Gen8 Runner
Experte
- Mitglied seit
- 12.08.2015
- Beiträge
- 1.165
Wieso Resilver? Ist ne Platte defekt? Würde erstmal einen Scrub laufen lassen und schauen, ob der alles richten kann.
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
")
 Dummerweise: helfen wollen/können sie mir auch nicht. Dabei will ich doch nur die ConnectX-4/5-Treiber aus dem SRU21...
Dummerweise: helfen wollen/können sie mir auch nicht. Dabei will ich doch nur die ConnectX-4/5-Treiber aus dem SRU21...Lustigerweise hab ich von einer Quelle die ich jetzt nicht genauer nennen will mal gehört, das es mit Geschäftskunden da auch nicht viel anders sein sollSelbst die verschiedenen Hotlines bei Oracle zeigen sich völlig plan- und hilflos. Die wollen mein Geld nicht.
.[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 10.8 GBytes 9.25 Gbits/sectruenas:/mnt/Datapool_on_TrueNAS/blub /blub_on_TrueNAS nfs noauto,user,bg,rw,_netdev,soft,timeo=60,x-gvfs-show| lokal | ZFS | ZFS+Intel | ZFS+Samsung | ||||||
|
|
|
|
| |||||
|
|
|
|
| |||||
|
|
|
|
| |||||
|
|
|
|
| |||||
|
|
|
|
| |||||
|
|
|
|
|
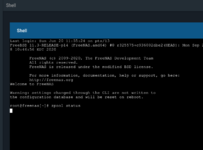
root@freenas[~]# zpool status
pool: data
state: UNAVAIL
status: One or more devices could not be opened. There are insufficient
replicas for the pool to continue functioning.
action: Attach the missing device and online it using 'zpool online'.
see: http://illumos.org/msg/ZFS-8000-3C
scan: none requested
config:
NAME STATE READ WRITE CKSUM
data UNAVAIL 0 0 0
raidz2-0 UNAVAIL 0 0 0
1626352819212922408 UNAVAIL 0 0 0 was /dev/gptid/5168a444-cacf-11eb-891f-133dff369a55.eli
2252268794190276348 UNAVAIL 0 0 0 was /dev/gptid/9155711b-6596-11eb-a75c-8f89b0c061c4.eli
13032312712921767360 UNAVAIL 0 0 0 was /dev/gptid/86b9fa2f-6596-11eb-a75c-8f89b0c061c4.eli
15819523336493928030 UNAVAIL 0 0 0 was /dev/gptid/9285ff04-6596-11eb-a75c-8f89b0c061c4.eli
38866582036668272 UNAVAIL 0 0 0 was /dev/gptid/9411f31f-6596-11eb-a75c-8f89b0c061c4.eli
spare-5 UNAVAIL 0 0 0
12219767935346166654 UNAVAIL 0 0 0 was /dev/gptid/9b4a1344-6596-11eb-a75c-8f89b0c061c4.eli
336223762456561297 UNAVAIL 0 0 0 was /dev/gptid/0cea51b3-6caf-11eb-aa19-19444082b40a.eli
12490430271123041723 UNAVAIL 0 0 0 was /dev/gptid/aab972e4-6596-11eb-a75c-8f89b0c061c4.eli
15244943219702717528 UNAVAIL 0 0 0 was /dev/gptid/ae626c03-6596-11eb-a75c-8f89b0c061c4.eli
logs
12893365534936794026 UNAVAIL 0 0 0 was /dev/gptid/080a5406-7e88-11eb-bffa-b95a0a9e4218.eli
pool: freenas-boot
state: ONLINE
scan: none requested
config:
Nene, das sind CMR Platten, ne SMR ist kürzlich rausgeflogen, deswegen muss die ersetzt werden, daher muss ich mal zuende resilvern.Sind das SMR Platten?
Warning: settings changed through the CLI are not written to
the configuration database and will be reset on reboot.
root@freenas[~]# zpool status data
pool: data
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Sun Jun 20 10:54:34 2021
11.7T scanned at 38.2G/s, 73.2G issued at 238M/s, 16.6T total
5.37M resilvered, 0.43% done, 20:11:27 to go
config:
NAME STATE READ WRITE CKSUM
data DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gptid/5168a444-cacf-11eb-891f-133dff369a55.eli ONLINE 0 0 797 (resilvering)
gptid/9155711b-6596-11eb-a75c-8f89b0c061c4.eli ONLINE 0 0 187 (resilvering)
gptid/86b9fa2f-6596-11eb-a75c-8f89b0c061c4.eli ONLINE 0 0 120 (resilvering)
gptid/9285ff04-6596-11eb-a75c-8f89b0c061c4.eli ONLINE 0 0 163 (resilvering)
gptid/9411f31f-6596-11eb-a75c-8f89b0c061c4.eli ONLINE 0 0 797 (resilvering)
spare-5 DEGRADED 0 0 279
gptid/9b4a1344-6596-11eb-a75c-8f89b0c061c4.eli ONLINE 0 0 0 (resilvering)
336223762456561297 UNAVAIL 0 0 0 was /dev/gptid/0cea51b3-6caf-11eb-aa19-19444082b40a.eli
gptid/aab972e4-6596-11eb-a75c-8f89b0c061c4.eli ONLINE 0 0 169 (resilvering)
gptid/ae626c03-6596-11eb-a75c-8f89b0c0
Bei einem Raid 6 dürfen dir halt 2 Platten pro vdev ausfallen, bei einem Raid 10 (mit 2 Platten pro vdev) halt nur eine.da wäre Redundanz dann deutlich schneller hergestellt, aber da ist die Frage ob da RAID 6, bzw. RAID 10 dann besser wäre.

Hey ich grüße dich.Ich finde dein EPYC-8DT nicht bei Asrockrack... Buchstabendreher?
Ausgehend von Supermicro pflegen hoffentlich alle Server-Produzenten mehr oder minder umfangreiche Kompatibilitätslisten. Einfach irgendwas zu installieren, wird eher nicht zuverlässig funktionieren und als Bonbon kommt noch PCI/PCIe-Passthru hinzu. Das war, ist und bleibt pingelig. Während reine HBAs fast immer ohne Probleme laufen, sieht es mit anderer HW eher durchwachsen aus. Hat deine System-Config noch jmd mit FreeNAS etc fehlerfrei (soweit bekannt) im Einsatz oder bist du der Drölffzigste, der mit Problemen kämpft und sich an einer Lösung versucht?

"altes" Setup, also ASRock Rack X470D4U mit Ryzen 2700X, LSI HBA und ConnectX Mellanox 2 Karte und 128GB ECC RAM.
Den HBA reiche ich aktuell wieder an meine FreeNAS Maschine durch (Ist glaube ich eh besser so, da die Stromsparmechanismen in BSD eh nicht so prickelnd sind).
") ....
....