV Wert wäre hier nur im HV Mode ohne Korrektur seitens des PMIC umsetzbar?
Laut Asus ->127Steps * 5mV (VDDmin = 800mV --> VDDmax =1435mV)
für HVM -> 127Steps *10mV (VDDmin = 800mV --> VDDmax =2070mV)
Ich kann die 15er Steps mit aktueller AGESA bestätigen, ob das früher auch so war kann ich mich nicht mehr erinnern.
Auf meinem Asus schaut das so aus
1350 =1350
1355 = 1350
1360 = 1350
1365 = 1365
Ich kann die 15er Steps mit aktueller AGESA bestätigen, ob das früher auch so war kann ich mich nicht mehr erinnern.
Auf meinem Asus schaut das so aus
1350 =1350
1355 = 1350
1360 = 1350
1365 = 1365
Selbes habe ich auch mit HWInfo loggen können. Je nach dem wie stark die Input-Spannung ist, schwankt der Wert etwas, da der interne geschlossene Spannungskreis nachregelt.
Muss mir später mal noch im HVM die Spannungssteps genauer anschauen & das Regelverhalten.
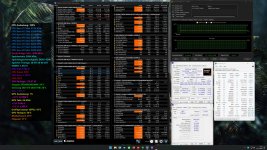
Puh, wer hätte dies gedacht ... Hier sind meine 6600-30 Werte mit dem 7950X. Heute hat mir der Postbote einen 7800X3D gebracht. Abends nochmal ganz kurz schaun, was der IF macht, usw. Packt mich der Übermut, boote ich einfach mal 1:1 die 6600-30, hau kurz das PBO Zeugs raus und schau was passiert ... Oha.

") Wäre zumindest interessant weshalb das so ist, ich kann es technisch nicht nachvollziehen..
Wäre zumindest interessant weshalb das so ist, ich kann es technisch nicht nachvollziehen..